






1. 基本概念
主备集群是由主库、备库和守护进程组成的集群,主库提供数据库读写服务,备库和主库通过流复制同步数据作为备份,守护进程检查各个数据库状态以及环境状态,当主库故障后可以进行故障转移将备库提升为主库继续对外提供服务,确保主备集群持续提供服务。
1.1数据库模式
KingbaseES 只有两种数据库模式:主库 primary 或备库 standby。
主库 primary
提供正常的数据库读写服务,能正常生成 WAL 日志,如果有备库 standby 连接此数据库,还能将本地生产 WAL日志传输给备库。
备库 standby
提供只读服务,不能生成 WAL 日志,可以连接某一个主库 primary,从主库接收 WAL 日志并重做。
1.2 WAL(REDO 日志)
REDO 日志在 KingbaseES 数据库系统中一般指 WAL(Write-Ahead Logging,预写式日志),其是保证数据完整性的标准解决方案——任何对数据页面的修改都必须先记录 WAL 并持久化到存储上。
WAL 中按顺序记录了所有对数据页面的修改,每一条修改记录称为一条 Record。一个事务包含至少一条 SQL语句,而一条 SQL 会记录一条或多条 record。事务提交时只需要保证将 WAL 从内存写入磁盘就可以完成,而不需要保证所有更改的数据文件都写入磁盘。 WAL 是按顺序写入文件,而数据文件的更改大部分是随机位置,所以 WAL写入磁盘的成本更低,这种方案减少了事务提交时磁盘写入的次数,提高了事务并发性能。
当数据库系统发生崩溃后,可以读取磁盘中的 WAL 并按顺序重放日志来恢复数据文件,保证了数据的可靠性。
1.3 witness 节点
witness 节点,也称为仲裁节点、观察节点,应用不访问此节点,此节点主要作为集群故障自动切换时的仲裁。witness 是集群中的特殊节点,其不提供数据库服务,主要是为了避免由于网络隔离导致的误切换,同时在极端场景下辅助进行故障自动切换。
2.主备集群
2.1 主要功能
流复制同步数据
应用连接主库更改数据,主库生成 WAL 日志并写入磁盘,同时主库的 walsender 进程实时从存储读取 WAL 日志并通过数据流的方式发送给备库,备库接收到 WAL 日志流后写入存储并 REDO。通过同步 WAL 日志的方式,主备数据达到一致。
数据库状态监控
守护进程会实时监控主备集群的状态,包括主库、备库状态、流复制状态等。发生任何故障时,守护进程实施合适的措施以保证主备集群能够持续的对外提供服务。
VIP 管理
VIP 又叫浮动 IP、虚拟 IP,集群在发生故障转移、主备切换等事件时, VIP 始终跟随主库。应用程序使用 VIP访问数据库,可以尽量减少某些故障对应用的影响。
故障自动转移
守护进程监控到主库故障后,自动选择一个备库将其提升为主库,继续对外提供服务。
故障自动恢复
守护进程监控到备库故障后,不影响主库对外提供服务,同时尝试将备库自动恢复正常。
2.2 主备的同步流程
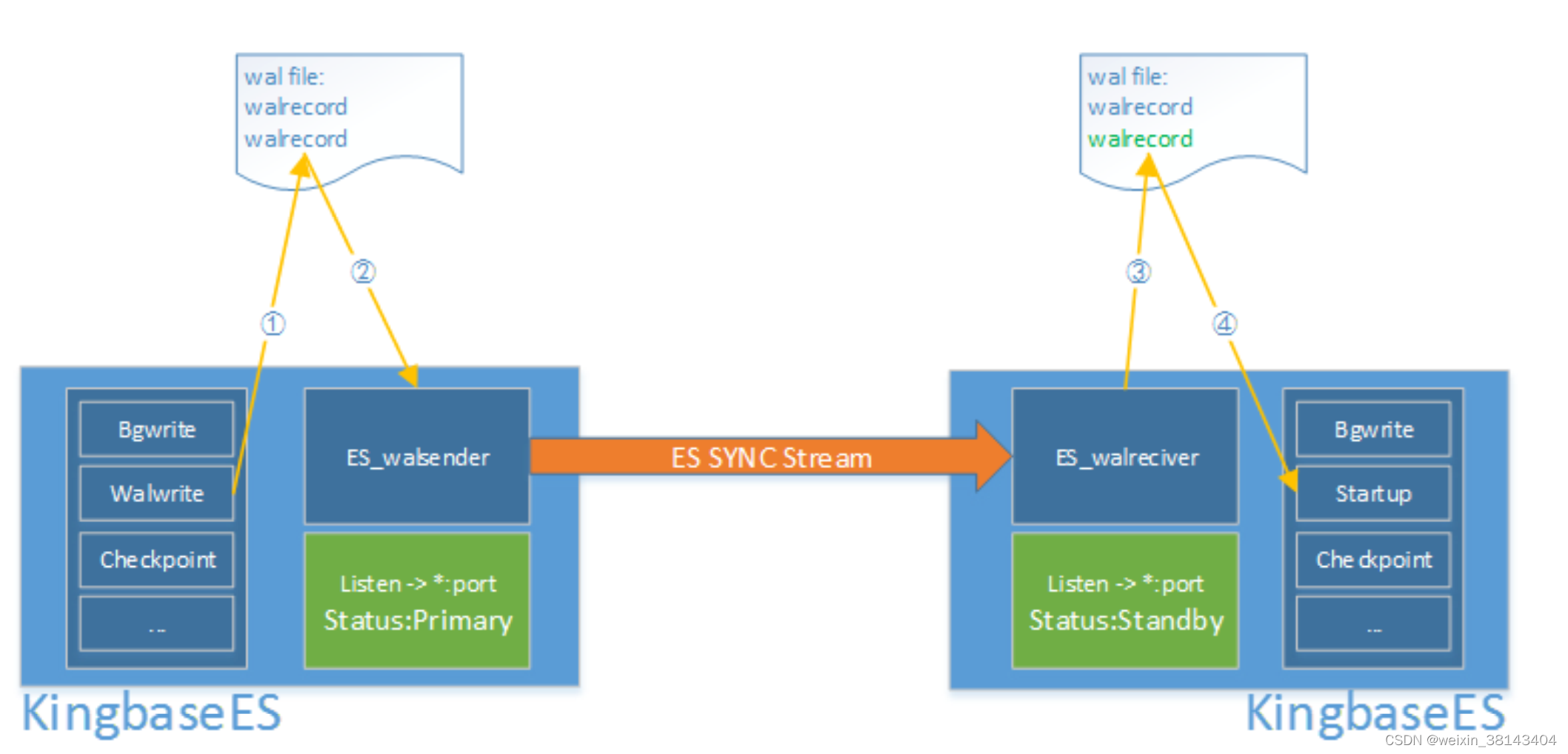
流程说明
数据库 WalWriter 把产生的 WAL 日志写入磁盘;
WAL 日志写入磁盘后,由 walsender 进程将新增的日志读取出来并通过流的形式发送给备库;
备库 walreceiver 进程将接收到的 WAL 日志写入本地 WAL 段文件;
备库 startup 进程读取 WAL 日志进行重放,完成数据同步。
3.集群组件与功能介绍
3.1守护进程
每个数据库节点有一个 repmgrd 守护进程,主节点的 repmgrd 只监视本地数据库,备节点的 repmgrd 会同时监控本地数据库和主数据库。所有节点的状态信息存在 repmgr.nodes 表里,并通过流复制同步到所有备节点。
每个数据库节点都有一个 kbha 守护进程,其主要监控并守护 repmgrd 进程,同时对环境进行监控,包括:磁盘状态、信任网关状态。
