






2021暑期 | 结构模型、Stata实证前沿、Python数据挖掘暑假工作坊
前天分享了 Clumper | dplyr式的Python数据操作包,其实Clumper有点跟之前的
plydata库 | 数据操作管道操作符>> ,感兴趣的同学可以一起复习一下。
今天我们学习Clumper的常用操作函数。
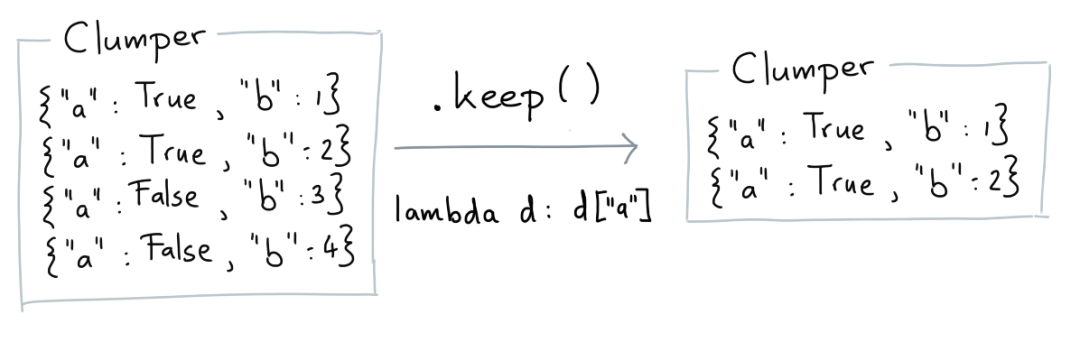
Keep
keep函数可以从原始数据中抽取符合指定条件的子集。
from clumper import Clumper
list_dicts = [{'a': 1},
{'a': 2},
{'a': 3},
{'a': 4}]
(Clumper(list_dicts)
.keep(lambda d: d['a'] >= 3)
.collect() #试一试去掉.collect()后的效果
)
[{'a': 3},
{'a': 4}]
可以实现缺失值处理,以不同的方式实现pandas的.dropna()的功能。
from clumper import Clumper
data = [
{"a": 1, "b": 4},
{"a": 2, "b": 3},
{"a": 3, "b": 2},
{"a": 4},
]
#只保留含有b的字段
(Clumper(data)
.keep(lambda d: 'b' in d.keys())
.collect()
)
[{'a': 1, 'b': 4},
{'a': 2, 'b': 3},
{'a': 3, 'b': 2}]
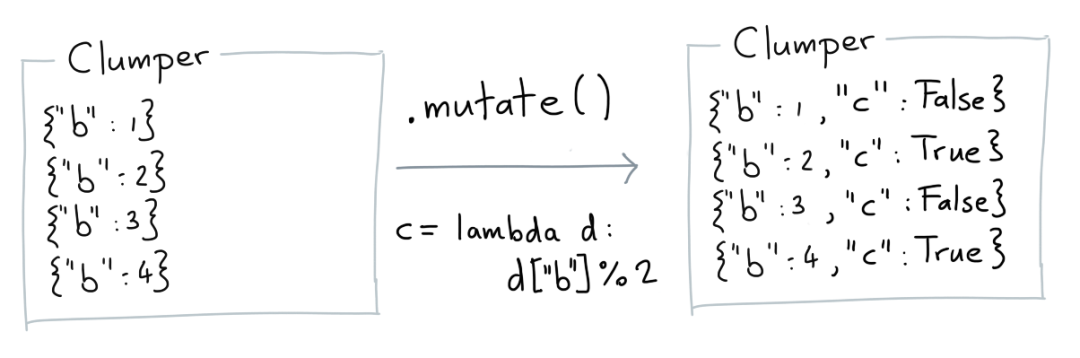
Mutate
mutate可以在每条记录中,创建新字段、改写旧字段。
from clumper import Clumper
list_dicts = [
{'a': 1, 'b': 2},
{'a': 2, 'b': 3, 'c':4},
{'a': 1, 'b': 6}]
#新建了c和s字段
(Clumper(list_dicts)
.mutate(c=lambda d: d['a'] + d['b'],
s=lambda d: d['a'] + d['b'] + d['c'])
.collect()
)
[{'a': 1, 'b': 2, 'c': 3, 's': 6},
{'a': 2, 'b': 3, 'c': 5, 's': 10},
{'a': 1, 'b': 6, 'c': 7, 's': 14}]
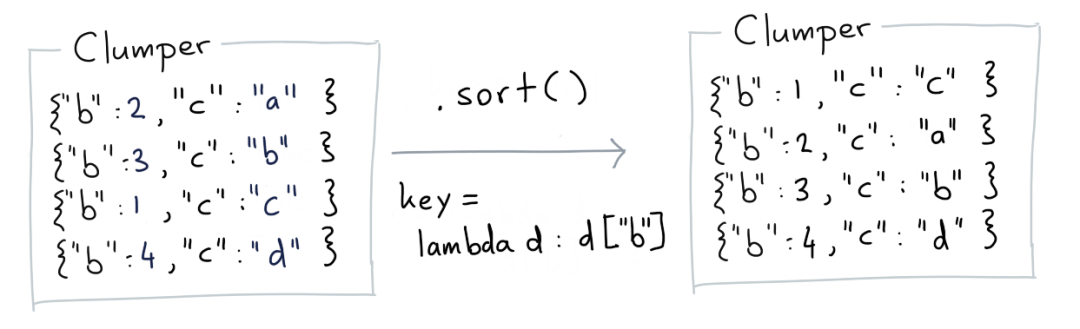
Sort
sort可以实现排序
from clumper import Clumper
list_dicts = [
{'a': 1, 'b': 2},
