








-
作者:Zhonghan Zhao, Shengyu Hao, Wenhao Chai, Shidong Cao, Xuan Wang, Tian Ye, Boyi Li, and Gaoang Wang
-
单位:浙江大学,华盛顿大学,香港科技大学
-
标题:See and Think: Embodied Agent in Virtual Environment
-
原文链接:https://arxiv.org/pdf/2311.15209
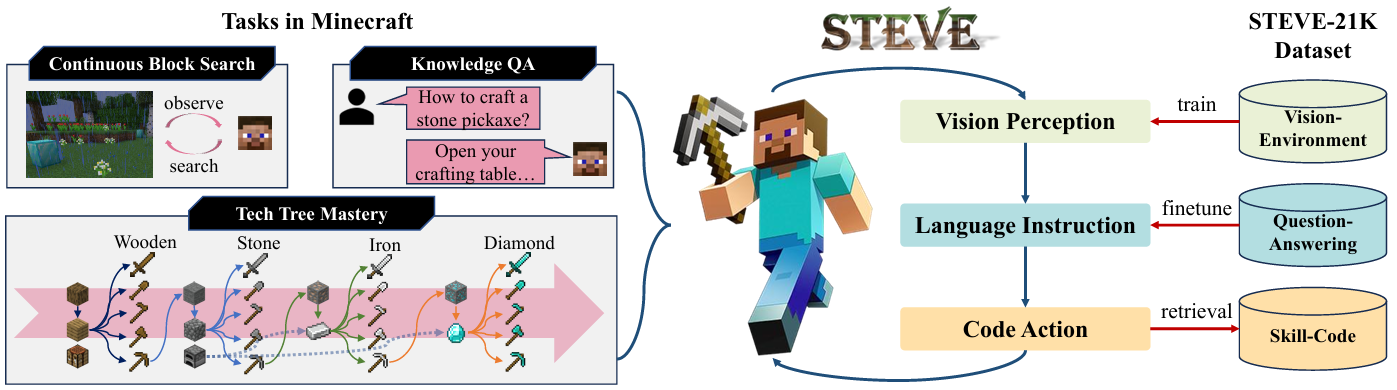
主要贡献
-
论文提出了虚拟环境中的具身智能体框架STEVE,结合了视觉感知、语言指令和代码动作三个关键组件,能够在开放世界环境中实现智能行为和适应性。
-
STEVE在关键技术任务上表现出色,比之前的SOTA方法在解锁关键技术树方面快1.5倍,在块搜索任务中快2.3倍。
-
收集了数据集STEVE-21K,包括600多个视觉-环境对、20K个知识问答对和200多个技能-代码对,用于验证STEVE的有效性。
-
介绍了通过微调从Llama-2-7B/13B获得的一系列大模型(STEVE-7B/13B),这些模型专门针对Minecraft内容进行了优化,以增强其在特定领域的表现。
研究背景
研究问题
论文主要解决的问题是如何在虚拟环境中构建一个能够自主行动的多模态具身智能体。
具体来说,研究如何在Minecraft这样的开放世界中,利用大模型(LLMs)和视觉感知来提升智能体的智能行为和适应性。
