







散列表
目前已知的查找方法:

但是上述这几种方法对于长字符串的动态查找效果都不是很好。看下面的例子:

可以看到二分法在这个问题中效果不是很好。那么如何快速搜索到需要的关键词?如果关键词不方便比较怎么办?
查找的本质:已知对象找位置
- 有序安排对象(将对象排列有序再查找):完全有序(二分查找,从小到大排好),半序(某些关键词中存在次序,比如查找树,某些节点的根节点比左边节点小,比右边节点大)
- 直接算出对象的位置:散列
散列查找法的两项基本工作:
- 计算位置: 构造散列函数确定关键词存储位置,对每个对象设计一个映射的整数值,整数值代表对象要放的位置
- 解决冲突:应用某种策略解决多个关键词位置相同的问题。即解决比如两个对象映射后放在同一个位置的问题
时间复杂度:几乎是O(1),与规模无关
散列表(哈希表)
表名,对象集,操作集如下

举例如下:

对于这个问题,用散列表来管理。将散列函数h选取为求余。TableSize=17,即将这些数字放到下标为0-16的表中。比如放34的时候,34对17求余,余数为0,h(34)=0,那么34放到0号位。
如果有35,h(35)=h(18)=1,冲突,此时要解决这一冲突。
将元素放好之后进行查找,如果要查找的key值是22,h(22)=5,就去表中5号位看是否存有值,如果没有,就说明22不在表中。
装填因子:

又有如下例子:

这次要存放长字符串,为了减少冲突采用二维数组,每个单词先放到对应行的第一列,如果有冲突就放到第二列。
针对这个例子如何设计散列函数h(key)?
一种简单的方法,看每个单词第一个字符,如果是a就放第一个位置,是b就放第二个,即:
h(key)=key[0]-‘a’
因为一共26个字母,所以根据该散列函数,设计数组规模为26*2
依次放入各个元素,当放到clock时发现产生了冲突,此时下标为2的行已经放了两个元素,放满了,ctime一样,如下图

可以看到,如果没有发生这种冲突,总体来说其查询,插入,删除的时间复杂度都是线性的
总结散列的基本思想:
(1)以关键字key为自变量,通过一个确定的函数h(散列函数),计算出对应的函数值h(key),作为数据对象的存储地址
(2)可能有不同的关键字映射到同一个散列地址:
即h(key i)=h(key j) (i不等于j),称为冲突,需要某种冲突解决策略。
散列函数的构造方法
散列函数的设计应考虑下面两个因素:
1.计算简单,以便提高转换速度
2.关键词对应的地址空间分布均匀,以尽量减少冲突
数字关键词的散列函数构造
1.直接定址法
把散列函数设计成一个线性函数,取关键词的某个线性函数值作为散列地址,即
h(key)=a*key+b (a、b均为常数)
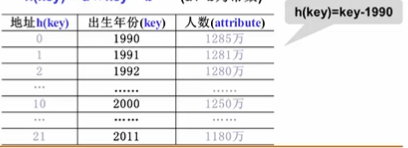
例如下图中h(key)=key-1990
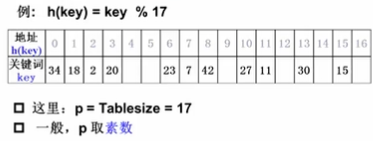
2.除留余数法
散列函数为:h(key)=key mod p
3.数字分析法
分析数字关键字在各位上的变化情况,取比较随机的位作为散列地址
如下面例子中,手机号码一般前几位都差不多,变化最大的是后四位,所以按如下方法选取


又如在身份证号码中,每一位都有特殊含义,对18位分析,得到第6,10,14,16,17这五位相对随机分布。所以把每个号码的这五位组合在一起组成一个数。具体按下图选取h(key)

