






数据分析实战又来啦,今天我们进行的是北京高档酒店的价格因素分析,话不多说,直接上代码。
1. 导入所需要的包
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import warnings
warnings.filterwarnings("ignore")
2.读取文件
hotel=pd.read_csv('hoteldata.csv')
#将四项评分的平均分作为总体评分
hotel['总体评分']=(hotel['卫生评分']+hotel['服务评分']+hotel['设施评分']+hotel['位置评分'])/4
#2015之前的旧装修,2015之后的为新装修
hotel['装修新旧']=pd.cut(hotel['装修时间'],[0,2015,2019],labels=['旧装修','新装修'])
hotel.head()
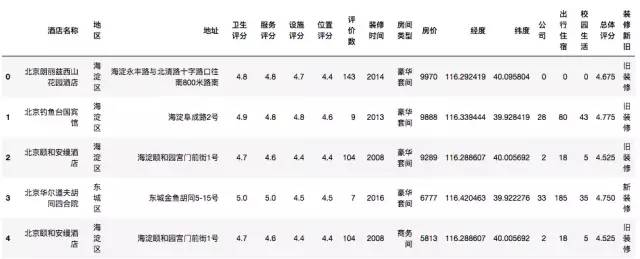
将各个酒店的情况进行评分,总体评分由卫生评分、服务评分、设施评分和位置评分构成,装修的新旧以装修时间来划分。
3 描述性统计分析
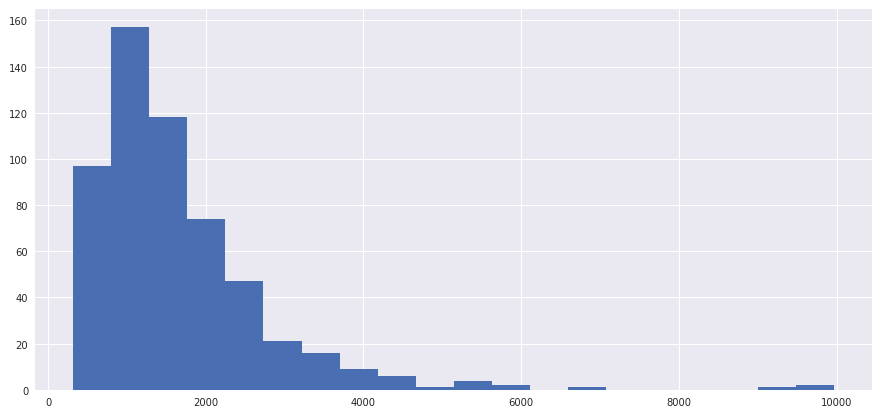
3.1 酒店房价分布直方图
price=hotel['房价']
plt.figure("hist",figsize=(15,7))
n, bins, patches = plt.hist(price, bins=20)
plt.show()
3.2 因变量数字特征
# 酒店房价平均值
hotel['房价'].mean()
1655.5125899280577
3.3 酒店因素箱型图
#酒店房间类型
hotel['对数房价']=np.log(hotel['房价'])
plt.figure(figsize=(7,7))
sns.boxplot(x='房间类型',y='对数房价',data=hotel)
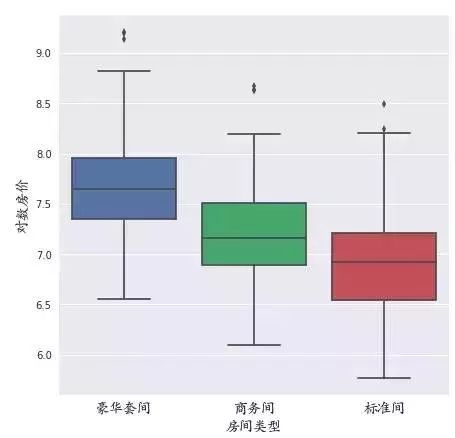
符合一般的房价标准,按照标准间、商务间、豪华套间价格依次递增。
#酒店区域因素分析
plt.figure(figsize=(7,7))
sns.boxplot(x='地区',y='对数房价',data=hotel)
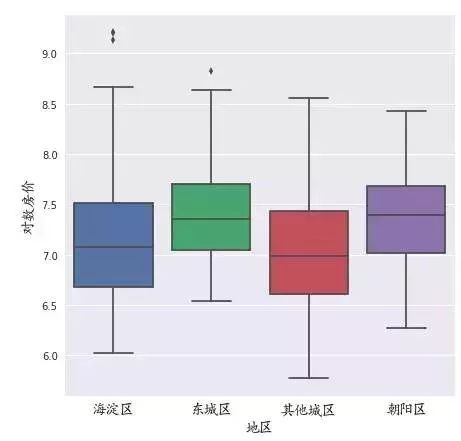
根据地区划分的箱型图展示,其中,东城区和朝阳区的房价最高,海淀区紧随其后。
#酒店装修时间
hotel['对数房价']=np.log(hotel['房价'])
plt.figure(figsize=(7,7))
sns.boxplot(x='装修新旧',y='对数房价',data=hotel)
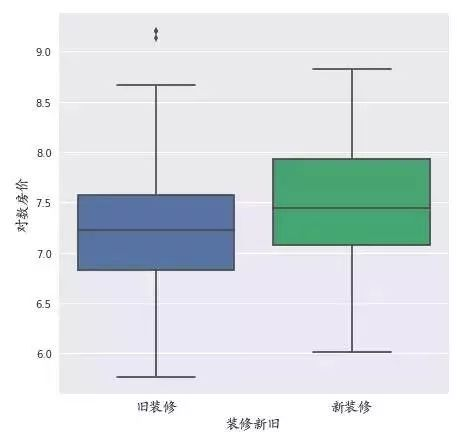
新装修的价格高于就旧装修,并且价格差异明显。
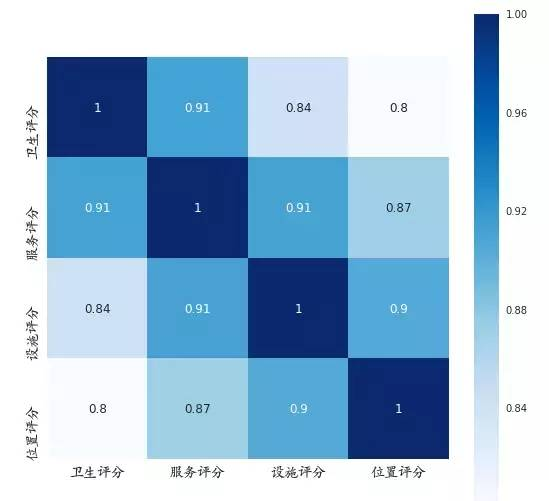
3.4 评分因素相关系数
grade=pd.DataFrame([hotel['卫生评分'],hotel['服务评分'],hotel['设施评分'],hotel['位置评分']]).transpose()