监控主库
主节点 repmgrd 每隔 monitor_interval_secs(默认 2s)会检查一次本地数据库是否可连接;备节点的 repmgrd每隔 monitor_interval_secs(默认 2s)会检查本地数据库和主数据库是否可连接。
检查失败后,备库会尝试重连主库,重连尝试失败则会触发备库的切换动作。控制重连次数和重连尝试间隔的参数为 reconnect_attempts 和 reconnect_interval,这两个参数代表着第一次检查失败后,最多执行 econnect_attempts 次的重连尝试,每两次尝试间隔 reconnect_interval 秒。
监控备库
位于备库上的 repmgrd 监控进程的监控循环,会检查本地数据库是否可连接。
主库的 repmgrd 进程检查备库状态,是通过从主库查询 sys_stat_replication 视图直接调取流复制状态来判断备库是否正常。 sys_stat_replication 视图只在主库上才有数据,视图中的每条记录对应一个主库的 walsender 进程,主备库之间的流复制连接由主库端的 walsender 进程和备库端的 walreceiver 进程建立,因此 sys_stat_replication 视图中的每一条记录都对应了一条主备间的流复制连接。
3.2进程保护
守护进程 repmgrd 主要是监控集群并保障处理集群中的故障,包括:故障转移、故障恢复、 VIP 管理等。高可用设计的前提是软件不是百分百可靠的,所以一旦 repmgrd 进程故障后,集群中数据库遇到故障便无法处理,集群高可用能力就失效了。为了保护守护进程 repmgrd,守护进程 kbha 通过 repmgr_pid_file 文件监控 repmgrd 进程状态,一旦发现 repmgrd 进程不存在,会尝试启动 repmgrd 进程,时间间隔为 3 秒左右。
而守护进程 kbha 则由操作系统的 crond 定时服务负责启动,定时任务会每分钟尝试启动一次 kbha 进程。
这两点分别保证了守护进程 kbha 和 repmgrd 的高可用。
3.3故障自动恢复
主库所在节点的 repmgrd 进程通过流复制监控其他数据库状态,一旦发现其他数据库对应的流复制断开,则认为该数据库异常,经过 reconnect_attempts 次检查,每次间隔 monitor_interval_secs(默认 2 秒),如果数据库的流复制仍然断开,可以认为数据库故障。
根据自动恢复参数 recovery 配置为不同值,采取不同措施:
1) manual,手动恢复,不处理数据库故障。
2) standby,仅当故障数据库为备库时才处理,如果是故障主库,则不处理。
3) automatic,任何故障数据都处理。
当主库上的守护进程 repmgrd 认为数据库故障后,如果故障数据库(根据配置)能够处理,就会准备开始执行故障自动恢复。开始执行故障自动恢复前,会等待 auto_recovery_delay(默认 20 秒),在此期间,也会不断检测流复制。如果在此期间故障数据库成功和主库建立流复制,则认为该数据库重连成功,中断自动恢复流程;否则,等待时间结束后,开始自动恢复故障备库。
故障自动恢复流程:
1) 主库的 repmgrd 进程远程到故障数据库调用 kbha -A rejoin 开始恢复。
2) 尝试连接故障数据库:连接成功则查询故障数据库状态,如果为主库则中断恢复流程,如果为备库则关闭数据库,并进行下一步;连接失败,直接下一步。
3) 通过 pid 文件和共享内存检测数据库是否成功关闭:如果 pid 对应进程存在或共享内存正在使用,中断恢复流程;否则,直接下一步。
4) 执行 sys_rewind 修改故障数据库文件,使得故障库数据和主库保持一致。
