









-
作者:Carmelo Sferrazza, Dun-Ming Huang, Xingyu Lin, Youngwoon Lee, Pieter Abbeel
-
单位:加州大学伯克利分校,延世大学
-
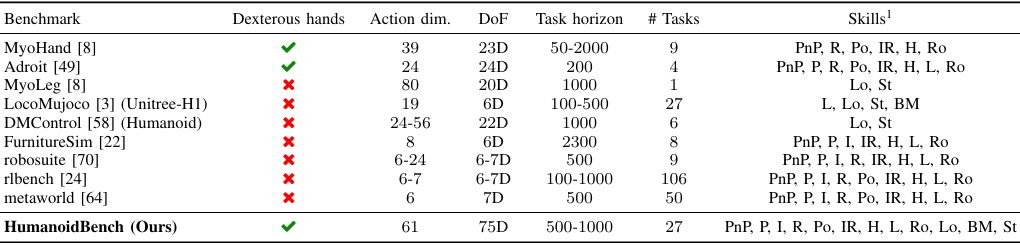
标题:HumanoidBench: Simulated Humanoid Benchmark for Whole-Body Locomotion and Manipulation
-
原文链接:https://arxiv.org/pdf/2403.10506
-
项目主页: https://humanoid-bench.github.io/
-
代码链接: https://github.com/carlosferrazza/humanoid-bench
主要贡献
-
论文介绍了HumanoidBench,第一个包含多种全身操作和运动任务的高维模拟机器人基准测试,提供了多样化的任务集,涵盖了从简单的玩具示例到实际应用场景的广泛挑战。
-
该基准测试旨在解决复杂的全身协调任务,这些任务需要机器人在多个身体部位之间进行精细的协调。通过模拟具有灵巧手的人形机器人,HumanoidBench展示了在真实世界中实现人类级任务的潜力。
-
通过提供一个快速、安全且低成本的测试平台,HumanoidBench加速了机器人学习算法的研究。它支持通用的控制器结构,包括学习和基于模型的方法,促进了算法的验证和创新。
-
展示了如何使用分层强化学习(HRL)来解决复杂的任务。通过将低层次技能(如站立、行走)与高层次任务相结合,HRL方法在某些任务上取得了更好的性能,表明了在人形机器人中应用结构化学习方法的重要性。
研究背景

研究问题
论文主要解决的问题是如何加速仿人机器人算法的研究。
尽管仿人机器人在硬件上取得了显著进展,但其控制器通常是为特定任务手工设计的,缺乏全身控制能力。
为了解决这一问题,论文提出了HumanoidBench,一个高维的模拟机器人学习基准。
研究难点
该问题的研究难点包括:
-
复杂动态的机器人控制、身体各部分之间的精细协调以及长时复杂任务的处理。
-
现有的强化学习算法在大多数任务上表现不佳,特别是在需要高维和长时间规划的任务中。
相关工作
- 深度强化学习:
-
随着标准化模拟基准的出现,如Atari和连续控制基准,深度强化学习在机器人领域取得了显著进展。这些基准帮助研究人员在模拟环境中开发和评估算法。
-
为了应对长视距规划和复杂动作空间带来的挑战,HRL被提出来,通过在强化学习范式中解耦低层次和高层次规划来简化学习问题。
-
- 机器人操纵模拟环境:
-
