






read函数从打开的设备或文件中读取数据。
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
返回值:成功返回读取的字节数,出错返回-1并设置errno,如果在调用read之前已到达文件末尾,则这次read返回0
参数count是请求读取的字节数,读上来的数据保存在缓冲区buf中,同时文件的当前读写位置向后移。注意这个读写位置和使用C标准I/O库时的读写位置有可能不同,这个读写位置是记在内核中的,而使用C标准I/O库时的读写位置是用户空间I/O缓冲区中的位置。
有些情况下,实际读到的字节数(返回值)会小于请求读的字节数count,例如:
1.读常规文件时,在读到count个字节之前已到达文件末尾。
2.从终端设备读,通常以行为单位,读到换行符就返回了。
情况1代码演示:
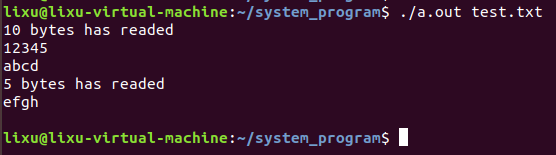
#include "./common/head.h" /*功能: *打开一个文件,第一次读取10个字符,第2次再读取10个字符 *验证当读到文件末尾时,read的返回参数 *注意:文件中换行也占一个字符,如test.txt中5和h后面就有一个换行,可以用NodePad++软件来看该文件中所有隐藏的字符,便于调试。 *test.txt如下(用ll命令查看,占15字节): 12345 abcdefgh */ int main(int argc, char **argv) { if(argc != 2){ //./a.out test.txt printf("usage: cmd filename\n"); exit(1); } int fd = open(argv[1], O_RDONLY); if(fd < 0){ perror("open"); exit(1); } int n; char buff[20] = {0}; n = read(fd, buff, 10); //第1次读取10个字节 prinrf("%d bytes has readed\n", n); //文件未被读完,打印10 //打印读到的字节 for(int i = 0; i < n; i++) { printf("%c", buff[i]); } printf("\n"); n = read(fd, buff, 10); //第2次读取10个字节,当读到第5个字节时,已读到文件末尾 prinrf("%d bytes has readed\n", n); //文件未被读完,打印5 for(int i = 0; i < n; i++) { printf("%c", buff[i]); } printf("\n"); close(fd); return 0; }结果:
解析:
第一次读取10个字节:
12345\nabcd
代码打印换行
第二次读取5个字节(虽然代码中count传入的是10,但已经读到文件末尾,只读到5个字符):
efgh\n
代码打印换行
情况2代码演示:
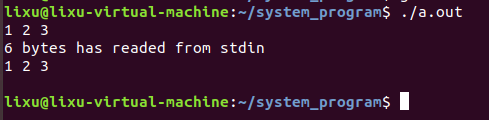
#include "common/head.h" /*功能: *从标准输入读取数据,并打印出来 */ int main() { char buff[20] = {0}; size_t n = read(STDIN_FILENO, buff, 10); //从标准输入中读取10字节。STDIN_FILENO宏在unistd.h中被定义0,代表标准输入 if(n < 0){ perror("READ STDIN"); exit(1); } //当终端输入回车时,read函数才会开始读,并执行到这里 printf("%d bytes has readed from stdin\n", n); for(int i = 0; i < n; i++) { printf("%c", buff[i]); } putchar(10); //\n的ascii码是10,相当于输出一个换行 return 0; }结果:
解析:
在终端输入:
1 2 3\n
终端设备以换行为单位,read函数开始执行,读到6个字符(包括空格和换行)
然后调用printf打印读到的字符
最后puchar一个换行
拓展:
如果终端的输入超过10个字节,剩下的字符会被bash接住,并且尝试解析这些字符所代表的命令。
产生这一现象是因为标准输入中的数据像水流一样传输过来,当bash调用了./a.out后,bash会转入后台运行,当./a.out程序结束后,bash又从输入流中获取数据。
write函数向打开的设备或文件中写数据。
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
返回值:成功返回写入的字节数,出错返回-1并设置errno















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









