







北京高档酒店价格影响因素分析
1、数据读取与清洗
# 导入所需模块
import pandas as pd
import numpy as np
# 读入数据
data = pd.read_csv('C:/Users/ASUS/Desktop/hoteldata.csv')
# 变量重命名
data.columns = ['hotel_nam','area','address', # 重命名
'health_score','service_score',
'facility_score','position_score',
'evaluation_num','decoration_time',
'room_type','house_price','longitude',
'latitude','company','travel_accom',
'compus_life']对数据的变量进行重命名,避免之后出现不必要的麻烦
# 酒店因素评分
# 为了避免多重共线性
total_score = [data.health_score[i] + data.service_score[i] + data.facility_score[i] + data.position_score[i] for i in range(0,len(data))]
total_score = np.array(total_score)/4
data['total_score'] = pd.DataFrame(total_score)
# 对装修时间进行处理
time_cut = []
for i in data.decoration_time:
if i > 2015:
j = '新装修'
else:
j = '旧装修'
time_cut.append(j)
data['time_cut'] = time_cut
#把其他地区作为基准组
data['area'] = data['area'].astype('category')
1、酒店因素评分,即将酒店的卫生,服务,设施和位置评分求和再求均值,作为酒店的整体评分。
2、线形相关性比较强的变量会导致多重共线性,因此将四个相同类型的变量归一化。
3、将地区变量因子量化。
2、描述统计
2.1 因变量
(1)因变量直方图
# 导入绘图模块
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制酒店价格频次统计直方图
plt.hist(data['house_price'],edgecolor='black',linewidth=1) # 绘图
plt.xlabel('酒店房价分布直方图') # x轴标签
plt.ylabel('频次') # y轴标签
plt.show()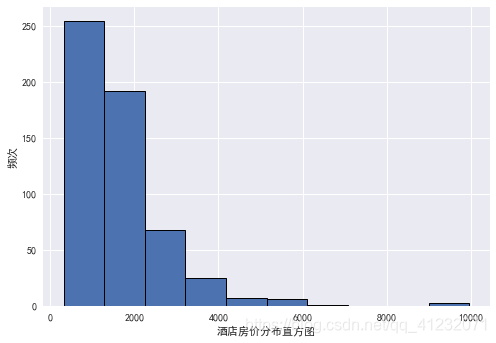
(2)因变量数字特征
np.median(data.house_price) # 中位数1389.5
np.mean(data.house_price) # 均值1655.5125899280577
# 对房间价格取对数
import math
data['house_price'] = data['house_price'].apply(lambda x :math.log(x))
2.2 自变量
(1)酒店因素箱线图
data.sort_values(by =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3844
3844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