研究难点:
- 多模态输入的整合:
-
在开放世界环境中,智能体需要处理来自多种模态(如视觉和文本)的输入。
-
传统的基于文本的交互方式在处理视觉信息时存在局限性,尤其是在需要精确和快速反应的场景中。
-
如何有效地整合视觉和语言信息,以实现对环境的全面理解和互动,是一个重要的研究难点。
-
- 自主性和自适应性:
-
设计能够自主驱动和自适应的智能体是一个挑战。
-
智能体需要在没有详尽指令的情况下,自行制定和实施策略和行动。
-
这要求智能体具备强大的推理和决策能力,以应对复杂多变的环境和任务。
-
- 复杂任务的执行:
-
在开放世界环境中,智能体需要执行各种复杂的任务,如制作工具、探索环境和解决问题。这些任务通常需要多层次的技能和策略。
-
如何将这些复杂的任务分解为可执行的步骤,并确保智能体能够有效地完成这些任务,是一个关键的研究难点。
-
相关工作
-
智能体在Minecraft中的应用:
-
背景:Minecraft作为一个开放式的沙盒游戏,被广泛用于测试智能体的性能。智能体需要在游戏中自主执行各种任务,如砍树、制作工具和挖掘钻石。
-
早期工作:早期的研究主要集中在强化学习和模仿学习上,但这些方法的效果并不理想。
-
最新进展:最近的研究发现,预训练的大模型(LLMs)可以作为智能体的“大脑”,提供规划能力。例如,Voyager利用GPT-4作为高层次规划器和低层次动作代码生成器,Plan4MC使用LLMs预先生成技能图,DEPS通过LLMs进行多步推理,GITM开发了一组结构化动作并利用LLMs生成智能体的执行计划。