{'a': 3, 'b': 3},
{'a': 2, 'b': 1}]
(Clumper(list_dicts)
.sort(lambda d: d['b']) #默认升序
.collect()
)
[{'a': 2, 'b': 1},
{'a': 1, 'b': 2},
{'a': 3, 'b': 3}]
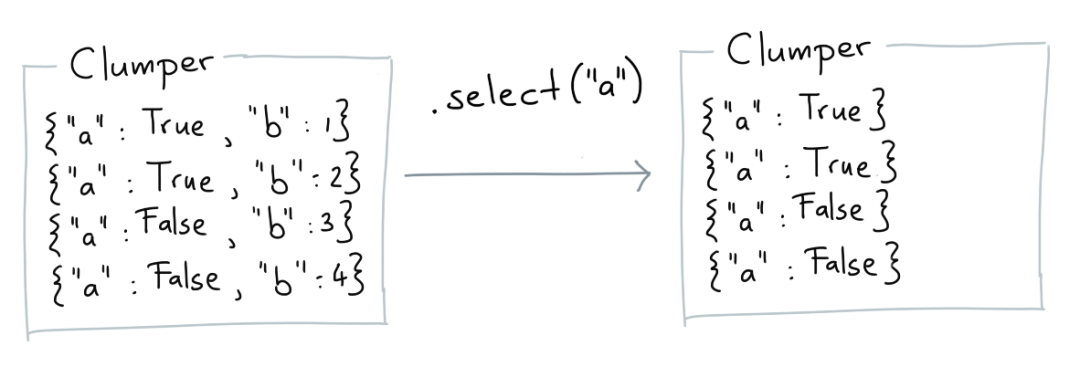
Select
select挑选每条记录中的某个(些)字段
from clumper import Clumper
list_dicts = [
{'a': 1, 'b': 2},
{'a': 2, 'b': 3, 'c':4},
{'a': 1, 'b': 6}]
(Clumper(list_dicts)
.select('a')
.collect()
)
[{'a': 1},
{'a': 2},
{'a': 1}]
Drop
剔除某个(些)字段。
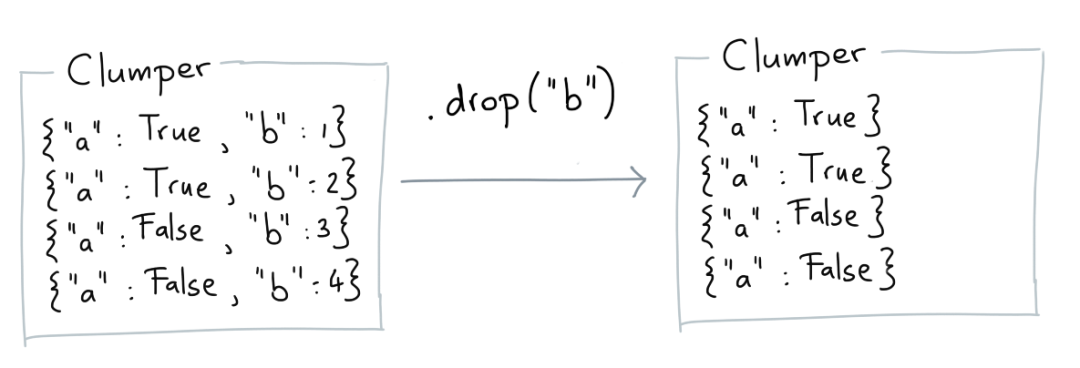
from clumper import Clumper
list_dicts = [
{'a': 1, 'b': 2},
{'a': 2, 'b': 3, 'c':4},
{'a': 1, 'b': 6}]
(Clumper(list_dicts)
.drop('c')
.collect()
)
[{'a': 1, 'b': 2},
{'a': 2, 'b': 3},
{'a': 1, 'b': 6}]
GroupBy
根据某个(些)字段对数据集进行分组,得到不同Group类的集合。一般与.agg()方法联合使用。

from clumper import Clumper
grade_dicts = [
{'gender': '男', 'grade': 98, 'name': '张三'},
{'gender': '女', 'grade': 88, 'name': '王五'},
{'gender': '女', 'grade': 99, 'name': '赵六'},
{'gender': '男', 'grade': 58, 'name': '李四'}]
(Clumper(grade_dicts)
.group_by("gender")
.groups==('gender', )
)
True
Ungroup
GroupBy的反操作
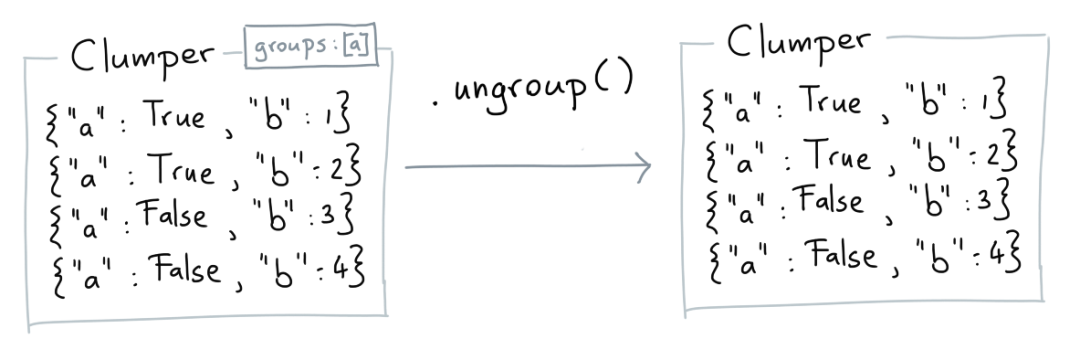
from clumper import Clumper
grade_dicts = [
{'gender': '男', 'grade': 98, 'name': '张三'},
{'gender': '女', 'grade': 88, 'name': '王五'},