现有的模拟环境主要集中在准静态、短视距的技能上,如抓取和放置、手持操作和拧螺丝等任务。尽管如此,这些环境通常局限于单一手臂的操作设置,缺乏对多身体部位协调的挑战。
-
一些研究引入了更复杂的操纵任务,如块堆叠、厨房任务和桌面操作。然而,这些任务仍然主要集中在推、抓取和放置的组合上,缺乏对多任务和长视距目标的关注。
-
IKEA家具组装环境、BEHAVIOR和Habitat等基准测试引入了多样化的长视距(移动)操纵任务,主要关注通过抽象复杂的低层次控制问题来进行高层次规划。
-
Robosuite和其他研究引入了双臂操纵任务,但大多数研究仍集中在单臂或非附着于任何臂基的双浮动机器人手上。
-
- 人形机器人运动控制:
-
在人形机器人研究中,大多数基准测试集中在运动控制挑战上。这些模拟加速了对控制算法的研究,并最终实现了在现实世界中的鲁棒人形运动。
-
最近的工作扩展了人形模拟到不同的领域,涉及一定程度的操纵,如网球、足球、球类操作和接球以及箱子搬运。然而,这些工作大多集中在展示特定任务上的方法,缺乏任务多样性。
-
人形机器人仿真环境
-
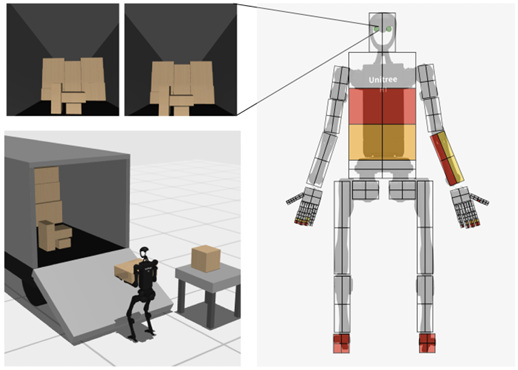
模拟环境概述:
-
使用MuJoCo物理引擎来模拟人形机器人,特别是Unitree H1人形机器人及其配备的两个灵巧的Shadow Hands。
-
提供了多种机器人模型,包括Unitree H1、Unitree G13和Agility Robotics Digit4,以适应不同的研究和应用需求。
-
-
人形机器人模型:
-
主要使用Unitree H1作为基准模型,因为它是一个全尺寸的人形机器人,相比更小的Unitree G1,学习速度更快。
-
在模拟中移除了Shadow Hands的笨重前臂,以使其更接近未来人形机器人的发展趋势。
-
-
灵巧手模型:
-
使用两个灵巧的Shadow Hands,这些手在模拟和现实世界中都表现出色。
-
提供了Robotiq 2F-85平行爪和Unitree 13自由度手的模型,以增加环境的灵活性。
-
-
观察空间:
-
观察空间包括机器人的本体状态(关节角度和速度)以及任务相关的环境观察(物体位置和速度)。
-
支持自上而下的视觉观察和全身触觉感知,触觉传感器分布在机器人全身,共有448个触觉单元。
-
-
动作空间:
-
机器人通过位置控制进行控制,动作空间为61维,包括两个手。
-
动作控制频率为50Hz,位置控制通常比扭矩控制更稳定。
-
-
设计选择:
-
环境设计考虑了高维动作空间和DoFs,以模拟复杂的全身协调任务。
-
通过减少环境观察的复杂性,专注于状态基础的设置,以便在不同任务之间最小化领域知识。
-
HumanoidBench
-
基准测试目标:
-
HumanoidBench旨在通过模拟人形机器人来推动机器人学习和控制算法的发展。