-
-
具身多模态模型:
-
应用领域:具身智能体在多种环境中操作,通过合成感官感知和物理动作来实现特定目标。应用领域包括导航、具身问答、主动视觉跟踪和视觉探索等。
-
技术发展:随着大模型(LLMs)和多模态语言模型(MLLMs)的发展,研究人员能够整合多种模态以实现更有效的处理。例如,PaLM-E是一个拥有562B参数的多模态模型,擅长广泛的具身任务并展示出卓越的视觉推理能力。
-
-
配备工具的大模型:
-
扩展能力:虽然LLMs在通过提示指令解决新任务方面表现出色,但在数学计算或识别回文等简单任务上可能不如其他模型。然而,当与视觉或音频等其他模态的模型结合时,LLMs的潜力显著扩大。
-
创新方法:例如,Toolformer展示了LLMs通过微调来自我学习使用工具的能力,Visual ChatGPT通过集成各种视觉基础模型来增强交互体验,HuggingGPT利用LLMs链接Hugging Face的多样化模型来解决任务,AutoGPT通过互联网访问、内存管理和插件扩展了GPT-4的功能。MovieChat为MLLM引入了记忆机制,增强了视频理解任务的性能。此外,LLMs还可以用于目标规划,类似于语言翻译。
-
STEVE框架
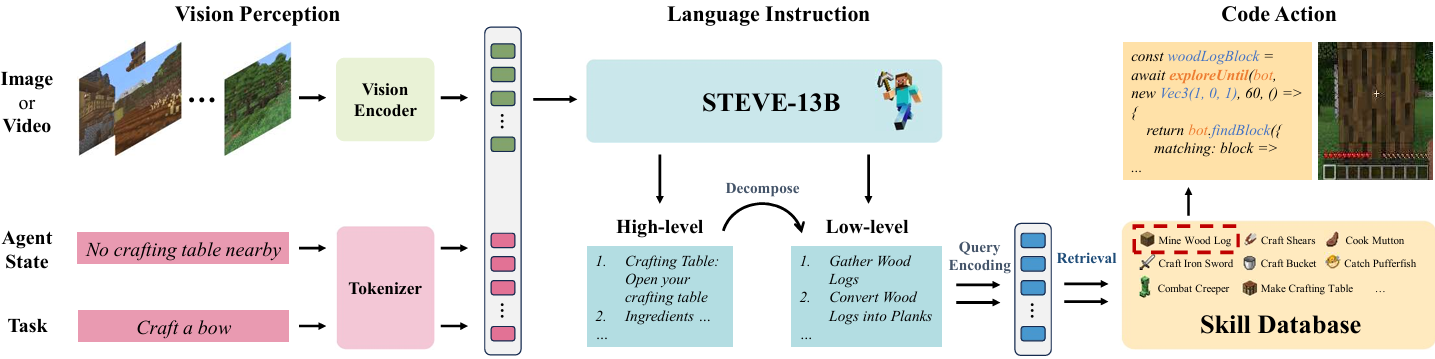
概述