5) 配置流复制连接,在主库建立复制槽,然后启动故障数据库。
6) 将故障数据库注册为备库,并更新状态。
7) 恢复结束。
3.4网络断开
网络故障是最容易造成脑裂的故障,特别是主库或备库的网络断开,如果不能正确的知道是否为本节点的网络故障,容易造成脑裂。为了能够识别网络故障, KingbaseES 引入了” 信任网关(trusted_servers) ” 的概念,守护进程kbha 通过判断和信任网关的连通性来判断本机是否出现了网络故障。
检测信任网关的方法:命令”ping -c3 -w2 ${IP}” 来不断探测信任网关(trusted_servers)的连通性,当 ping 所有的信任网关 IP 都返回异常时,认为信任网关异常,再次尝试,最多尝试 reconnect_attempts 次,如果每次都异常,那么就认为网络故障。
集群异常时,如果主库故障,在进行故障自动转移的升主流程中,第一步就会通过以上方法检测信任网关来判断网络状态:如果确认网络故障,则会中断流程,故障自动转移失败;如果网络正常,那么正常升主。故障自动转移成功后,新主库为了预防网络问题,会自动探测集群其他节点状态,尝试关闭其他主库。
集群状态正常时,守护进程 kbha 会不断通过以上方法检测信任网关。当确认网络故障后, kbha 会自动关闭守护进程 repmgrd, kbha 会接管 repmgrd 负责的部分功能。
3.5外部存储故障
当数据库数据目录对应的外部存储故障后,数据库的数据以及 WAL 可能无法正常写入或读取,会造成不可预知的风险。所以,集群需要能够检查存储并及时处理。
集群的守护进程 kbha 负责此功能:
1) 每隔 60 秒检查一次存储;
2) 在 mount_point_dir_list 配置的路径下进行检查,如果此参数等于””,则默认在 data_direcotry 路径下做检查;
3) 检查方式:查看目录、创建临时文件、向临时文件写入 8KB 数据、从临时文件读取 8KB 数据,删除临时文件;
4) 检查中任意项失败则认为集群异常,重试 mount_check_max_retries。
每次重试间隔 10 秒
如果重试过程中,检查无问题,则重置重试次数,恢复正常检查。
如果重试完,检查仍然异常,认为磁盘故障。
4.主备集群访问
4.1数据库配置
可通过配置服务名的方式实现API程序访问集群,连接服务名可以在金仓提供的JDBC及OCI等接口中使用。sys_service.conf文件中服务名配置参考如下
通过这种配置就可以达到多主机地址连接,并区分主备机。
host=配置多个地址,使用逗号分隔,驱动处理时会按顺序连接,直到有一个成功并符合target_session_attrs条件并返回。
pqopt=配置其它扩展参数,使用大括号包围,中间用空格分隔。
其它扩展参数解释:
target_session_attrs=read-write 表明只返回可读写的节点连接,即主机连接,如果不满足会继续尝试下一个地址,默认是any即主备都可以。
connect_timeout=5 表示连接超时时间,单位是秒,最少2秒,默认10秒,如果多个地址,就是总和。
tcp_user_timeout=3000 表示TCP报文的等待ACK的最大等待时间,单位是毫秒,默认是0,即没有限制,根据操作系统配置来。
[mdb]
host=198.168.1.1,198.168.1.2
dbname=ems
port=54321
UsePackage=1
UseHa=0
RetryN=25
UpperUser=1
BatchInsertSise_Ext=1
pqopt={target_session_attrs=read-write connect_timeout=5 tcp_user_timeout=3000}

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









