







一、哨兵机制高可用架构图
哨兵模式时给予主从模式的,是为了解决主从模式单点(master)故障导致服务不可用的问题,但并未解决单节点存储能力有限的问题。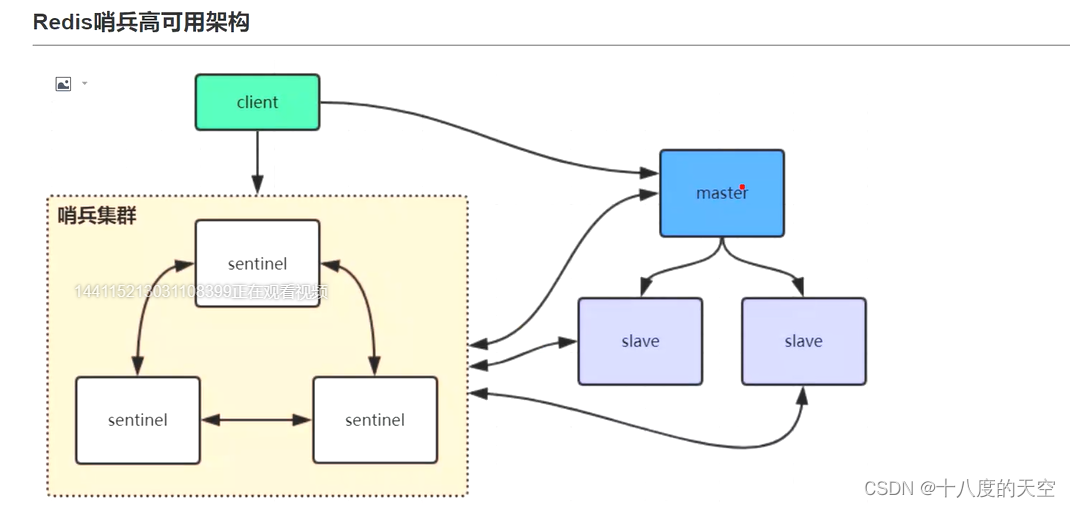
二、心跳检测机制
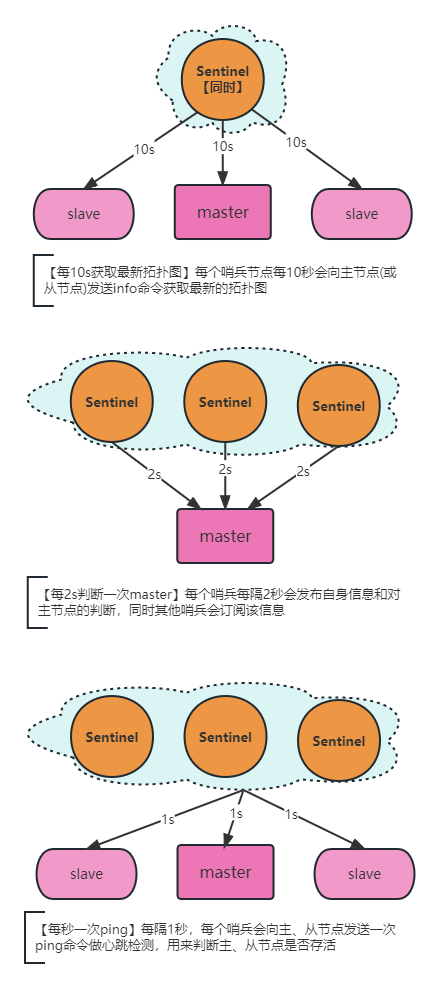
三、 选举机制
主观下线:主服务器master宕机后,哨兵1检测到这个结果,系统并不会马上进行failover,这仅仅是哨兵1认为主服务器不可用,这种现象称为主观下线。
客观下线:当其他哨兵也检测到主服务器master不可用且数量到达配置的值时,哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器切换成主服务器,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
- 当一个master服务器被sentinel视为下线状态后,sentinel之间会选举leader进行故障转移;
- 每个正常的sentinel都可以要求其他sentinel选自己作为leader,选举规则是先到先得;
- 同时,每个sentinel每次选举都会自增配置纪元(选举周期),每个纪元中只会选择一个sentinel的leader;
- 如果超过一半的sentinel选举了某个sentinel做leader,则该sentinel将会作为leader进行故障转移,从存活的slave中选出新的master的过程和集群的master选举类似。
- 哨兵选举leader的规则是:
(1)选择在线的节点,过滤掉已经下线的节点;
(2)选择响应速度快的,过滤掉响应慢的节点;
(3)选择与原master断开时间短的,过滤掉断开时间长的;
(4)以上优先级都一致时,选择偏移量较大的、runid偏大的。
哨兵集群选举:哨兵集群只有一个哨兵节点,redis的主从也能正常运行以及选举master,如果master挂了,那唯一的那个哨兵节点就是哨兵leader了,可以正常选举新master。 不过为了高可用一般都推荐至少部署三个哨兵节点。为什么推荐奇数个哨兵节点原理跟集群奇数个master节点类似。
四、故障转移机制
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