4.折叠法
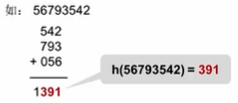
把关键词分割成位数相同的几个部分,然后叠加
如:下图把56793542三位三位拆分成三个数,并相加
5.平方取中法
将一个大数,先进行平方,然后取中间几位数。这种方法是为了令最终取的数能够被更多的位数所影响,如下图中如果只将56793452的最后一位2改成3,其平方取中法得到的值也会改变。

字符关键词的散列函数构造
1.ASCII码加和法
对每个字符串中每个字符的ASCII值简单加和,但是这样会发生很多冲突,而且ASCII在0-127变化,如果每个字符串很长的话效果也不好

2.前三个字符移位法
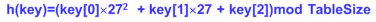
3.更好的方法:移位法
对所有字符都进行移位,全部转换为32进制的字符序列,计算公式如下图:

比如对字符串’abcde‘进行转换,字符e在32的0次方的位置,就是32的0次方+’e‘ 以此类推,a是32的4次方+’a‘ 这样算出来将结果加和
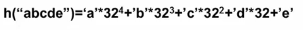
上式直接计算很麻烦,故采用下面的计算方法:
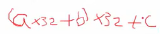
这里是从a开始算,a先乘32加上b,再乘32加上c,以此类推一直算到最后,就得到了上面移位法的结果。
其中由于32是2的5次方,所以每次乘32只需要将对应的数字左移五位即可。伪代码如下图:

其中Key是指针,Key是该指针指向的值。while()是判断Key当前指向的值是否为空(’\0’),不为空则逐位循环转换。h用来存储当前字符串的转换结果。
在这个例子中,一开始Key指向a,h初始为0,所以此时h左移5位还是0,再加上Key的ASCII值,也就是’a‘。这里加完之后h=’a‘
之后将Key++,Key指向下一位。此时进行第二次while循环。现在Key指向b,运算后h=‘a’<<5 +’b‘。每次左移5位相当于乘以32.以此类推,就实现了上面的计算方法。
冲突处理方法
常用思路有两种:
-
换个位置:开放地址法
-
映射到同一位置的冲突对象组织在一起放在一个链表中:链地址法
开放地址法(Open Addressing)
一旦产生了冲突(该地址已有其他元素),就按某种规则去寻找另一空地址。
首先散列函数算出一个值,代表该元素初始要放的位置,此时如果发生了第一次冲突,就在原地址上加一个di进行探测,发生第二次就再加di ,基本公式如下

di的设计方法主要有上图中三种方法:线性探测,平方探测,双散列
线性探测:
di=i
此时di就是一个线性函数,比如h现在发生了冲突,那么第一次探测,i=1,h就加上d1=1,如果还冲突,i=2,d2=2,h加上d2。第三次探测加上d3=3,也就是在原来的h的基础上一次一次+1,+2,+3。实际的效果就是从h当前的位置一个一个往后找。
平方探测(二次探测):
di=± i ²
这样每次di都取i平方,而且这里是正负i平方,所以往正方向探测一次,再往负方向探测一次。例如第一次通过散列函数找到h,发生冲突,就h加上1²,再有冲突,就到h减1平方的位置去找。再有冲突就到h加2平方位置找,再冲突就到h-2²处找。如果中间加减平方过程中超过了散列表的范围,就进行求余。
双散列:
即再设计一个散列函数h2(key),那么
di=i*h2(key)
第一个散列函数用于第一次探测,因为当i=1时,这里di=1h2(key)=h2(key).当i>1时为ih2(key)。这样设计也是为了控制第一次和后面的偏移量不同。
线性探测法(Linear Probing)
以增量序列1,2,…,(TableSize-1)循环试探下一个存储地址。
举例如下

首先放了47,再放7,接下来放29,29与7冲突,试探下一个,线性探测中下一个就是h+1,放在上图地址为8的位置。之后继续放,当插入84时,h=7,冲突,试探h+1,即地址为8处,发现与29冲突,再试探h+2,与9冲突。再试探h+3,成功。依次插入,整个过程如下。

