







Hadoop学习笔记—Yarn
@(Hadoop)[hadoop, yarn]
[TOC]
上一份工作主要负责大数据平台的建设,在这个过程中积累了一些Hadoop生态组件的搭建和使用笔记,由于时间关系,不打算去修改其中的错别字和排版问题,直接释出原始笔记。
一些基本知识
ResourceManager 的恢复
当ResourceManager 挂掉重启后,为了使之前的任务能够继续执行,而不是重新执行。势必需要yarn记录应用运行过程的状态。
运行状态可以存储在
- ZooKeeper
- FileSystem 比如hdfs
- LevelDB
使用zookeeper做为状态存储的典型配置为
<property>
<description>Enable RM to recover state after starting. If true, then
yarn.resourcemanager.store.class must be specified</description>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<description>The class to use as the persistent store.</description>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<description>Comma separated list of Host:Port pairs. Each corresponds to a ZooKeeper server
(e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002") to be used by the RM for storing RM state.
This must be supplied when using org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
as the value for yarn.resourcemanager.store.class</description>
<name>hadoop.zk.address</name>
<value>127.0.0.1:2181</value>
</property>Resource Manager的HA
基于zookeeper实现active 和standby 的多个ResourceManager之间的自动故障切换。 active Resource Manager只能有一个,而standby 可以有多个
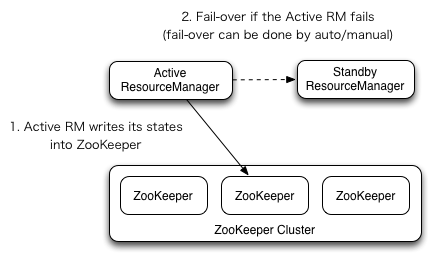
为了防止故障自动转移时的脑裂,推荐上面的ResourceManager recovery 状态存储使用也使用zk。 同时关闭zk的zookeeper.DigestAuthenticationProvider.superDigest配置,避免zk的管理员访问到YARN application/user credential information
一个demo配置如下
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<property>
<name>yarn.resourcemanager.web 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1146
1146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