-
它提供了一个高维动作空间(最多61个执行器),用于研究复杂的全身协调。
-
-
任务集:
-
该基准测试包括27个任务,分为12个运动任务和15个操作任务。
-
运动任务涵盖各种交互和难度,如行走、站立、跑步、跨越障碍物等。
-
操作任务涉及多种互动,如卸载包裹、擦拭窗户、抓取篮球等。
-
运动任务
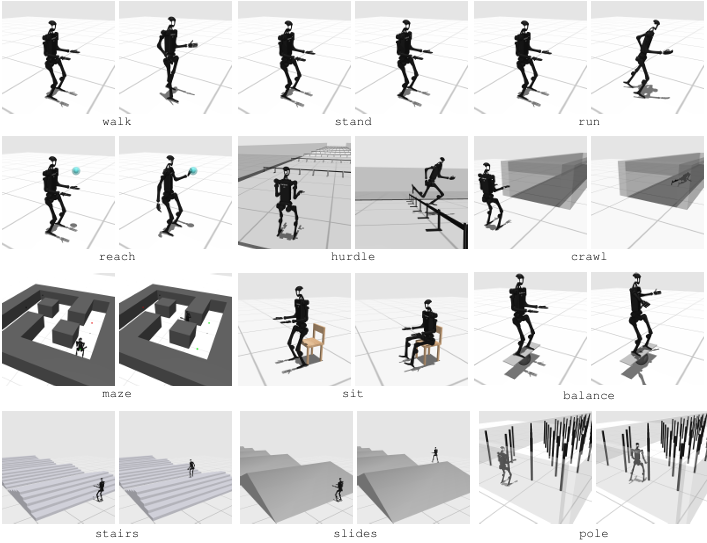
运动任务专注于评估人形机器人的运动能力和动态平衡。
这些任务通常不需要使用机器人的手部进行操作,而是侧重于机器人的行走、奔跑、跳跃等基本运动技能。具体任务包括:
-
walk:保持前进速度接近1米/秒,避免摔倒。
-
stand:在整个给定时间内保持站立姿势。
-
run:以5米/秒的速度向前跑。
-
reach:用左手到达随机初始化的三维点。
-
hurdle:在成功跨越障碍物的同时保持接近5米/秒的前进速度。
-
crawl:在隧道内保持接近1米/秒的前进速度。
-
maze:在迷宫中找到目标位置,通过多次转弯。
-
sit:坐到机器人后方靠近的椅子上。
-
balance:在不稳定板上保持平衡。
-
stair:以1米/秒的速度上下楼梯。
-
slide:在上下滑动的滑梯上以1米/秒的速度行走。
-
pole:在密集的高杆中前进,不碰撞高杆。
全身操作任务

全身操作任务则更注重评估人形机器人的复杂操作能力,通常涉及使用机器人的手部和全身协调来完成特定的操作任务。
这些任务要求机器人在操作过程中进行精细的手眼协调和全身动作协调。具体任务包括:
-
push:将盒子移动到桌子上的随机三维点。
-
cabinet:打开四种不同类型的橱柜门。
-
highbar:在保持连接的同时,从水平位置摆动到垂直倒立位置。
-
door:拉动并穿过门,同时保持门打开。
-
truck:从卡车上卸下包裹并将其移动到平台上。
-
cube:在手中操作两个立方体,直到它们都达到随机初始化的目标方向。
-
bookshelf:按顺序在书架上取放多个物品。
-
basketball:接住来自随机方向的球并将其投入篮筐。
-
window:抓住窗户擦拭工具并保持其尖端平行于窗户。
-
spoon:抓住勺子并使用它在锅内跟随圆形图案。
-
kitchen:在厨房环境中执行一系列动作,如打开微波炉门、移动水壶、转动燃烧器和灯开关。
-
package:将盒子移动到随机初始化的目标位置。
-
powerlift:举起指定质量的杠铃。
-
room:在5米乘5米的空间中,布置随机散布的物体,使其位置方差最小。
-
insert:将矩形块的末端插入目标块中。
基准测试结果
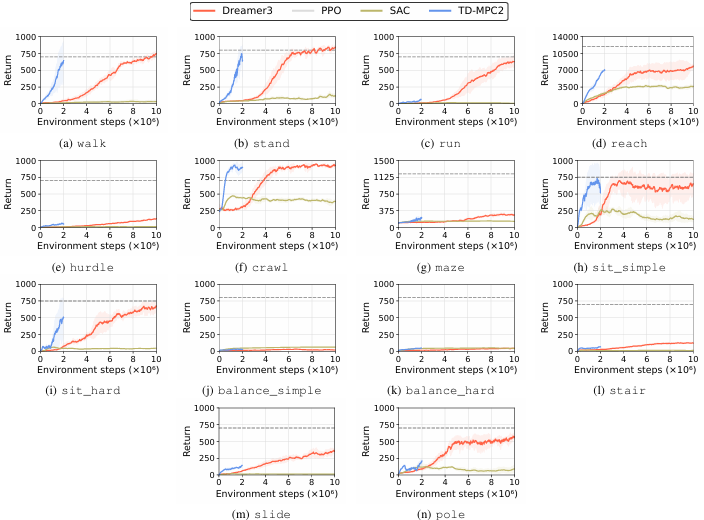