注意聚集现象:如上图最后一行所示,从7开始,这里的冲突越来越多,发生聚集。
散列查找性能分析:
-
成功平均查找长度(ASLs)
-
不成功平均查找长度(ASLu)
仍对上面的例子进行性能分析,其ASLs和ASLu计算如下图:

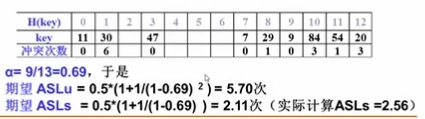
ASLs:首先从11开始,要查找11,因为上例是对11取余,所以要查找11也就是查找H(key)=0处,从上图的表中可以看到这里H(key)=0处冲突次数为0,也就是key=11就放在H(key)=0处。所以要查找11只需要比较一次就够了(即和H(key)=0处的key比较)。接下来要查找30。首先对11取余后从H(key)=8处开始找,发生冲突,从表中看出一共冲突了6次。所以要查找30需要比较7次(第一次是与H(key)=8处比较)。下一个47,也是一次就找到了没有冲突,所以比较次数也是1次。以此类推得到总的比较次数。因为一共有九个元素,再除以9就是成功平均查找次数。
ASLu:计算方法是把不在散列表中的元素分成若干类型。比如图中按照H(key)值分类。
首先从H(key)=0开始考虑,如果要查找如22,33这样能被11整除的数,就从H(key)=0作为入口开始找。比如要查找22,第一次在H(key)=0处比较,此时这里存的是11,不是22,但是查找没有结束,因为H(key)=0的下一个位置也有值,可能要查找的值是发生了冲突,放在了下一位。所以继续查找下一个位置,也就是H(key)=1处,这里存的30,也不是22,再继续下一个,H(key)=2,这个位置为空没有存数字,此时说明22不可能是因为发生冲突而后移了,22不存在。这里为了查找22一共前后比较了3次。要查找33,44这类数字,查找入口都是在H(key)=0处,要查找他们都需要比较3次。
接下来查找形如12,23这样对11取余为1的数,这些数字第一次都是在第一次在H(key)=1处比较,第一次没找到,向后一位,此时H(key)=2为空,查找结束,共比较2次。
接下来查找形如14,24这样的数。入口为H(key)=2,发现H(key)=2处本来就为空,查找结束。共比较1次。
继续这样查找。
注意:当查找形如18这样的数,即对11取余为7,首先在H(key)=7处查找,再到H(key)=8,9,10,11,12都没找到。但是这里并没有结束,因为18还有可能因为冲突而移位到表的另一头。所以H(key)=12后继续到表头和H(key)=0比较,没找到,再和H(key)=1,2比较,直到H(key)=2处为空,查找结束。这里共查找了9次。
这里因为是对11取余,所以一共可能出现11种情况,即余数分别为0,1,2,3,4,5,6,7,8,9,10.所以ASLu是将总的不成功查找长度除以11.

再次举例如下:

这里散列函数取的是每个字符串第一个字符减去a的ASCII,也就是减去’a‘作为散列值。采用线性探测。
前五个字符串都直接放入。第六个atan发生冲突,错位放入。依次将所有元素放入。
之后计算ASLs,前五个都没发生冲突,一次查到,atan冲突1次,共查找1+1次。ceil冲突4次,共查找4+1=5次。以此类推。最后一共8个数,除以8.得到结果
计算ASLu,首先分情况,分为以a,b,c …共26种情况(26个字母),H值为0,1,2…按上述方法算出结果如图
平方探测法(Quadratic Probing)–二次探测
- 平方探测法:以增量序列1²,-1²,2²,-2²…q²,-q²且q≤TableSize/2(向下取整)循环试探下一个存储地址。
举例如下:

