







目录
1.血统概念
利用内存加快数据加载,在众多的其它的In-Memory类数据库或Cache类系统中也有实现,Spark的主要区别在于它处理分布式运算环境下的数据容错性(节点实效/数据丢失)问题时采用的方案。为了保证RDD中数据的鲁棒性,RDD数据集通过所谓的血统关系(Lineage)记住了它是如何从其它RDD中演变过来的。相比其它系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据转换(Transformation)操作(filter, map, join etc.)行为。当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。这种粗颗粒的数据模型,限制了Spark的运用场合,但同时相比细颗粒度的数据模型,也带来了性能的提升。
2.宽依赖和窄依赖
Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度图中需要对计算过程划分stage,而划分依据就是RDD之间的依赖关系。针对不同的转换函数,RDD在Lineage依赖方面分为两种窄依赖(Narrow Dependencies)与宽依赖(Wide Dependencies, 也称 shuffle dependency)用来解决数据容错时的高效性。
Narrow Dependencies:是指父RDD的每一个分区最多被一个子RDD的分区所用。表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。图中,map/filter和union属于第一类,对输入进行协同划分(co-partitioned)的join属于第二类。
Wide Dependencies:是指子RDD的分区依赖于父RDD的多个分区或所有分区,也就是说存在一个父RDD的一个分区对应一个子RDD的多个分区。对与Wide Dependencies,这种计算的输入和输出在不同的节点上,lineage方法对与输入节点完好,而输出节点宕机时,通过重新计算,这种情况下,这种方法容错是有效的,否则无效,因为无法重试,需要向上其祖先追溯看是否可以重试(这就是lineage,血统的意思),Narrow Dependencies对于数据的重算开销要远小于Wide Dependencies的数据重算开销。
如图所示:

容错
在RDD计算,通过checkpoint进行容错,做checkpoint有两种方式,一个是checkpoint data,一个是logging the updates。用户可以控制采用哪种方式来实现容错,默认是logging the updates方式,通过记录跟踪所有生成RDD的转换(transformations)也就是记录每个RDD的lineage(血统)来重新计算生成丢失的分区数据。
3.宽依赖与窄依赖之间的对比
相比于宽依赖,窄依赖对优化很有利 ,主要基于以下两点:
1.宽依赖往往对应着shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
2.当RDD分区丢失时(某个节点故障),spark会对数据进行重算。
(1)对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的;
(2)对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
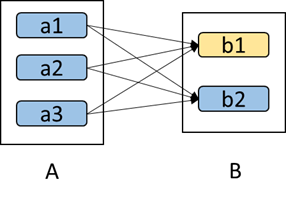
(3)如下图所示,b1分区丢失,则需要重新计算a1,a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)。
以下是文章 RDD:基于内存的集群计算容错抽象 中对宽依赖和窄依赖的对比。
区分这两种依赖很有用。
首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。
第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
【误解】之前一直理解错了,以为窄依赖中每个子RDD可能对应多个父RDD,当子RDD丢失时会导致多个父RDD进行重新计算,所以窄依赖不如宽依赖有优势。而实际上应该深入到分区级别去看待这个问题,而且重算的效用也不在于算的多少,而在于有多少是冗余的计算。窄依赖中需要重算的都是必须的,所以重算不冗余。
窄依赖的函数有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
宽依赖的函数有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy
参考:
1.什么是血统?
2.宽窄依赖的概念并画图?
3.RDD是如何容错的?容错方式有哪几种?默认是什么方式?如何容错?
4.窄依赖优于宽依赖的地方?
5.窄依赖的函数有?宽依赖的函数有?















 6607
6607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









