








-
作者: Abhinav Rajvanshi, Karan Sikka, Xiao Lin, Bhoram Lee, Han-Pang Chiu, Alvaro Velasquez
-
单位:SRI国际,科罗拉多大学博尔德分校,DARPA
-
论文链接:SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments(https://ojs.aaai.org/index.php/ICAPS/article/download/31506/33666)
-
代码链接:https://www.sri.com/ics/computer-vision/saynav
主要贡献
-
论文提出基于LLM的高层规划器SayNav,首个专门用于大规模未知环境中的导航任务的高层规划器。该LLM规划器在导航过程中动态生成逐步指令。
-
提出在探索过程中逐步构建和扩展3D场景图机制。LLM根据选定的场景图子图生成下一步计划,部分场景图也在导航过程中不断被LLM细化和更新。SayNav在导航过程中动态生成逐步指令,并根据新感知的信息不断细化未来步骤。
-
SayNav仅通过上下文学习(in-context learning)需要少量示例来配置LLMs,以进行复杂的多目标导航任务。LLM生成的计划由预训练的低层规划器执行,将每个计划步骤视为短距离点目标导航子任务。
-
引入了跨Room的多目标导航(MultiON)任务基准数据集,供研究人员评估和未来使用。
研究背景
研究问题
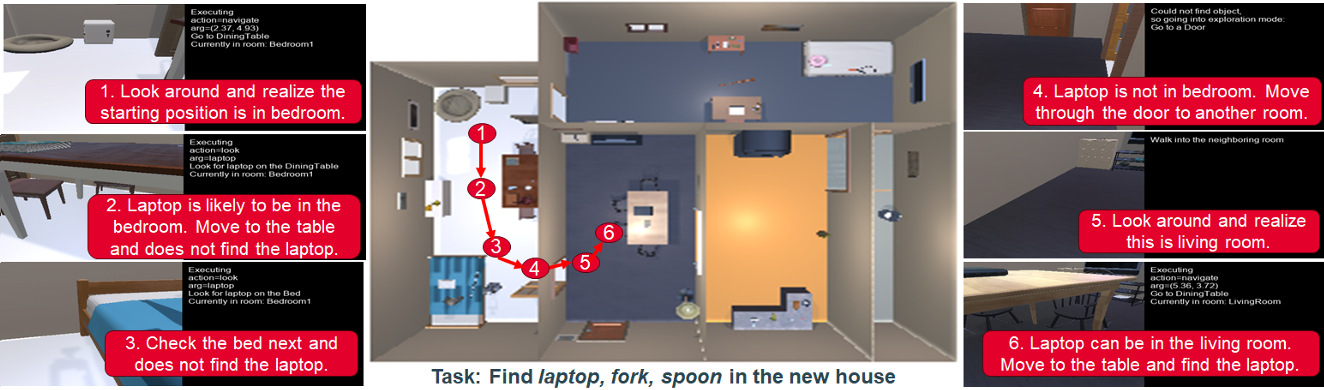
论文主要解决的问题是如何在未知的大规模环境中进行复杂的导航任务,特别是多目标导航(Multi-Object Navigation, MultiON),即如何让智能体在新环境中高效地搜索多个不同的物体。
研究难点
该问题的研究难点包括:
-
当前基于深度强化学习(DRL)的方法需要大量的训练数据才能在新环境中达到合理的性能;
-
这些方法还需要大量的计算资源来复制人类在大规模环境中泛化的能力。
相关工作
