







本文将以天池的一道赛题入手,详细介绍数据挖掘的步骤,实际操作性强。
适合人群:想入门数据挖掘,入门数据挖掘类比赛,熟悉python,pandas,Numpy等库运用性选手
本文的结构为:
- 准备工作(赛题的报名、数据的下载等。。。)
- 数据挖掘赛题的理解
- 数据探索性分析
1.准备工作
该赛题是关于二手车交易价格预测
赛题网址:
https://tianchi.aliyun.com/competition/entrance/231784/information
大家可以在上面网址下载训练和测试数据
2.数据挖掘赛题的理解
数据准备好之后,就开始要理解赛题。就像我们考试一样,需要仔细审题。这里的数据哇据赛题的理解需要明确目标是什么,是分类问题还是回归问题?
这些信息会直接对后面的特征工程、模型选择以及评分体系都会有很大的影响。因为分类和回归的问题用到的模型和评分标准是完全不一样的。有什么区别呢?
分类算法常见的评估指标如
下:
- 对于二类分类器/分类算法,评价指标主要有accuracy, [Precision,Recall,F-score,Pr曲线],ROC-AUC曲线
- 对于多类分类器/分类算法,评价指标主要有accuracy, [宏平均和微平均,F-score]
回归常用的评价标准为:
平均绝对误差(Mean Absolute Error,MAE),均方误差(Mean Squared Error,MSE),平均绝对百分误差(Mean Absolute Percentage Error,MAPE),均方根误差(Root Mean Squared Error), R2(R-Square)等
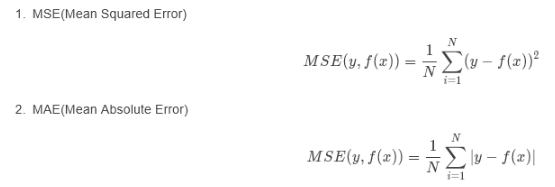
分类指标评价实例
## accuracy
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 1, 0, 1]
y_true = [0, 1, 1, 1]
print('ACC:',accuracy_score(y_true, y_pred))
# ACC: 0.75
## Precision,Recall,F1-score
from sklearn import metrics
y_pred = [0, 1, 0, 0]
y_true = [0, 1, 0, 1]
print('Precision',metrics.precision_score(y_true, y_pred))
print('Recall',metrics.recall_score(y_true, y_pred))
print('F1-score:',metrics.f1_score(y_true, y_pred))
# Precision 1.0
# Recall 0.5
# F1-score: 0.6666666666666666
## AUC
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
print('AUC socre:',roc_auc_score(y_true, y_scores))
# AUC socre: 0.75
回归性指标实例
# coding=utf-8
import numpy as np
from sklearn import metrics
# MAPE需要自己实现
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true))
y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])
y_pred = np.array([1.0, 4.5, 3.8, 3.2, 3.0, 4.8, -2.2])
# MSE
print('MSE:',metrics.mean_squared_error(y_true, y_pred))
# RMSE
print('RMSE:',np.sqrt(metrics.mean_squared_error(y_true, y_pred)))
# MAE
print('MAE:',metrics.mean_absolute_error(y_true, y_pred))
# MAPE
print('MAPE:',mape(y_true, y_pred))
## R2-score
from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
print('R2-score:',r2_score(y_true, y_pred))
针对这个二手车价格预测的赛题,很明显是典型的回归问题
以下为题目所有提供的特征:
name - 汽车编码
regDate - 汽车注册时间
model - 车型编码
brand - 品牌
bodyType - 车身类型
fuelType - 燃油类型
gearbox - 变速箱
power - 汽车功率
kilometer - 汽车行驶公里
notRepairedDamage - 汽车有尚未修复的损坏
regionCode - 看车地区编码
seller - 销售方
offerType - 报价类型
creatDate - 广告发布时间
price - 汽车价格
v_0’, ‘v_1’, ‘v_2’, ‘v_3’, ‘v_4’, ‘v_5’, ‘v_6’, ‘v_7’, ‘v_8’, ‘v_9’, ‘v_10’, ‘v_11’, ‘v_12’, ‘v_13’,‘v_14’(根据汽车的评论、标签等大量信息得到的embedding向量)【人工构造 匿名特征】
3.数据探索性分析
数据的探索性分析,先大致了解一下数据的大致分布,数据的类型,挖掘出离群点,分离出重要的特征等
3.1 首先以简单粗暴的方式查看具体数据,例如可以用pandas.head()方法,查看前几列数据,用pandas.info()查看数据的类型和数据量,用describe()查看数据的极值,均值、方差等统计指标。
- pandas.head()

- pandas.info()

- pandas.describe()

- pandas.columns()
 3.2 其次,再高阶一点的方式,可以进行可视化分析,如果是回归问题可以看是否有明显时序变化,分布是否符合要求,因为很多模型都要求变量之间独立同分布(正态分布),需要进行变量转换,例如对变量取对数等
3.2 其次,再高阶一点的方式,可以进行可视化分析,如果是回归问题可以看是否有明显时序变化,分布是否符合要求,因为很多模型都要求变量之间独立同分布(正态分布),需要进行变量转换,例如对变量取对数等
3.2.1 查看缺失值情况

# nan可视化
missing = train_data.isnull().sum()
missing = missing[missing > 0]
missing.sort_values(inplace=True) # 排序
print(missing)
missing.plot.bar()

# 可视化看下缺省值
import missingno as msno
msno.matrix(train_data.sample(250))

msno.bar(train_data)

测试集的缺省和训练集的差不多情况, 可视化有四列有缺省,notRepairedDamage缺省得最多
3.2.2 查看异常值检测
train_data.info() 可以发现除了 notRepairedDamage 为object类型其他都为数字 这里我们把他的几个不同的值都进行显示就知道了
## 2) 查看异常值检测
train_data['notRepairedDamage'].value_counts()
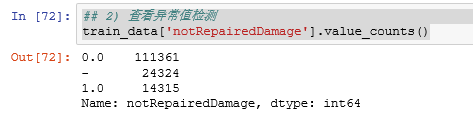
# 可以看出来‘ - ’也为空缺值,因为很多模型对nan有直接的处理,这里我们先不做处理,先替换成nan
train_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
train_data['notRepairedDamage'].value_counts()
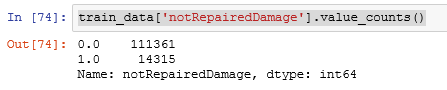
- v_0变量测试数据和训练数据是否同分布

3.3 最后,还需要对各个变量进行相关性和独立性分析,而不同类型的变量需要采用不同的相关性分析方法,数值型和类别变量分析方法不同















 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