correlation=grade.corr()
plt.subplots(figsize=(9, 9)) # 设置画面大小
sns.heatmap(correlation, annot=True, vmax=1, square=True, cmap="Blues")
#评分因素箱型图
hotel['评分分组']=pd.cut(hotel['总体评分'],[0,4.5,5.0],labels=['评分低','评分高'])
sns.boxplot(x='评分分组',y='对数房价',data=hotel)
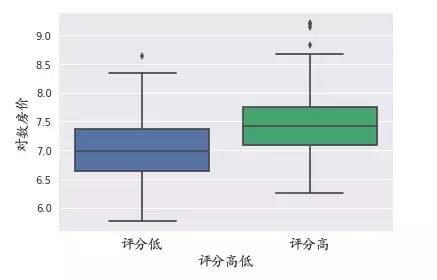
评分高的房价高于评分低的房价。
4 对数线性回归模型
4.1 特征处理
#特征选择与处理
features=['地区','房间类型','装修新旧','总体评分','校园生活','公司','出行住宿']
X=hotel[features]
X['地区']=pd.get_dummies(X['地区'])
X['房间类型']=pd.get_dummies(X['房间类型'])
X['装修新旧']=pd.get_dummies(X['装修新旧'])
# 对特征进行归一化处理
from sklearn import preprocessing
X['总体评分']=preprocessing.scale(X['总体评分'])
X['校园生活']=preprocessing.scale(X['校园生活'])
X['公司']=preprocessing.scale(X['公司'])
X['出行住宿']=preprocessing.scale(X['出行住宿'])
4.2 模型拟合
from sklearn import linear_model
model=linear_model.LinearRegression()
model.fit(X,y)
4.3 计算残差
np.mean(abs(model.predict(X)-y))
0.375942
4.4 查看模型拟合情况
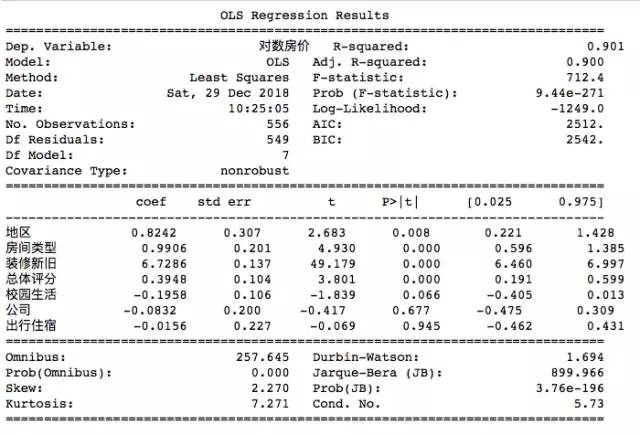
import statsmodels.api as sm
est=sm.OLS(y,X).fit()
print(est.summary())
往期文章Pandas时间序列数据操作
readability: 英文文本数据可读性库
Matplotlib中的plt和ax都是啥?
70G上市公司定期报告数据集
5个小问题带你理解列表推导式
文本数据清洗之正则表达式
Python网络爬虫与文本数据分析
综述:文本分析在市场营销研究中的应用
如何批量下载上海证券交易所上市公司年报
Numpy和Pandas性能改善的方法和技巧
漂亮~pandas可以无缝衔接Bokeh
YelpDaset: 酒店管理类数据集10+G
先有收获,再点在看!

公众号后台回复关键字【酒店】获取数据集

















 1508
1508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