首先对11求余得到上图中的散列地址。接下来进行插入。首先47,7的插入都没问题,到29时,插入7,冲突,+1²,查到8处。之后继续。直到插入20时,±1²都不行,试探到+2²,也就是表中地址为2处,可以,插入。

计算ASLs时,将每个元素的冲突次数加1即为每个元素的查找次数。都加起来除以元素个数即为结果。
由于平方探测是跳跃式探测的,并不是每个位置都能探测到,是否存在有空间但是平方探测找不到的情况?
举例如下:

例中的散列函数是对5求余,此时已经插入了5,6,7,当要插入11时,可以看到探测时始终在0和2两个位置之间跳来跳去,始终找不到4和5两个空位。
这是二次探测的缺陷。但是二次探测相比线性探测的优势在于能在一定程度上避免聚集现象。
有如下结论:

平方探测伪码实现:
散列表初始化:
首先如下图右侧所示,散列表设计成一个结构体,里面有两个分量,第一个分量是int型的TableSize,第二个分量是数组*TheCells,TheCells是指向数组的指针。

初始化散列表时,首先判断如果散列表太小的话就没必要做成散列表,直接放到数组里即可。判断之后用malloc()申请空间。申请成功之后用NextPrime()得到一个比表的尺寸更大的素数作为TableSize(上面定理已经证明只有TableSize是素数时平方探测法才能探测到整个空间,所以要找到一个比TableSize大的素数,比如本来TableSize是12,那么找到的素数就是13,并将13作为新的TableSize)。
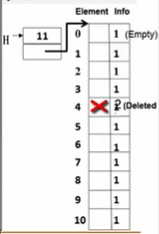
接下来根据算出的新的TableSize申请空间并令TheCells指向该空间。如下图所示,黄色部分就是TheCells指针,黄色部分上面的11即TableSize。TheCells指向的是一个结构数组,其中Element用来存储每个位置的值,Info用来表示该位置的状态。在初始化时Info都置1表示该位置为空(empty)

Info在删除元素起作用。对于散列表,要删除元素并不能真的将这个元素删掉,那么后续的查找就会出现问题。所以删除某个元素就通过对该位置的Info做记号表示删除。这样在查找时,查找到这个元素就会知道这里不是空位,是被删掉了,所以要继续查找下一个值。在插入时找到这里也会知道这里只是被删除了,不是空位,所以插入的元素就能替代原来这里被删掉的元素。这就使得插入和删除操作都能正常进行并且不影响查找。
平方探测Find()伪代码

首先调用散列函数hash()计算出散列值,也就是要找的元素所放的位置CurrentPos。之后通过while()寻找。while()的循环条件:当前位置是否为空,如果不空的话这个位置的Info!=Empty,同时判断这个位置的Element值是否等于要找的值Key.如果这个位置不空且其Element值不等于要找的key就继续找,继续执行循环。
探测的方法就是在最早算出的元素的位置CurrentPos上加或减i的平方进行探测。这里通过if()中的++CNum%2来判断冲突的奇偶次,从而判断是该加还是减i的平方。CNum初始为0.例如在某次探测中,首先++CNum,此时CNum为1,之后对2求余,为1,此时加上1的平方,如果不是就减去1的平方。
那么这里为什么不是直接加减i的平方而是加减(CNum+1)/2,CNum/2的平方?
从上图下面的表格可以看到,因为Cnum是每循环一次都+1,而i(即di)是+1²,-1²,+2²,-2²,+3²,-3²…这样连续两个1,2,3的平方,所以要找一个映射,把Cnum映射到di,如果是基数,就是图中红色标出来的地方:
当i为奇数时,也就是1,3,5时,如果是1的时候,Cum也为1,(1+1)/2=1,3的时候(3+1)/2=2,5的时候(5+1)/2=3,可以看到与di一一对应。
当i为偶数时,也就是减的情况,在这个表中就是Cum取2,4,6,代入计算后也与di一一对应。
此时已经求出了加上增量后的NewPos,但是还可能出现加上增量后的NewPos太大或太小,超过了表的范围TableSize,所以通过两个while()判断,前一个while用来判断如果大到超过了表的范围,就对其减去TableSize,直到值符合while()的条件,即小于表的范围为止。另一个while()也一样,用于解决NewPos减去增量后为负数的情况。
插入Insert()伪代码