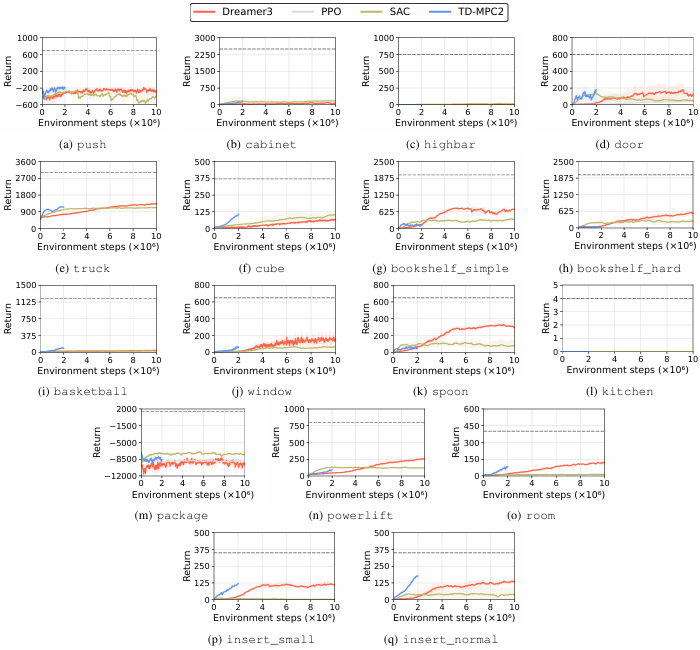
- 基线算法表现:
-
论文使用了四种RL算法(DreamerV3、TD-MPC2、SAC、PPO)对HumanoidBench中的任务进行评估。
-
结果表明,即使是状态空间和动作空间较小的简单任务,如行走(walk),这些算法也需要大量的训练步数才能达到成功标准。
-
反映了算法在处理高维状态和动作空间时的困难。
-
-
任务难度:
-
大多数基线算法在需要长视距规划和复杂全身协调的任务上表现不佳。
-
这些任务通常涉及多个身体部位的协调,如行走、跳跃、跨越障碍物等。
-
在操作任务中,算法的表现尤为糟糕,因为它们需要在学习任何操作技能之前先学会平衡和移动。
-
-
手部的影响:
-
控制带有灵巧手的人形机器人更具挑战性,因为手部的额外自由度和复杂性增加了任务难度。
-
通过比较有无手部的情况,发现手部的存在显著降低了算法的性能。
-
表明手部的自由度和复杂性对算法的学习效率有显著影响。
-
-
动作空间维度的影响:
-
通过减少动作空间的维度(例如,固定手部动作)来验证算法性能下降是否由动作空间维度增加引起。
-
结果表明,减少动作空间维度后,算法的学习速度显著提高,这确认了动作空间维度是影响性能的一个重要因素。
-
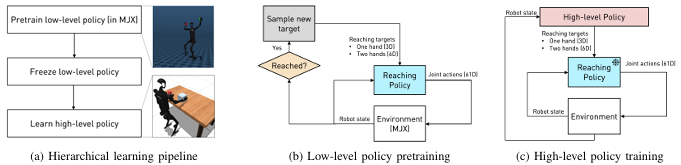
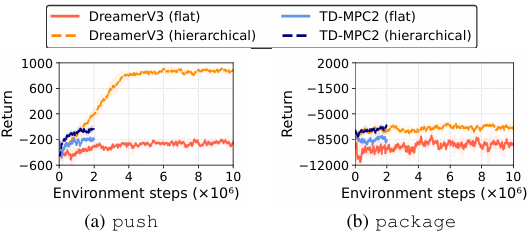
- 分层强化学习(HRL)的应用:
-
提出了一种分层强化学习方法,通过引入低层次技能策略来辅助高层次任务的学习。
-
在某些任务上,HRL方法显著优于端到端的基线算法。
-
例如,在push任务中,HRL方法实现了更高的成功率,表明在处理复杂任务时,结构化的学习方法可能更为有效。
-
- 常见失败案例:
-
论文还讨论了一些常见的失败模式。例如,在highbar任务中,机器人保守地学习保持与杆的接触以避免终止,但在执行全身旋转轨迹时遇到困难。
-
反映了短视距规划和长视距目标之间的挑战。
-
在door任务中,机器人在拉动门时遇到困难,因为它需要协调多个身体部位的动作,表明在操作和运动技能之间进行无缝交互是一个常见的挑战。
-

总结
-
论文提出了HumanoidBench,一个高维的仿人机器人控制基准,旨在加速仿人机器人算法的研究。
-
HumanoidBench包含27个任务,涵盖从简单的到复杂的全身协调和控制。
-
实验结果表明,现有的强化学习算法在大多数任务上表现不佳,而分层强化学习方法在复杂任务中表现出色。
-
未来工作将包括多模态高维观测的引入和更现实的对象和环境。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