该问题的研究相关工作有:基于视觉导航的未知环境、使用大型语言模型(LLMs)进行高层次规划以及多目标导航(MultiON)。
现有的学习方法通常依赖于大规模的训练数据和计算资源,而LLMs在零样本或少样本学习方面显示出显著的能力。
研究方法
论文提出了SayNav,一种利用大型语言模型(LLMs)进行高效导航的新方法。
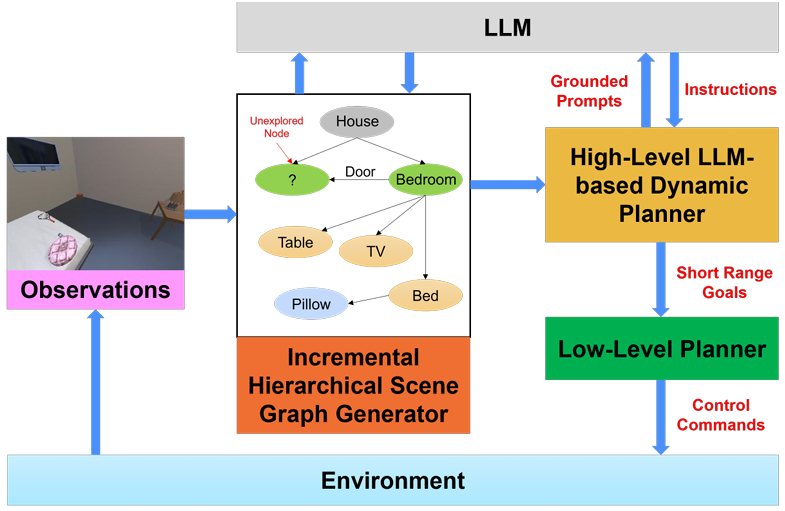
增量场景图生成
SayNav通过感知信息逐步构建和扩展环境的3D场景图。场景图是一种分层图,表示多个抽象层次的空间概念及其关系。
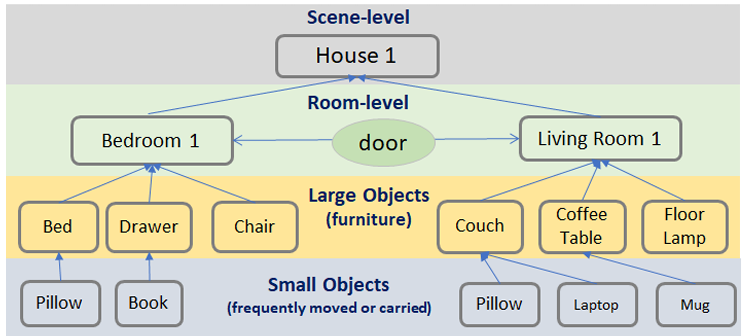
每个对象节点与其3D坐标相关联,房间节点与其边界相关联。门被视为两个房间之间的边,也有一个相关的3D坐标。
高层次LLM动态规划器
SayNav利用LLMs动态生成短期高层次计划。具体步骤如下:
-
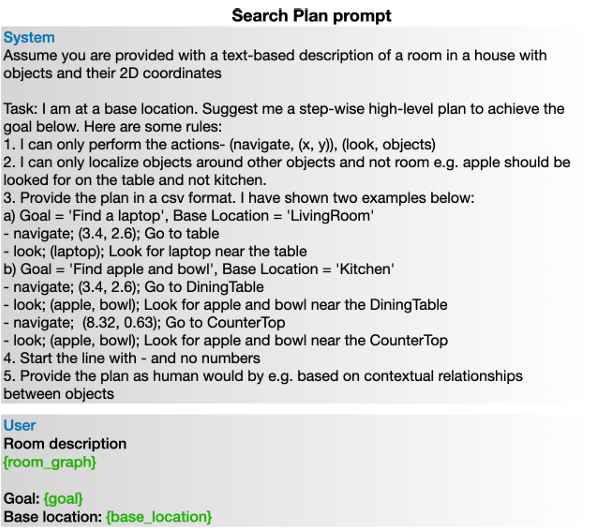
从完整的3D场景图中提取子图,并将其转换为文本提示输入到LLMs中。
-
LLM基于子图生成短期步骤指令,例如推断目标物体的可能位置并优先处理。
-
计划还包括条件语句和回退选项,以便在某个步骤无法实现目标时进行调整。
低层规划器
SayNav将每个LLM规划的步骤转换为一系列控制命令以供执行。
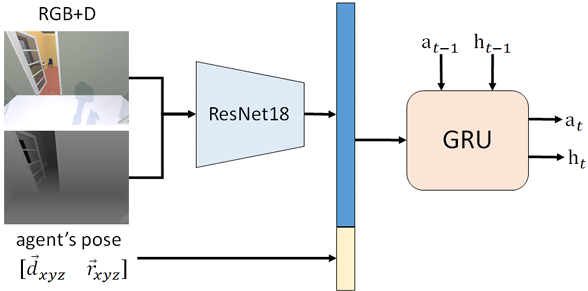
低层规划器将每个LLM规划的步骤视为短距离点目标导航(POINTNAV)子任务。
LLM生成的高层计划被分解为简单的子任务,低层规划器可以成功执行。
实验设计
数据集
实验使用了ProcTHOR框架生成的数据集,包含132个不同房屋的132个episode,每个房屋有3到10个房间,每个episode选择3个目标物体。
评估指标
主要评估指标包括:
-
成功率(Success Rate, SR),
-
按路径长度加权的成功率(SPL),
-
肯德尔tau距离(Kendall Tau),用于衡量智能体与真实顺序的相似性。
实验设置
实验使用了两种LLMs:gpt-3.5-turbo和gpt-4。低层规划器使用DAGGER算法进行训练,从2800个episode中学习短距离导航技能。