Find()找到了插入的位置Pos。这里首先判断这个Pos的状态,如果其Info!=Legitimate,也就是这一位置不处于被占用的状态(即这个位置是空位或者被删除了),此时就可以被插入。
这里首先把该位置Info设置成被占用的状态,再把值插进去。
注意散列表中的删除操作是一种懒惰删除:
即要删除一个元素并不是真的将其删除,只是加一个标记表示被删除,这样在查找时不会断链,该空间也可以被重用。
双散列探测法(double Hashing)
此时di是I*h2(key),而h2(key)是另一个散列函数,此时得探测序列如下图所示.
注意对于任意的key,这里的h2(key)均不为0
一般h2(key)按照下图方式选取计算方法较好

再散列(Rehashing)
- 当散列表元素太多(即装填因子a太大)时,查找效率会下降,此时把散列表的规模扩大。那么此时原来散列表的元素不能单纯拷贝到新表中,必须重新计算位置,再依次放入新表。这就是再散列。

分离链接法(Separate Chaining)
核心思想是将冲突的元素都放在同一个单链表中。
比如2号位置有三个元素都冲突,即这三个元素一开始都指向2号位置,就构建一个链表放入这三个元素,并有一个指针指向2号位置。
举例如下:

此时散列表的每个结构数组不用来存元素,而是用来存指针,比如图中22和11哈希值都为0,就放在同一个链表中。比如位置2处没有元素,存指针处就是null
这种方法的ASLs计算如上图所示
分离链接法伪代码实现:

首先构建结构体ListNode,此时Positon存储位置指针Next。
Find()中整体结构和前面的差不多,TheLists是一个数组,首先通过Hash()算出要找的元素在TheLists数组中的位置,上图中红色手绘部分就是结构为ListNode的数组TheList。例如hash()算出的位置就是图中划小红圈处,此时将该地址赋给L,再将L的Next赋值给P,在图上标出了,此时P指向单向链表的第一个元素。
接下来是典型的单向链表遍历循环while(),条件是只要P不等于Null且P指向的元素不是要找的键值key,P就一直向下寻找。最终循环退出来时要么是P便利了整个链表,指向空,要么是找到了要找的元素。最后return P。
散列表的性能分析
主要从以下几个方面分析:

- 线性探测法的性能
可以证明他的期望满足下面的公式:

将该公式代入前面的例子,可以算出其ASLu和ASLs的期望:
可以看到和实际计算值相差不多。
- 平方探测法和双散列探测法的性能
可以证明他们的期望满足下面的公式:

- 期望探测次数与装填因子a的关系

- 分离链接法的性能

散列查找特点总结
- 只要选择了合适的h(Key),散列查找的搜索效率和数据规模无关,基本是常数O(1) 也适用于关键字直接计算量比较大的问题,比如字符串的管理
- 散列查找的效率是以较小的装填因子a为前提的。即散列查找是一种空间换时间的方法
- 散列查找的存储对关键字是随机的,不便于顺序查找关键字,也不适合范围查找,最大最小值查找
开放地址法的特点:
散列表是一个数组,存储效率高,随机查找。去诶但是会发生聚集现象
分离链接法特点
散列表是顺序存储和连式存储的结合,链表部分的存储,查找效率比较低,且装载因子比较大时该方法查找效率会下降;但是关键字删除不需要使用懒惰删除,从而没有存储垃圾
应用举例:文件中单词词频统计
采用散列表进行实现,具体伪代码如下:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









