






第一.java领域对象传输
1.1基于socket对象进行传输案例:
User
public class User {
private String name;
private String age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
@Override
public String toString() {
return "User{" + "name='" + name + '\'' + ", age='" + age + '\'' + '}';
}
}
SocketServerProvider
public class SocketServerProvider {
public static void main(String[] args) throws Exception{
ServerSocket serverSocket = new ServerSocket(8081);
Socket socket = serverSocket.accept();
ObjectInputStream ois = new ObjectInputStream(socket.getInputStream());
User user = (User) ois.readObject();
System.out.println(user);
}
}
SocketClientConsumer
public class SocketClientConsumer {
public static void main(String[] args) throws Exception{
Socket socket = new Socket(InetAddress.getLocalHost(),8081);
User user = new User();
user.setAge("23");
user.setName("张三");
ObjectOutputStream oos =
new ObjectOutputStream(socket.getOutputStream());
oos.writeObject(user);
oos.close();
}
}
运行结果报错
解决报错,就是对 User 这个对象实现一个 Serializable 接口,再次运行就可以看到对象能够正常传输了
public class User implements Serializable {
private String name;
private String age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
@Override
public String toString() {
return "User{" + "name='" + name + '\'' + ", age='" + age + '\'' + '}';
}
}
序列化的意义:
1.Java 平台允许我们在内存中创建可复用的 Java 对象,但一般情况下,只有当 JVM 处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比 JVM 的生命周期更长。但在现实
应用中,就可能要求在 JVM 停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。
2、按值将对象从一个应用程序域发送至另一个应用程序域。实现serializabel接口的作用是就是可以把对象存到字节流,然后可以恢复,所以你想如果你的对象没实现序列化怎么才能进行持久化和网络传输呢,要持久化和网络传输就得转为字节流,所以在分布式应用中及设计数据持久化的场景中,你就得实现序列化。
序列化是把对象的状态信息转化为可存储或传输的形式过程,也就是把对象转化为字节序列
的过程称为对象的序列化
反序列化是序列化的逆向过程,把字节数组反序列化为对象,把字节序列恢复为对象的过程
成为对象的反序列化
第二.序列化的认识
2.1java原生序列化
java.io.ObjectOutputStream:表示对象输出流 , 它的 writeObject(Object obj)方法可以对参数指定的 obj 对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream:表示对象输入流 ,它的 readObject()方法源输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回
需要注意的是,被序列化的对象需要实现 java.io.Serializable 接口
2.2了解serialVersionUID
字面意思上是序列化的版本号,凡是实现 Serializable 接口的类都有一个表示序列化版本标识符的静态变量
演示步骤
1. 先将 user 对象序列化到文件中
2. 然后修改 user 对象,增加 serialVersionUID 字段
3. 然后通过反序列化来把对象提取出来
4. 演示预期结果:提示无法反序列化
代码案例:
public class User implements Serializable {
private static final long serialVersionUID = 975638943886175071L;
private String name;
private String age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
@Override
public String toString() {
return "User{" + "name='" + name + '\'' + ", age='" + age + '\'' + '}';
}
}
/**
* 接口
*/
public interface ISerializer {
<T> byte[] serialize(T obj);
<T> T unserialize(byte[] data);
}
public class JavaSerializerWithFile implements ISerializer {
/**
* 序列化写入文件
* @param obj
* @param <T>
* @return
*/
@Override
public <T> byte[] serialize(T obj) {
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(new FileOutputStream("user"));
oos.writeObject(obj);
} catch (Exception ioe) {
ioe.printStackTrace();
} finally {
if (oos != null) {
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return new byte[0];
}
@Override
public <T> T unserialize(byte[] data) {
ObjectInputStream ois = null;
try {
ois = new ObjectInputStream(new FileInputStream("user"));
return (T) ois.readObject();
} catch (Exception ioe) {
ioe.printStackTrace();
} finally {
if (ois != null) {
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return null;
}
}
public class SerializeTestDemo {
public static void main(String[] args) {
User user = new User();
user.setAge("23");
user.setName("张三");
ISerializer iSerializer = new JavaSerializerWithFile();
//序列化
// byte[] serialize = iSerializer.serialize(user);
//反序列化
User unserialize = iSerializer.unserialize(null);
System.out.println(unserialize);
}
}
结论:
Java 的序列化机制是通过判断类的 serialVersionUID 来验证版本一致性的。在进行反序列化时,JVM 会把传来的字节流中的 serialVersionUID 与本地相应实体类的 serialVersionUID 进
行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是 InvalidCastException。
从结果可以看出,文件流中的 class 和 classpath 中的 class,也就是修改过后的 class,不兼容了,处于安全机制考虑,程序抛出了错误,并且拒绝载入。从错误结果来看,如果没有为指定的 class 配置 serialVersionUID,
那么 java 编译器会自动给这个 class 进行一个摘要算法,类似于指纹算法,只要这个文件有任何改动,得到的 UID 就会截然不同的,可以保证在这么多类中,这个编号是唯一的。所以,由于没有显指定 serialVersionUID,
编译器又为我们生成
了一个 UID,当然和前面保存在文件中的那个不会一样了,于是就出现了 2 个序列化版本号不一致的错误。因此,只要我们自己指定了 serialVersionUID,就可以在序列化后,去添加一个字段,或者方法,而不会影响到后期的还原,还原后的对象照样可以使用,而且还多了方法或者属性可以用。
tips: serialVersionUID 有两种显示的生成方式:
一是默认的 1L,比如:private static final long serialVersionUID = 1L;
二是根据类名、接口名、成员方法及属性等来生成一个 64 位的哈希字段
当实现 java.io.Serializable 接口的类没有显式地定义一个 serialVersionUID 变量时候,Java 序
列化机制会根据编译的 Class 自动生成一个 serialVersionUID 作序列化版本比较用,这种情况
下,如果 Class 文件(类名,方法明等)没有发生变化(增加空格,换行,增加注释等等),就算
再编译多次,serialVersionUID 也不会变化的。
2.3Transient 关键字
Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是0,对象型的是 null。
绕开 transient 机制的办法
虽然 name 被 transient 修饰,但是通过我们写的这两个方法依然能够使得 name 字段正确被序列化和反序列化
writeObject 和 readObject 原理writeObject 和 readObject 是两个私有的方法,他们是什么时候被调用的呢?从运行结果来
看,它确实被调用。而且他们并不存在于 Java.lang.Object,也没有在 Serializable 中去声明。我们唯一的猜想应该还是和 ObjectInputStream 和 ObjectOutputStream 有关系,所以基于
这个入口去看看在哪个地方有调用
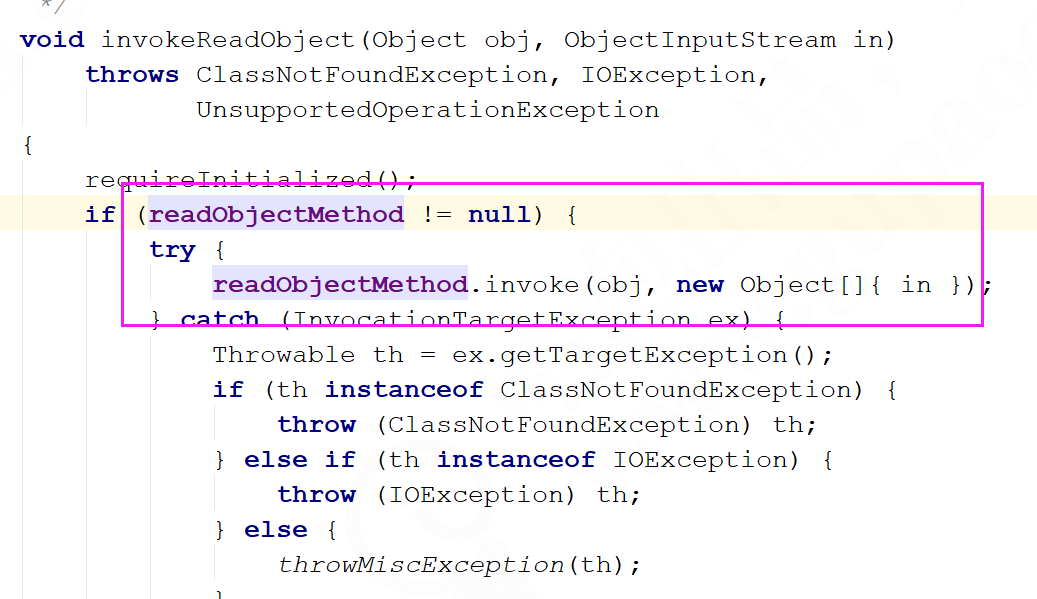
从源码层面来分析可以看到,readObject 是通过反射来调用的。
其实我们可以在很多地方看到 readObject 和 writeObject 的使用,比如 HashMap。
代码案例:
public class User implements Serializable {
private static final long serialVersionUID = 975638943886175071L;
private transient String name;
private String age;
public String getName() {
return name;
}
private void writeObject(java.io.ObjectOutputStream s) throws IOException {
s.defaultWriteObject();
s.writeObject(name);
}
private void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException {
s.defaultReadObject();
name=(String)s.readObject();
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
@Override
public String toString() {
return "User{" + "name='" + name + '\'' + ", age='" + age + '\'' + '}';
}
}
/**
* 接口
*/
public interface ISerializer {
<T> byte[] serialize(T obj);
<T> T unserialize(byte[] data);
}
public class JavaSerializer implements ISerializer {
/**
* 序列化到内存
* @param obj
* @param <T>
* @return
*/
@Override
public <T> byte[] serialize(T obj) {
ByteArrayOutputStream baos =null;
ObjectOutputStream oos = null;
try {
baos = new ByteArrayOutputStream();
oos = new ObjectOutputStream(baos);
oos.writeObject(obj);
return baos.toByteArray();
} catch (Exception ioe) {
ioe.printStackTrace();
} finally {
if(oos!=null){
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return new byte[0];
}
/**
* 从内存中读取
* @param data
* @param
* @param <T>
* @return
*/
@Override
public <T> T unserialize(byte[] data) {
ByteArrayInputStream bais = null;
ObjectInputStream ois = null;
try {
bais = new ByteArrayInputStream(data);
ois = new ObjectInputStream(bais);
return (T) ois.readObject();
} catch (Exception ioe) {
ioe.printStackTrace();
} finally {
if(ois!=null){
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return null;
}
}
public class TransientTest {
public static void main(String[] args) {
User user = new User();
user.setAge("23");
user.setName("张三");
ISerializer iSerializer = new JavaSerializer();
//序列化
byte[] serialize = iSerializer.serialize(user);
//反序列化
User unserialize = iSerializer.unserialize(serialize);
System.out.println(unserialize);
}
}
2.4Java 序列化的一些简单总结
1. Java 序列化只是针对对象的状态进行保存,至于对象中的方法,序列化不关心
2. 当一个父类实现了序列化,那么子类会自动实现序列化,不需要显示实现序列化接口
3. 当一个对象的实例变量引用了其他对象,序列化这个对象的时候会自动把引用的对象也进行序列化(实现深度克隆)
4. 当某个字段被申明为 transient 后,默认的序列化机制会忽略这个字段
5. 被申明为 transient 的字段,如果需要序列化,可以添加两个私有方法:writeObject 和readObject















 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