基线模型
现有基于LLM的机器人导航方法多适用于已知或小规模环境。相比之下,RL/IL(如Gireesh等,2023)和SLAM方法能在更广泛的设置中应用。研究表明,RL/IL的PointNav在未知环境中优于SLAM(Savva等,2019)。
鉴于缺乏开源资源,论文构建了一个基于IL的PointNav基线智能体,以评估学习型智能体的性能上限。该智能体利用目标顺序和真实坐标两种额外信息,简化了任务至一系列PointNav任务,以导航至目标点。
结果与分析
定量结果
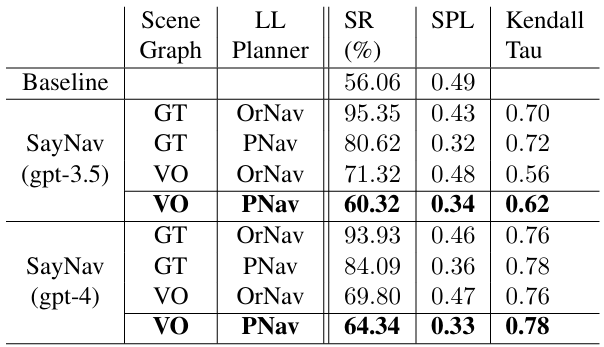
SayNav在不使用任何真实信息的情况下,成功率达到了60.32%(gpt-3.5-turbo)和64.34%(gpt-4),优于基于真实信息的基线方法(56.06%)。尽管基线方法使用了最优目标和真实坐标,但SayNav仍然表现出色。
定性结果

SayNav能够在未知环境中高效地搜索多个不同的物体。例如,在一个典型的episode中,智能体从厨房开始,通过客厅找到笔记本电脑和手机,最终在第9个房间找到闹钟。
记忆机制
通过LLM实现的记忆机制在gpt-4上表现良好,表明更好的LLMs可以接管跟踪任务。
不足与讨论

本研究的场景图生成面临多项挑战,上图展示了视觉观察导致的失败案例。由于智能体无法打开门,只能通过开启的门进入其他房间。然而,智能体常无法识别门的开启状态,导致任务失败。
为改善此问题,论文提出一种机制,通过近距离观察、多角度验证及深度信息比较来核实门的开闭状态。
未来工作将开发验证机制以优化LLM生成的计划,并探索适用于实际机器人的小型LLM。
总结
论文提出了SayNav,通过增量构建和扩展3D场景图,并利用LLMs生成动态且上下文适当的高层计划,实现了在大规模未知环境中的复杂导航任务。
实验结果表明,SayNav在成功率上优于基于真实信息的基线方法,展示了其在未知环境中的强大导航能力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