STEVE是一个用于具身智能体的LLM多模态自主系统,它能够使用视觉状态和环境信息来管理和执行复杂的任务。
具体来说,STEVE通过将视觉感知、语言指令和代码动作结合起来,生成可执行的代码动作:
其中, 是整个系统的函数, 是视觉感知模块, 是语言指令模块, 是代码动作模块。
视觉感知
视觉感知部分包括一个视觉编码器 和一个文本分词器 ,它们将视觉状态 、智能体状态 和任务 转换为文本空间的token表示 :
-
视觉编码器:使用EfficientFormer的视觉分支来编码每一步的视觉状态 ,将其转换为视觉token 。
-
文本分词器:将智能体状态 和任务 转换为文本token 和 。
视觉token和文本token结合在一起,形成一个统一的token集,代表当前情境的上下文。
语言指令
语言指令模块由四个独立的LLM智能体组成,分别是Planner、Critic、Curriculum和Describer,它们各自有不同的功能:
-
Planner:制定与任务目标一致的综合指南和执行计划。
-
Critic:评估规划器的决策,提供反馈以优化策略。
-
Curriculum:通过一系列复杂任务的课程促进持续学习和适应。
-
Describer:将大量数据提炼为简洁的总结,使其更易于管理和解释。
这些智能体通过迭代推理和分解过程,将复杂的策略分解为简单的低层次指南,以便直接映射到Minecraft中的动作。
代码动作
代码动作部分是将计划和分解的指南转换为Minecraft环境中的具体动作的执行阶段。