{'gender': '女', 'grade': 99, 'name': '赵六'},
{'gender': '男', 'grade': 58, 'name': '李四'}]
(Clumper(grade_dicts)
.group_by("gender")
.ungroup().groups == tuple()
)
True
精选文章
腾讯课堂 | Python网络爬虫与文本分析
B站视频 | Python自动化办公
语法最简单的微博通用爬虫weibo_crawler
发布一个智能解析算法库
hiResearch 定义自己的科研首页
Clumper | dplyr式的Python数据操作包
大邓github汇总, 觉得有用记得star
multistop ~ 多语言停用词库
Jaal 库 轻松绘制动态社交网络关系图
SciencePlots | 科研样式绘图库
使用streamlit上线中文文本分析网站
爬虫实战 | 采集&可视化知乎问题的回答
Clumper | dplyr式的Python数据操作包
plydata库 | 数据操作管道操作符>>
plotnine: Python版的ggplot2作图库
读完本文你就了解什么是文本分析
文本分析在经管领域中的应用概述
综述:文本分析在市场营销研究中的应用
plotnine: Python版的ggplot2作图库
Wow~70G上市公司定期报告数据集
漂亮~pandas可以无缝衔接Bokeh
YelpDaset: 酒店管理类数据集10+G
腾讯课堂 | Python网络爬虫与文本分析
B站视频 | Python自动化办公
语法最简单的微博通用爬虫weibo_crawler
发布一个智能解析算法库
hiResearch 定义自己的科研首页
Clumper | dplyr式的Python数据操作包
大邓github汇总, 觉得有用记得star
multistop ~ 多语言停用词库
Jaal 库 轻松绘制动态社交网络关系图
SciencePlots | 科研样式绘图库
使用streamlit上线中文文本分析网站
爬虫实战 | 采集&可视化知乎问题的回答
Clumper | dplyr式的Python数据操作包
plydata库 | 数据操作管道操作符>>
plotnine: Python版的ggplot2作图库
读完本文你就了解什么是文本分析
文本分析在经管领域中的应用概述
综述:文本分析在市场营销研究中的应用
plotnine: Python版的ggplot2作图库
Wow~70G上市公司定期报告数据集
漂亮~pandas可以无缝衔接Bokeh
YelpDaset: 酒店管理类数据集10+G
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









