




 本文详细介绍了Spark的StandAlone集群模式,包括集群角色解析——master和slave,集群规划,如节点配置,以及如何修改和分发配置文件。接着,文章阐述了启动和停止集群的步骤,并提供了测试集群运行wordcount程序的方法。强调在集群模式下,程序应读取HDFS文件而非本地文件。
本文详细介绍了Spark的StandAlone集群模式,包括集群角色解析——master和slave,集群规划,如节点配置,以及如何修改和分发配置文件。接着,文章阐述了启动和停止集群的步骤,并提供了测试集群运行wordcount程序的方法。强调在集群模式下,程序应读取HDFS文件而非本地文件。
StandAlone集群模式的介绍与部署
集群角色介绍
Spark是基于内存计算的大数据并行计算框架,实际中运行计算任务肯定是使用集群模式,那么就需要了解spark自带的standalone集群模式的架构以及它的运行机制
stand alone集群模式使用了分布式计算中的master - slave模型
master是集群中含有master进程的节点
slave是集群中worker节点含有Executor进程
Spark架构图如下:
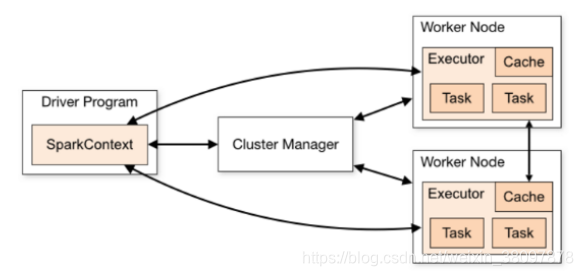
Apache对spark架构的官方描述:http://spark.apache.org/docs/latest/cluster-overview.html
集群规划
节点1:master
节点2:slave/worker
节点3:slave/worker
修改配置并分发
- 修改spark配置文件
进入spark解压路径的conf目录:cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf/
拷贝spark-env.sh.template并修改名称为spark-env.sh:cp spark-env.sh.template spark-env.sh - 修改并添加配置
#配置java环境变量
export JAVA_HOME=${JA 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