这个过程利用一个专门的技能数据库,该数据库将代码片段与其描述和相关元数据配对,并编码为向量 以实现高效检索。
通过查询编码和余弦相似度匹配,将低层次文本动作步骤 转换为可执行的代码:
其中, 是查询编码, 是余弦相似度匹配。
训练
为了减少训练开销,论文采用了两阶段训练方法:
-
第一阶段:在STEVE-21K的知识问答对上进行预热训练,以确保一定的指令能力。
-
第二阶段:在模拟环境中进行训练,Expert LLM(集成GPT-4)生成相同情境下的指令来修改模型。
训练过程中使用负对数似然目标来优化模型的预测能力:
其中, 和 分别指非视觉输入和目标token序列, 表示模型参数, 表示目标序列的长度。
STEVE-21K数据集
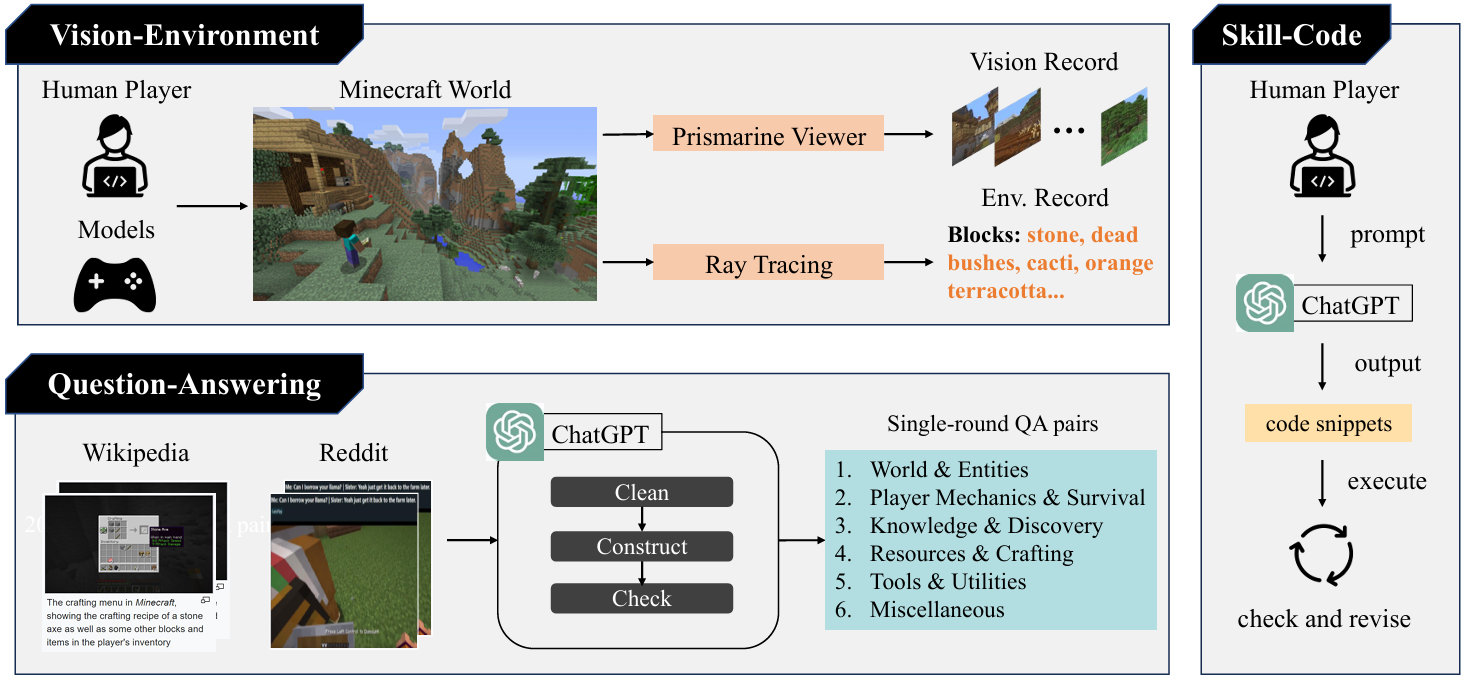
数据集构成
STEVE-21K数据集包含三个主要部分:
-
视觉-环境对:
-
内容:包含600多对来自Minecraft游戏的第一人称视角视频,涵盖六种不同的地形(如森林、沙漠、沿海等)。每对视频都包括对应视野内的环境方块实体和上下文信息。
-
用途:这些数据对用于训练视觉编码器,帮助智能体理解和解释其周围的环境。视频记录了智能体在执行任务时的操作,以及环境和聊天流的信息。
-
-
知识问答对:
-
内容:包含20,000多个来自Minecraft Wiki和Reddit论坛的问题-答案对。这些问题和答案覆盖了六种数据类型,部分数据来自先前的研究。
-
