






前言
1. 特征处于数据与模型中间环节,特征工程是将数据转化为可传入到模型的格式;好的特征能够简化模型难度,提高模型质量。
2. 仅了解特征处理的工作机制以及用途是不够的 - 人们还必须理解为什么是这样设计的,与其他技术的关系以及每种方法的优缺点。
3. 本文没有讲述音频数据使用傅里叶分析,以及目前比较新的研究思路,如随机投影;复杂的文本特征化模型,如word2vec和Brown聚类;潜在的空间模型,如Latent Dirichlet分配和矩阵分解。(有空儿扩展一下)
第一章(机器学习流程)
1. Data:各种类型、来源各异,存在大量noise。
2. Tasks:使用data达到什么样的目的
3. Models:数学模型解决任务
4. Features:原始Data的数字表示形式;好的特征旨在解决任务,能够更好地适应模型;特征数量影响模型训练,太少精度可能不够,太多模型训练复杂
5. Model Evaluation:特征的好坏直接影响模型的复杂性。
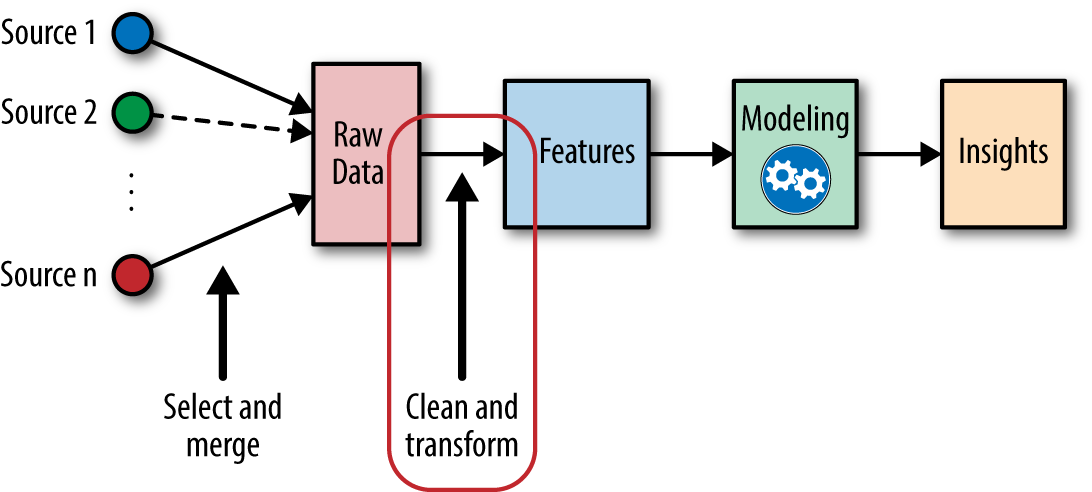
第二章(数字格式特征提取)
1. 首先,需要查看数据完整性、正负、粗粒度;
