









一、Perceptron Hypothesis Set(15min)
场景:银行根据资料判断是否给客户发信用卡。是非问题

建立模型:好的(+1)、坏的(-1)。
所有特征的加权和的值与一个设定的阈值threshold进行比较:大于这个阈值,输出为+1,即发信用卡;小于这个阈值,输出为-1,即不发信用卡。

这样的h叫做proceptron(感知器)

为了计算方便通常将阈值threshold当做
w
0
w_0
w0,引入一个
x
0
x_0
x0与
w
0
w_0
w0相乘,简化了计算。
为了更清晰地说明感知机模型,我们假设Perceptrons在二维平面上,即
h
(
x
)
=
s
i
g
n
(
w
0
+
w
1
x
1
+
w
2
x
2
)
h
(
x
)
=
s
i
g
n
(
w
0
+
w
1
x
1
+
w
2
x
2
)
h(x)=sign(w_0+w_1x_1+w_2x_2)h(x)=sign(w_0+w_1x_1+w_2x_2)
h(x)=sign(w0+w1x1+w2x2)h(x)=sign(w0+w1x1+w2x2)。其中,
w
0
+
w
1
x
1
+
w
2
x
2
=
0
w_0+w_1x_1+w_2x_2=0
w0+w1x1+w2x2=0是平面上一条分类直线,直线一侧是正类(+1),直线另一侧是负类(-1)。权重w不同,对应于平面上不同的直线。

从几何角度,proceptron就是几何上的一条线。
习题1 选择2

二、Perceptron Learning Algorithm(PLA)(19min)
怎么选择一条最好的线(理想的
g
g
g)。如何设计一个演算法
A
A
A,来选择一个最好的直线,能将平面上所有的正类和负类完全分开,也就是找到最好的
g
g
g,使
g
≈
f
g≈f
g≈f。

使用逐点修正的思想,随意去一条直线,看哪些点分错了,然后一个个点修正,逐步修正。实际操作中,可以一个点一个点地遍历,发现分类错误的点就进行修正,直到所有点全部分类正确。这种被称为Cyclic PLA。

图解的形式来介绍PLA的修正过程:

找第一条线

更新第一个点

再修正一个点


叉叉表示错误,继续转回来,又转太多了






这里是一条完美的线,分割成两类。

找到一个犯错的点,如果犯错就修正他
习题2 选择3

三、Guarantee of PLA(12min)
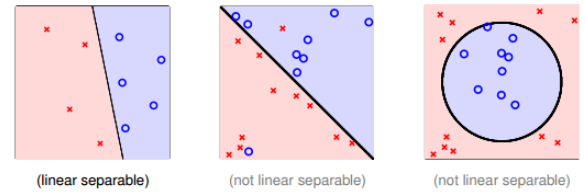
看看PLA什么时候停下来,要达到这个终止条件,就必须保证D是线性可分(linear separable)。

对于线性可分的情况,如果有这样一条直线,能够将正类和负类完全分开,令这时候的目标权重为
w
f
w_f
wf,则对每个点,必然满足
y
n
=
s
i
g
n
(
w
T
x
n
)
y_n=sign(w^Tx_n)
yn=sign(wTxn),即对任一点:
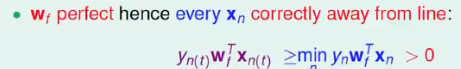
PLA会对每次错误的点进行修正,更新权重
w
t
+
1
w_{t+1}
wt+1的值,如果
w
t
+
1
w_{t+1}
wt+1与
w
f
w_f
wf越来越接近,数学运算上就是内积越大,那表示
w
t
+
1
w_{t+1}
wt+1是在接近目标权重
w
f
w_f
wf,证明PLA是有学习效果的。所以,我们来计算
w
t
+
1
w_{t+1}
wt+1与
w
f
w_f
wf的内积:

从推导可以看出,
w
t
+
1
w_{t+1}
wt+1与
w
f
w_f
wf的内积跟
w
t
w_t
wt与
w
f
w_f
wf的内积相比更大了。似乎说明了
w
t
+
1
w_{t+1}
wt+1更接近
w
f
w_f
wf,但是内积更大,可能是向量长度更大了,不一定是向量间角度更小。所以,下一步,我们还需要证明
w
t
+
1
w_{t+1}
wt+1与
w
t
w_t
wt向量长度的关系:

w
t
w_t
wt只会在分类错误的情况下更新,最终得到的
∣
∣
w
t
+
1
2
∣
∣
||w^2_{t+1}||
∣∣wt+12∣∣相比
∣
∣
w
t
2
∣
∣
||w^2_t||
∣∣wt2∣∣的增量值不超过
m
a
x
∣
∣
x
n
2
∣
∣
max||x^2_n||
max∣∣xn2∣∣。也就是说,
w
t
w_t
wt的增长被限制了,
w
t
+
1
w_{t+1}
wt+1与
w
t
w_t
wt向量长度不会差别太大!
如果令初始权值
w
0
=
0
w_0=0
w0=0,那么经过
T
T
T次错误修正后,有如下结论:



上述不等式左边其实是
w
T
w_T
wT与
w
f
w_f
wf夹角的余弦值,随着T增大,该余弦值越来越接近1,即
w
T
w_T
wT与
w
f
w_f
wf越来越接近。同时,需要注意的是,
T
c
o
n
s
t
a
n
t
≤
1
\sqrt{T}constant\le1
Tconstant≤1,也就是说,迭代次数
T
T
T是有上界的。根据以上证明,我们最终得到的结论是:
w
t
+
1
w_{t+1}
wt+1与
w
f
w_f
wf的是随着迭代次数增加,逐渐接近的。而且,
P
L
A
PLA
PLA最终会停下来(因为
T
T
T有上界),实现对线性可分的数据集完全分类。
参考:台湾大学林轩田机器学习基石课程学习笔记2 – Learning to Answer Yes/No
习题3 选择2

四、Non-Separable Data(12min)
上一部分,我们证明了线性可分的情况下,PLA是可以停下来并正确分类的,但对于非线性可分的情况,
w
f
w_f
wf实际上并不存在,那么之前的推导并不成立,PLA不一定会停下来。所以,PLA虽然实现简单,但也有缺点:

对于非线性可分的情况,我们可以把它当成是数据集D中掺杂了一下noise,事实上,大多数情况下我们遇到的D,都或多或少地掺杂了noise。这时,机器学习流程是这样的:

在非线性情况下,我们可以把条件放松,即不苛求每个点都分类正确,而是容忍有错误点,取错误点的个数最少时的权重w:

事实证明,上面的解是NP-hard问题,难以求解。然而,我们可以对在线性可分类型中表现很好的PLA做个修改,把它应用到非线性可分类型中,获得近似最好的g。
修改后的PLA称为Packet Algorithm。它的算法流程与PLA基本类似,首先初始化权重w0w0,计算出在这条初始化的直线中,分类错误点的个数。然后对错误点进行修正,更新w,得到一条新的直线,在计算其对应的分类错误的点的个数,并与之前错误点个数比较,取个数较小的直线作为我们当前选择的分类直线。之后,再经过n次迭代,不断比较当前分类错误点个数与之前最少的错误点个数比较,选择最小的值保存。直到迭代次数完成后,选取个数最少的直线对应的w,即为我们最终想要得到的权重值。
贪心思想:找到尽可能多正确的线

习题4 选择1 贪心算法会需要额外的计算时间
总结

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