用途:这些问答对用于训练语言指令模块,帮助智能体在Minecraft环境中进行推理和决策。问答对被组织成指令、输入和输出三元组,用于训练STEVE-13B模型。
-
-
技能-代码对:
-
内容:包含210个技能执行脚本及其描述,涵盖8种技能类型(如收集、制作、探索等)。代码部分由手动编写。
-
用途:这些技能-代码对用于代码动作模块,帮助智能体执行具体的任务。每个技能都有一个描述和相应的代码片段,存储在数据库中以供检索和使用。
-
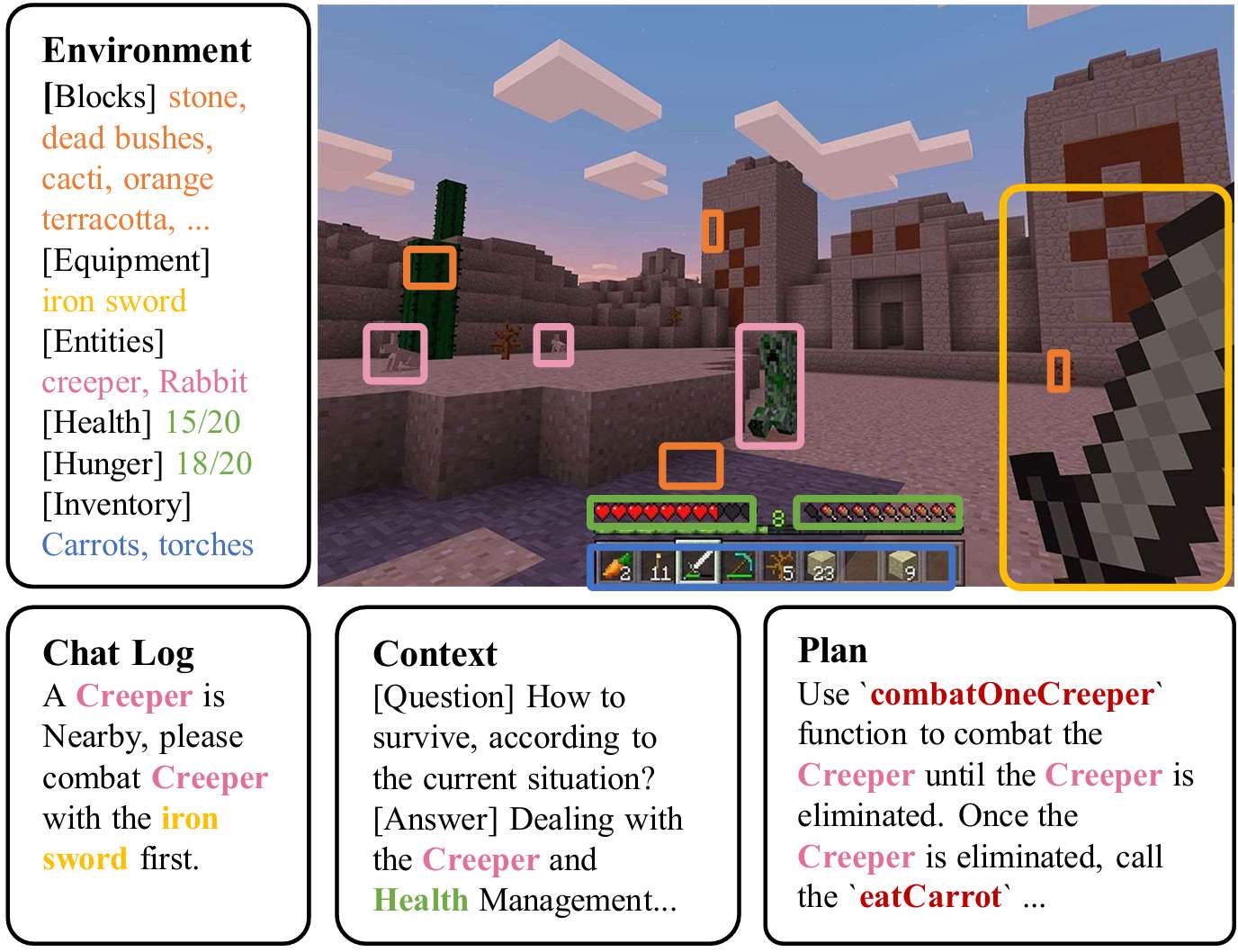
数据收集流程
-
视觉-环境对:使用STEVE-13B模型根据人类玩家定义的任务玩游戏,记录智能体操作的视频和环境信息,并使用Ray Tracing方法获取环境信息。同时记录和保存推理和分解阶段的聊天流。
-
知识问答对:从Minecraft Wiki和Reddit论坛获取信息,使用GPT-3.5清理数据为单轮问答对。LoRA用于微调过程中的资源分配。
-
技能-代码对:使用GPT-3.5结合人类玩家的代码来合成代码片段,并在游戏环境中检查和修订。
数据集的应用
STEVE-21K数据集不仅用于训练STEVE模型,还用于验证其性能。通过这些数据,研究人员可以评估模型在视觉感知、语言理解和代码执行方面的能力,从而推动具身智能体在Minecraft环境中的进一步发展。
实验
实验设置
-
模型训练:训练STEVE-7B和STEVE-13B模型,这些模型是从LLaMA-2微调而来的,使用STEVE-21K数据集中的问答对进行预热训练,并使用成功运行的模拟上下文数据进行模拟训练。