其次,考虑scale数据,查看最大最小值是否差很多数量级。那些利用欧式距离的算法(k-means,knn等)一般需要归一化,但是逻辑方程、决策树、梯度提升器、随机森林等一般不需要scale(累计型特征可能需要)。
再次,考虑数据的分布。例如训练线性规划模型,模型误差属于高斯分布,但是预测结果差很多数量级,此时模型不再适应,需要将目标进行log转换(power transform)。
最后,考虑特征组合,将不同特征进行组合生成更好的特征;特征选择,一般使用模型进行自动选择。
2. 处理累加数据
1)二值化:数据插值很大,将>1赋值为1,其余等于0
2)量化或分档:
固定宽度分级:将数据划分多档,比如年龄,根据档位将数据依次划分。np.floor_divide(small_counts, 10),将small_counts均匀划分成10档;
分位数分级:若数据分布不均,固定宽度分级会存在一些空档。pd.qcut(large_counts, 4, labels=False),将large_counts等分为四部分;large_counts_series.quantile([0.25, 0.5, 0.75]),得到的是分位数值
Log Transformation:np.floor(np.log10(large_counts)),使用log转换
Power Transforms(广义Log Transformation): 属于方差稳定转化。Box-Cox transform,要求数据为正数,若存在非正数,可以加常值,通常需要确定Lambda(最大似然估计、贝叶斯),from scipy import stats,rc_log = stats.boxcox(biz_df['review_count'], lmbda=0);rc_bc, bc_params = stats.boxcox(biz_df['review_count'])
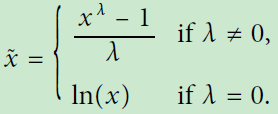
概率图可以直观地比较数据的经验分布与理论分布。prob1 = stats.probplot(biz_df['review_count'], dist=stats.norm, plot=ax1),与正态分布作比较。
3. 特征缩放与归一化(当不同特征量级不同时,使用缩放效果会更好):
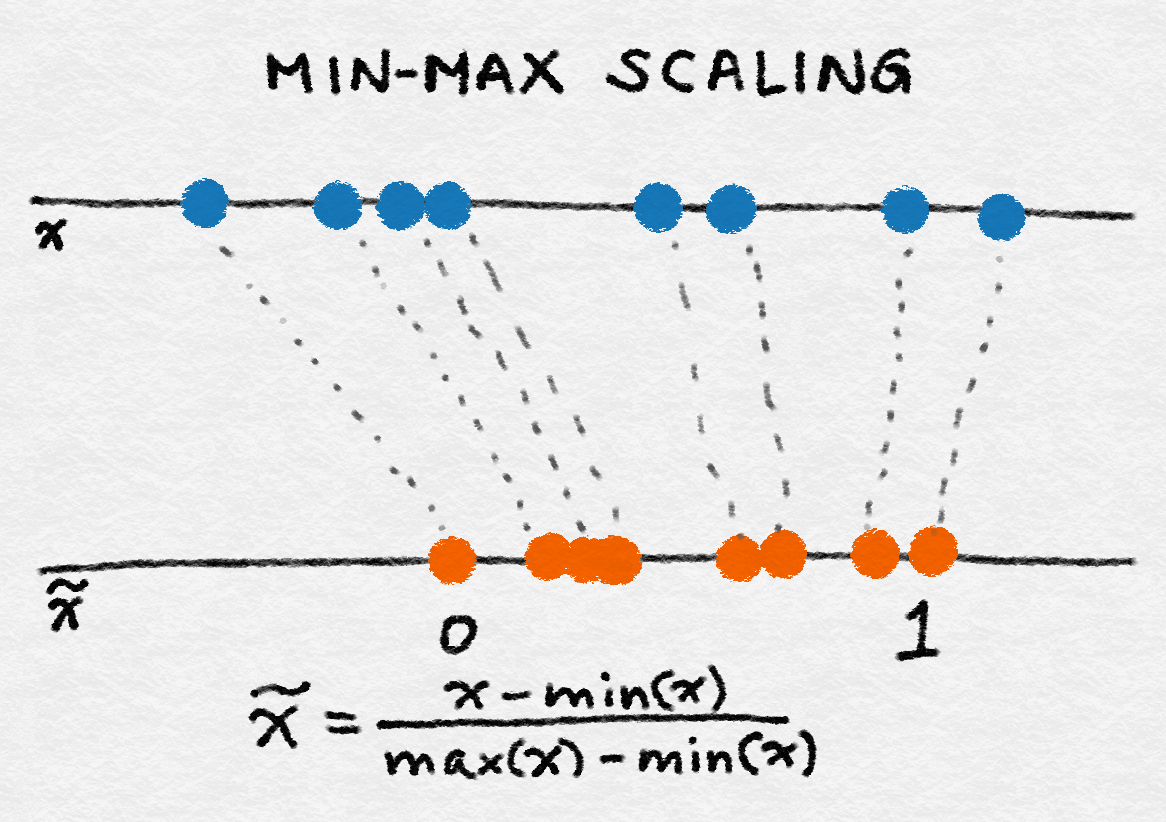
1)Min-Max Scaling:
2)Standardization (Variance Scaling)
