





本文信息本文由方法SEO顾问发表于2016-08-1719:13:22,共 3048 字,转载请注明:【亲测好用!】python实现批量百度云批量转存工具_【方法SEO顾问】,如果我网站的文章对你有所帮助的话,来百度口碑给个好评呗!
【亲测好用!】python实现批量
前面介绍了一款百度云批量转存工具(见《》),因为涉及到软件获取cookies,而一旦cookies泄漏,将会造成个人隐私泄漏,于是自己用python又写了一个小程序来实现上面软件的功能,分享给大家。
照例先来上个图:
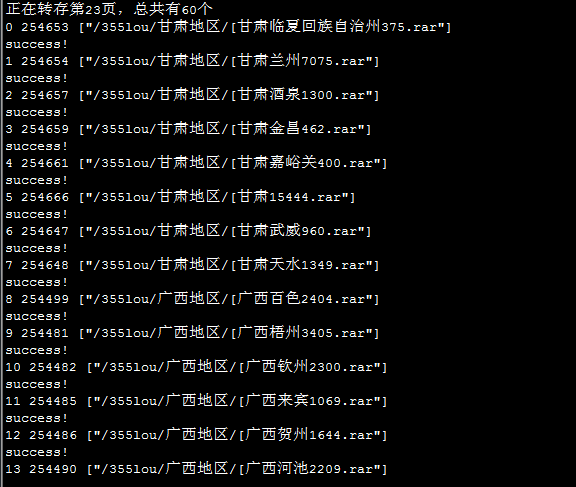
下面是程序源码:
#!/usr/local/bin/python
# -*- coding:utf-8 -*-
#Date:2016.8.17
#Author:Fangfa@seofangfa.com
#作用:一键转存别人的百度云文件
import requests,time,random,json,StringIO,datetime,re,threading,urllib,Queue
import os
import codecs#为了生成gbk编码的文件
today = datetime.date.today()
import codecs#为了生成gbk编码的文件
import sys
import math
reload(sys)
sys.setdefaultencoding('utf-8')
########下面是必填的5个参数,具体获取方法以后会有详细的教程,参数填写好了以后直接运行程序就好了
bduss = ''####详细见文章底部的图。打开chrome,登录帐号,按F12打开开发者工具,切换到network找一个动态请求地址,在RequestHeaders里找Cookie
stoken = ''####同上
bdstoken = ''####同上
uk = ''####你要转存的人的uk,如https://yun.baidu.com/share/home?uk=154024822,uk即为154024822
path = '/'####你在存在哪个文件夹里,需要提前创建好文件夹,也可以写/全部保存在根目录
##############公共的header
headers = {
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate, sdch, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'no-cache',
'Connection':'keep-alive',
'Cookie':'BDUSS=%s;STOKEN=%s;'%(bduss,stoken),
'DNT':'1',
'Host':'yun.baidu.com',
'Pragma':'no-cache',
'Referer':'https://yun.baidu.com/share/home',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36',
'X-Requested-With':'XMLHttpRequest',
}
###批量转存的函数
def zhuanCun(filelist,path,shareid,uk,bdstoken,headers):
payload={
'filelist':filelist,
'path':path,
}
r = requests.post("https://yun.baidu.com/share/transfer?shareid=%s&from=%s&bdstoken=%s&channel=chunlei&web=1&app_id=250528&logid=MTQ3MTQxNDgyNTU0NjAuNzEzODExNTI5MjY3NjMx&clienttype=0"%(shareid,uk,bdstoken),headers=headers,data=payload)
html = r.content
# print html
if '"errno":12' in html:
print "file exit!"
elif '"errno":0' in html:
print "success!"
else:
print html
########获取分享的总数及总页数
payload = {
't':'1471410879156',
'category':'0',
'auth_type':'1',
'request_location':'share_home',
'start':'0',
'limit':'60',
'query_uk':uk,
'channel':'chunlei',
'clienttype':'0',
'web':'1',
}
r = requests.get("https://yun.baidu.com/pcloud/feed/getsharelist",headers=headers,params=payload)
html = r.content
# print html
jsons = json.loads(html)
# print type(jsons)
totalCount = jsons['total_count']
print "总共有%s个分享的文件"%(totalCount)
page = int(math.ceil(totalCount/60.0))
print "共有%s页"%(page)
for c in range(page):
start = 60*c
payload = {
't':'1471410879156',
'category':'0',
'auth_type':'1',
'request_location':'share_home',
'start':start,
'limit':'60',
'query_uk':uk,
'channel':'chunlei',
'clienttype':'0',
'web':'1',
}
r = requests.get("https://yun.baidu.com/pcloud/feed/getsharelist",headers=headers,params=payload)
html = r.content
jsons = json.loads(html)
count = len(jsons['records'])
print "正在转存第%s页,总共有%s个"%(c+1,count)
allFile = []
for i in range(count):
shareid = jsons['records'][i]['shareid']
filelist = '["%s"]'%(urllib.unquote(str(jsons['records'][i]['filelist'][0]['path'])).decode('utf-8').encode('utf8'))
allFile.append("%s,%s"%(shareid,filelist))
print i,shareid,filelist
zhuanCun(filelist,path,shareid,uk,bdstoken,headers)
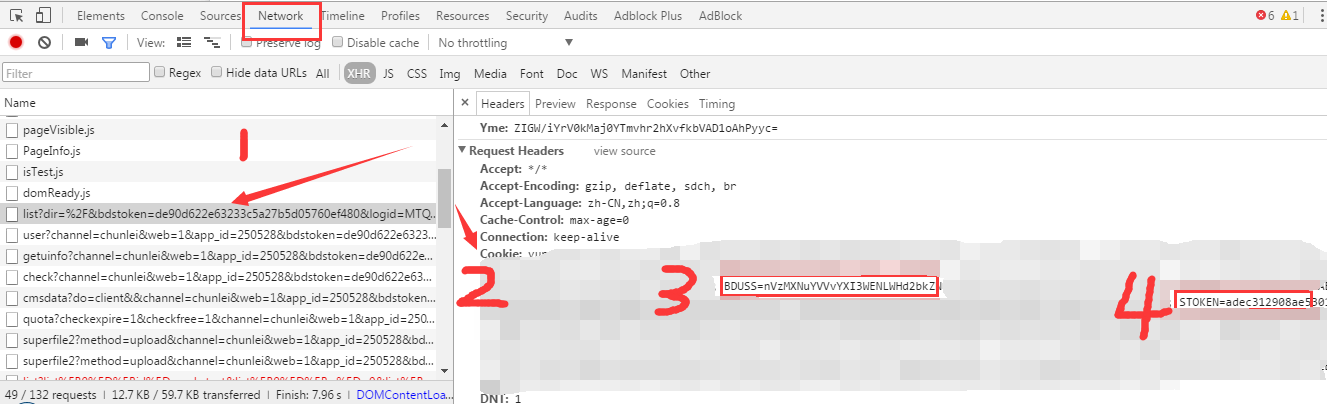
BDUSS、STOKEN、BDSTOKEN获取
####详细见文章底部的图。打开chrome,登录帐号,按F12打开开发者工具,切换到network找一个动态请求地址,在RequestHeaders里找Cookie
两张图说明一切:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