-
超参数配置:在训练过程中,使用LoRA进行微调。温度设置除任务提议外均为0,任务提议的温度设置为0.9以鼓励任务多样性。视觉单元基于EfficientFormerV2-S0,训练在STEVE-21K数据集的视觉-环境部分上进行。
-
模拟环境:实验在MineDojo和Mineflayer的基础上构建模拟环境。
基线比较
-
基线选择:由于没有立即可用的基于视觉的LLM驱动智能体,选择了几种从系统后端提取信息的算法作为基线,这些算法与实际应用有显著差异。
-
基线方法:包括AutoGPT和Voyager。AutoGPT是一个NLP自动化工具,Voyager依赖于文本接地进行感知,并具有长期程序记忆。
定量结果分析
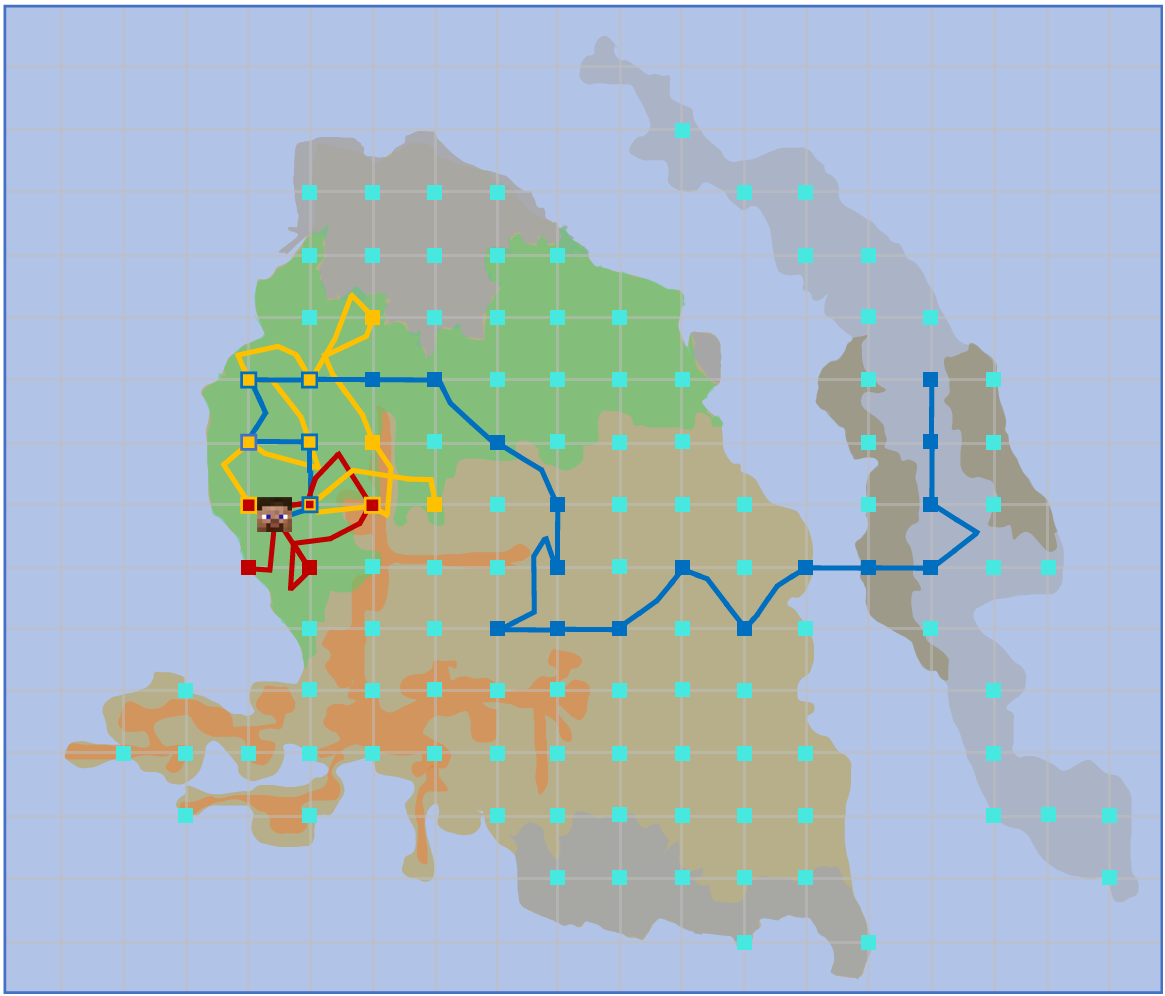
- 连续块搜索:
-
实验评估智能体的探索能力和定位指定块的熟练程度。
-
结果显示,通过视觉感知丰富信息显著提高了搜索和探索任务的效率。
-
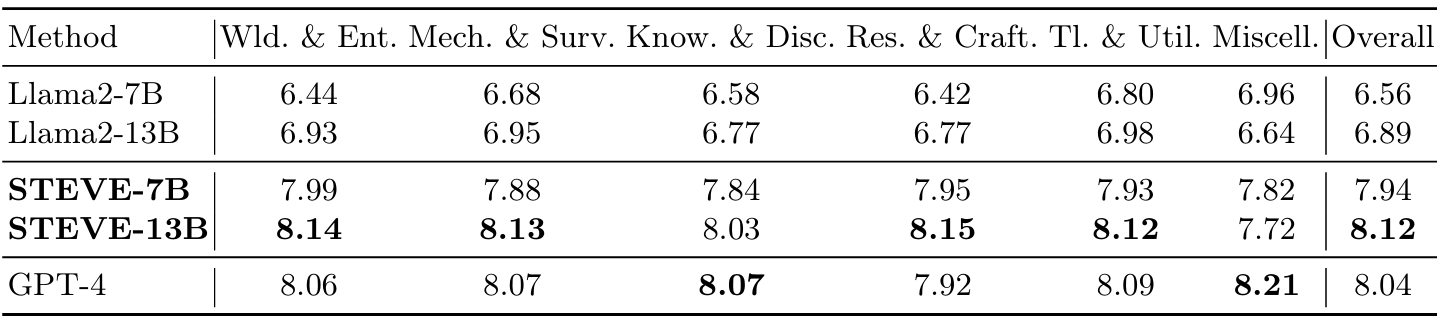
- 知识问答:
-
使用验证数据集建立问答数据库,评估模型在Minecraft相关查询上的表现。
-
STEVE-7B和STEVE-13B在所有指标上均优于LLaMA2,STEVE-13B得分最高,表明其在知识密集型任务上的优越性。
-

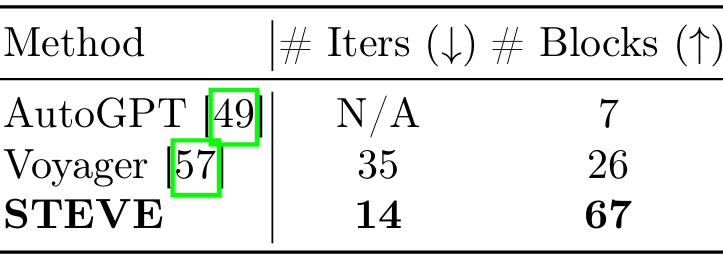