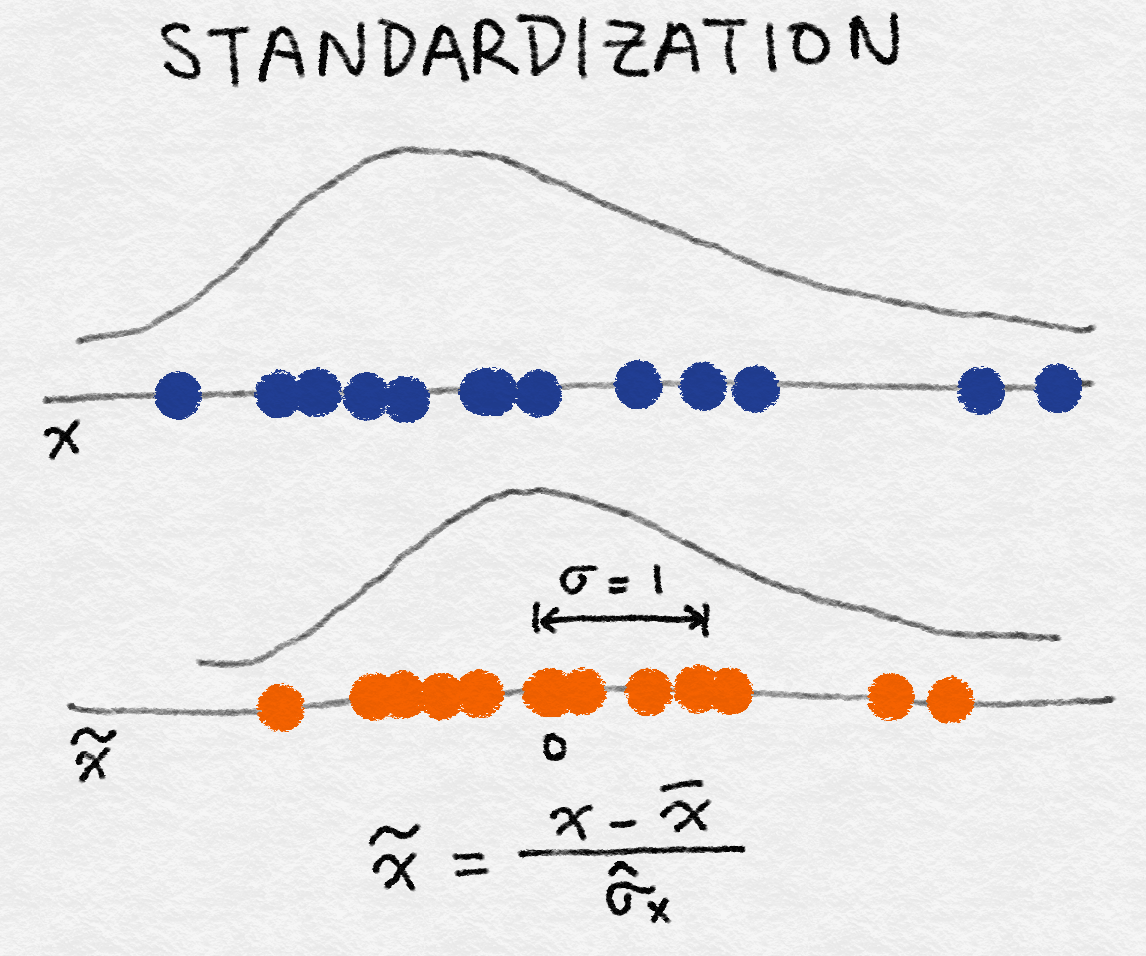
注意:不能将原来的稀疏数据进行上述操作,会将稀疏数据转化为稠密数据,计算量增加
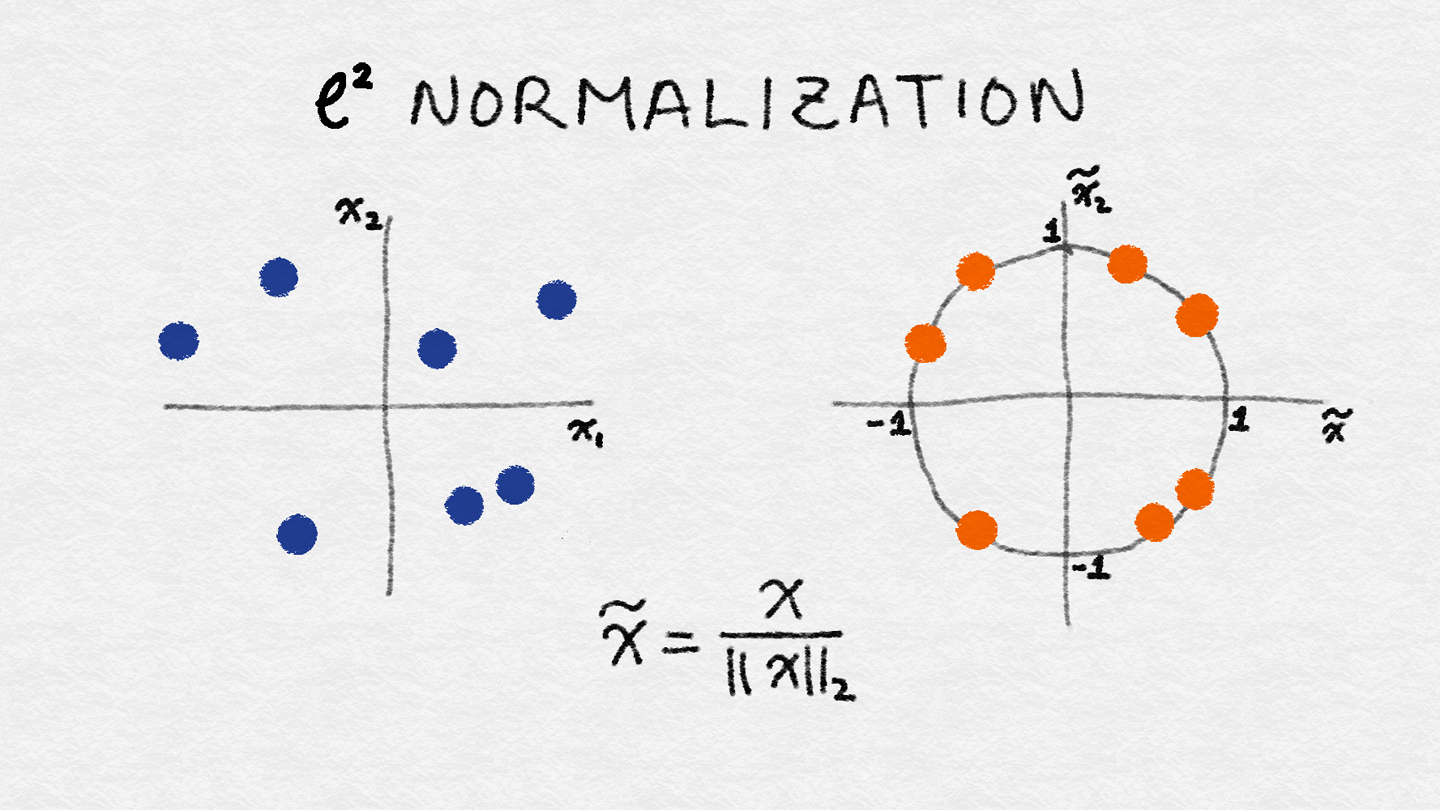
3)ℓ2 Normalization:
4. Interaction Features:
不同特征之间进行相乘或逻辑运算,但是这可能会造成分类器计算量增加。
5. 特征选择:
在不降低精度的前提下,筛选出最好的特征集合。有以下三种方式:
1)滤波:
计算各特征与label之间的相关性或互信息,预选出超出特定阈值的特征。但是,选出的特征未必合适,剔除那些必然无关的特征。
2)Wrapper methods:
是一种比较昂贵的方法,独立评价各子集特征,不会删除那些与其他特征组合表现好的特征。
3)Embedded methods:
属于模型训练的一部分,相比于滤波不会有误删特征的危险,比wrapper methods 计算量要少,可以说是质量与计算量之间的均衡。ℓ1正则化(稀疏约束)有助于特征的选择。















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









