






公众号: 小叶叶学Python
4年人力资源从业经验,情报学硕士,主要内容涵盖python、数据分析和人力资源相关内容
本文运用自然语言处理技术,对中文小说《神雕侠侣》人物角色进行抽取,为使用通过社会网络分析法对人物关系进行分析奠定基础,使文学研究者、社会学家和普通读者对小说人物关系和背景有更全面的认识
自然语言处理技术
自然语言处理(NLP)是一门融语言学、计算机科学、数学于一体的科学。国外学者于20世纪40年代末至50年代初开始NLP相关的研究,近年来,随着人工智能和计算机技术的发展,自然语言处理(NLP)已经成为一个重要的人工智能发展方向,目前已广泛的应用于机器翻译、问答系统、文本分类、信息检索、自动文本摘要等领域。中文的自然语言处理相对于英文还是有诸多差异的,英文是以空格来区分词语,每一个单词即是一个词语,而中文则是以字为字符单位,以词语来表达意思,而且存在一词多义、多词一义等情况,所以相对于英文来说,中文的自然语言处理更为艰难。分词、词性标注、句法分析是中文自然语言处理的三大基本任务,本文主要应用分词、词性标注两类处理技术。
jieba库基本介绍
jieba库概述
jieba是优秀的中文分词第三方库 中文文本需要通过分词获得单个的词语 jieba是优秀的中文分词第三方库,需要额外安装 jieba库提供三种分词模式,最简单只需掌握一个函数
jieba分词的原理
Jieba分词依靠中文词库 利用一个中文词库,确定汉字之间的关联概率 汉字间概率大的组成词组,形成分词结果 除了分词,用户还可以添加自定义的词组
jieba库的优点
支持三种分词模式:
精确模式,试图将句子最精确地切开,适合文本分析;
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
安装jieba:
命令行安装方法
pip3 install jieba
jupyter notebook中的安装方法
!pip3 install jieba
!pip3 install jieba
Requirement already satisfied: jieba in d:\ancanda3\lib\site-packages (0.39)
jieba库常用函数
分词
| 代码 | 功能 |
|---|---|
| jieba.cut(s) | 精确模式,返回一个可迭代的数据类型 |
| jieba.cut(s,cut_all=True) | 全模式,输出文本s中所有可能单词 |
| jieba.cut_for_search(s) | 搜索引擎模式,适合搜索建立索引的分词 |
| jieba.lcut(s) | 精确模式,返回一个列表类型,常用 |
| jieba.lcut(s,cut_all=True) | 全模式,返回一个列表类型,常用 |
| jieba.lcut_for_search(s) | 搜索引擎模式,返回一个列表类型,常用 |
| jieba.add_word(w) | 向词典中增加新词 |
词性标注
Jieba0.39版本提供55种词性标注,部分符号及含义如表1所示。由表1可知,人名被标注为nr,因此对小说进行分词和词性标注后的文本进行进一步提取,提取出词性为nr的词作为人物角色名称,即可构建角色列表。
import jieba
text = '我来到北京清华大学'
wordlist = jieba.lcut(text)
wordlist
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\z\AppData\Local\Temp\jieba.cache
Loading model cost 1.717 seconds.
Prefix dict has been built succesfully.
['我', '来到', '北京', '清华大学']
jieba分词的简单应用
使用 jieba 分词对一个文本进行分词,统计长度大于2,出现次数最多的词语,这里以《神雕侠侣》为例
import jieba
txt = open("神雕侠侣-网络版.txt","r",encoding="utf-8").read()
words = jieba.lcut(txt) # 使用精确模式对文本进行分词
counts = {} # 通过键值对的形式存储词语及其出现的次数
for word in words:
if len(word) == 1: # 单个词语不计算在内
continue
else:
counts[word] = counts.get(word, 0) + 1# 遍历所有词语,每出现一次其对应的值加 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序
for i in range(len(items)):
word, count = items[i]
print("{0:<5}{1:>5}".format(word, count))

从小说中抽取出现的人名及次数
词性标注
Jieba0.39版本提供55种词性标注,部分符号及含义如表1所示。由表1可知,人名被标注为nr,因此对小说进行分词和词性标注后的文本进行进一步提取,提取出词性为nr的词作为人物角色名称,即可构建角色列表。

import jieba.posseg as psg
sent='中文分词是文本处理不可或缺的一步!'
seg_list=psg.cut(sent)
for w in seg_list:
if w.flag == "n":
print(w.flag)
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\z\AppData\Local\Temp\jieba.cache
Loading model cost 1.535 seconds.
Prefix dict has been built succesfully.
n
n
jieba词性标注的简单应用
使用 jieba 分词对一个文本进行分词及词性标注,统计词性为nr,出现次数最多的词语,这里以《神雕侠侣》为例
import jieba
import jieba.posseg as psg
txt = open("神雕侠侣-网络版.txt","r",encoding="utf-8").read()
words = psg.cut(txt) # 使用精确模式对文本进行分词
counts = {} # 通过键值对的形式存储词语及其出现的次数
for word in words:
if len(word.word) == 1: # 单个词语不计算在内
continue
else:
if word.flag == "nr": # 仅统计词性为nr的词语
counts[word] = counts.get(word, 0) + 1# 遍历所有词语,每出现一次其对应的值加 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序
fi = open("人物角色提取.txt","w",encoding="utf-8")
for i in range(len(items)):
word,pos = items[i][0]
count = items[i][1]
a = word + ","+ str(count)
fi.write(a + "\n")
fi.close()
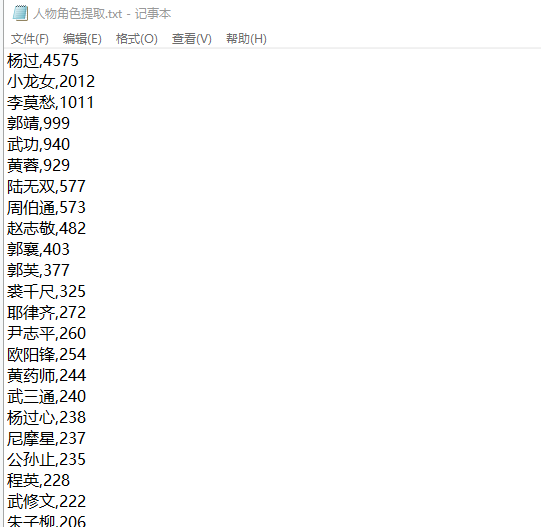
提取后的文件内容如下图所示
近期文章
使用networkx及matplotlib库实现社会网络分析及可视化
公众号后台回复关键词“20191204”,即可获得课件资源,请在如果觉得有用,欢迎转发支持~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