- 技术树掌握:
-
实验测试智能体在制作和使用工具层次结构上的能力。
-
STEVE在木制工具、石制工具和铁制工具方面表现出色,解锁速度显著快于AutoGPT和Voyager。
-
定性结果分析
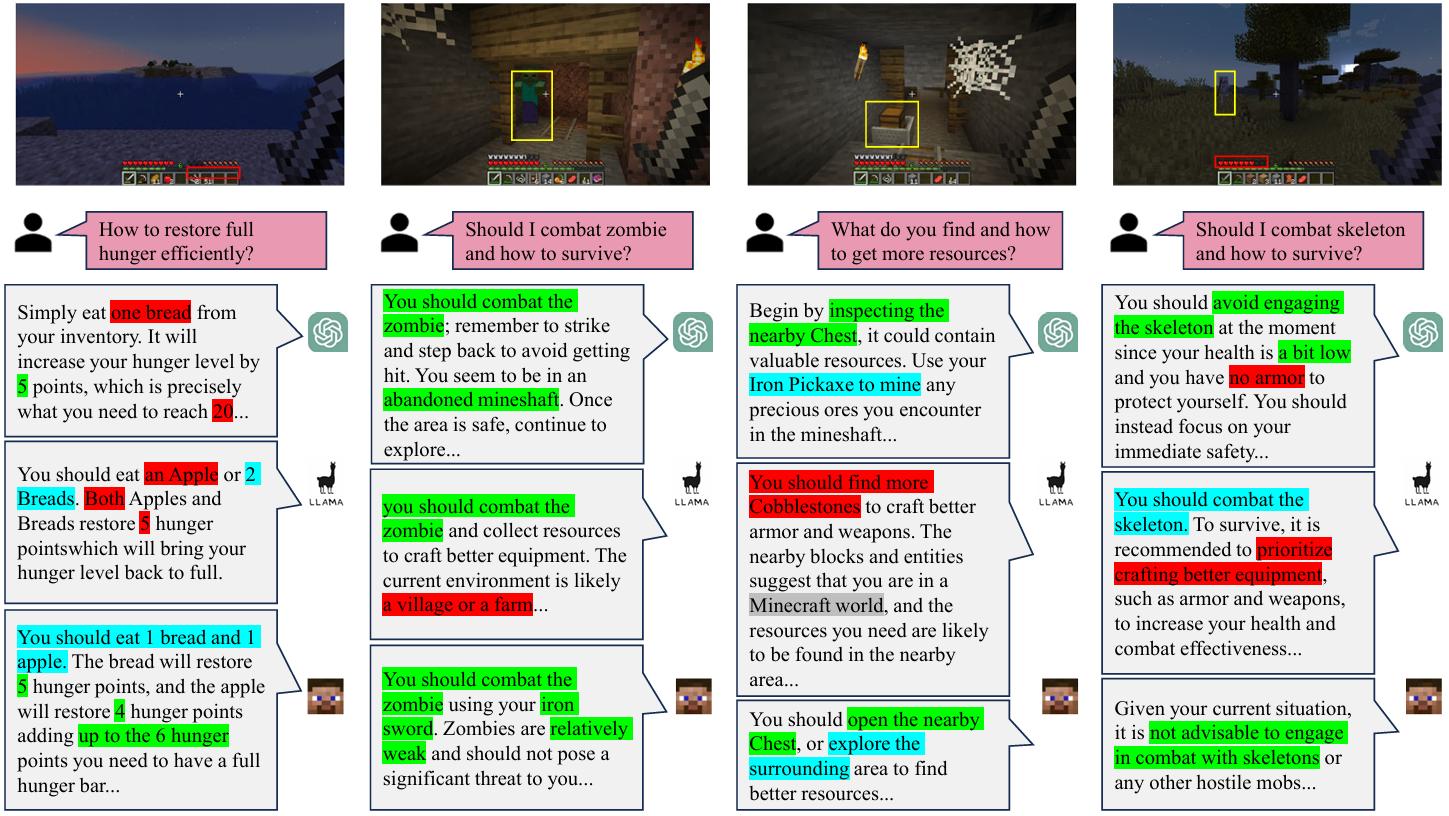
- 案例研究:
-
通过广泛的案例研究比较GPT-4、LLaMA2-13B和STEVE-13B。
-
每个模型保持相同的信息和问题输入,比较在不同环境信息下的反馈。
-
STEVE总体上取得了最佳结果,特别是在涉及数值计算的场景中表现出色。
-
消融研究

- 消融实验:
-
为了理解不同组件对系统性能的影响,进行了消融研究,重点关注Minecraft技术树掌握任务。
-
结果显示,视觉单元的缺失显著影响了系统性能,特别是在更复杂的任务中。
-
比较STEVE和GPT-4版本表明,STEVE在简单任务中表现出色,但在复杂任务中需要更少的迭代次数。
-
总结
-
STEVE通过结合视觉编码器和基于LLM的智能体,增强了多模态学习。
-
其视觉感知、语言指令和代码动作功能使其能够在虚拟环境中理解、预测和行动。
-
STEVE提供了一种使用开源语言模型创建稳健、多模态、自主具身智能体的简单方法,并提供了可验证的综合数据集STEVE-21K,支持社区的可持续发展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









