







1、部署准备
Hadoop生态可以分成以下几部分:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
Hadoop集群主要由分布式文件系统(HDFS)和分布式资源管理系统(YARN)构成。
HDFS集群中的角色:NameNode、Secondary NameNode、DataNode。
YARN集群中的角色:ResourceManager、NodeManager、MapReduce Job History、Web App Proxy Server。
软件环境
每个主机使用版本一致的软件环境。
操作系统:Linux System;Ubuntu 22.04.2 LTS
软件环境:pdsh-2.31 (+debug)、OpenSSH_8.9p1、Java version "1.8.0_371"、Hadoop 3.3.5
用户环境:本案例没有使用单独的账户,默认使用root账户配置和运行。
主机规划
| 主机名 | IP | 系统版本 | Java版本 | Java安装路径 | Hadoop版本 | 角色 |
| Hadoop01 | 2.2.2.11 | Ubuntu22.04.2 | 1.8.0_371 | /usr/lib/jvm/jdk1.8.0_371 | 3.3.5 | NameNode、ResourceManager |
| Hadoop02 | 2.2.2.12 | Ubuntu22.04.2 | 1.8.0_371 | /usr/lib/jvm/jdk1.8.0_371 | 3.3.5 | DataNode、NodeManager |
| Hadoop03 | 2.2.2.13 | Ubuntu22.04.2 | 1.8.0_371 | /usr/lib/jvm/jdk1.8.0_371 | 3.3.5 | DataNode、NodeManager |
2、配置要点
网络环境
1、配置/etc/hosts;加入IP和主机名解析关系,注释localhost和ipv6相关条目。
2、防火墙放通相应通信端口或关闭防火墙。
Java环境配置
Java1.8下载地址:Java Downloads | Oracle
Linux安装Java1.8参考:Install Oracle Java Development Kit 8 on Linux - Java Helps
配置完成后,输出验证:
root@hadoop01:# java -version
java version "1.8.0_371"
Java(TM) SE Runtime Environment (build 1.8.0_371-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.371-b11, mixed mode)
SSH环境配置
安装pdsh,用于批量启动和管理节点。
sudo apt install pdsh
配置SSH公钥登录(在管理主机上配置无需密码访问其他节点主机,便于从一台机器通过pdsh管理其他机器)
生成公私密钥对:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
root@hadoop01:~/.ssh# cat id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQCuHaxKGsLMZDulTZBmZBJ6Vf/4Br/8gX88lcEE+GFH/oTaOhg9stdFwdkgQ/SdlEOKfsDoYfESrgIgPrRYoJlbp5MzSDgAqYdGaRATK/XYqDI07UqLIUrjcPns4m+GNORfKbQD+TTp2k52Al1y+hmgypJWCWR8UQLCydzVJkhBAT8BGO4jjZWoqypPNsLrz00Gi+kO1vcrOCuKlFy61e6o84lMCqtngcfN0FcTF8cV5VJgS0D2YTx9qgV758P0deBKtlE3p9Fc/pDO6tfrphWIiIpkanR1IRKem50rK0sK/ynIIma9VBO6efyp7tgfoFlfmiRkQMAEpq3Tp/PaovIOXuUnJ7dG0VfKJVhrhkvPulYp7//hLXASj44m6Zui8Y40L9t1fCvpH9t1xc7EiBgHZibUIjfOatWHyibBNAXrSVz+y9R5/CpTc59Jpi3PlDtdjx8OEPu0V8ma4f51HbwBFlOndPgKCJFUqXRmQ2MyjkC2MfZC+8cPPlymuvTuHUU= root@hadoop01
将以上公钥内容添加到本机及其他主机/root/.ssh/authorized_keys文件下。尝试连接,若无需输入验证信息即配置成功。
在$hadoop_home/etc/hadoop/workers下,添加主机IP
root@hadoop01:/hadoop-3.3.5/etc/hadoop# cat workers
2.2.2.11
2.2.2.12
2.2.2.13
Hadoop环境配置
下载Hadoop软件包:Index of /hadoop/common
解压缩到某个路径并确保目录权限足够。
根据之前分配的主机角色,编写配置文件并把配置文件加入对应主机。
以下是本案例使用的配置文件,仅供参考,更多参数配置请参考官网说明。
Core-site.xml (for all hosts)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://2.2.2.11:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<valu1>131072</valu1>
</property>
</configuration>NameNode-hdfs-site.xml (for namenode hosts)
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/namenode/dfs</value>
</property>
<property>
<name>dfs.hosts</name>
<value>/usr/namenode/knowhosts</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
</configuration>DataNode-hdfs-site.xml (for datanode hosts)
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/datanode/dfs</value>
</property>
</configuration>以上是部署HDFS需要使用到的配置文件。
以下是部署YARN需要使用到的配置文件。
ResourceManager-yarn-site.xml (for ResourceManager hosts)
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>flase</value>
</property>
<property>
<name>yarn.admin.acl</name>
<value>*</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>flase</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address </name>
<value>hadoop01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>CapacityScheduler</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
</configuration>NodeManager-yarn-site.xml (for NodeManager hosts)
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>flase</value>
</property>
<property>
<name>yarn.admin.acl</name>
<value>*</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>flase</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>-1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<vlaue>true</vlaue>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/hadoop/nodemanagerdir</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/usr/hadoop/nodemanagerlog</value>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/usr/hadoop/nodemanagerlog</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>MapApp-mapred-site.xml (for MapReduce Applications hosts or MapReduce JobHistory Server)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<vlaue>yarn</vlaue>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<vlaue>1536</vlaue>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<vlaue>-Xmx1024M</vlaue>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<vlaue>3072</vlaue>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<vlaue>-Xmx2560M</vlaue>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<vlaue>512</vlaue>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<vlaue>100</vlaue>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies </name>
<vlaue>50</vlaue>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<vlaue>hadoop01:10020</vlaue>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<vlaue>hadoop01:19888</vlaue>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<vlaue>/mr-history/tmp</vlaue>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<vlaue>/mr-history/done</vlaue>
</property>
</configuration>运行集群
可以单独启动,或使用脚本自动启动。
初始化NameNode主机
$HADOOP_HOME/bin/hdfs namenode -format
脚本启动HDFS集群:
$HADOOP_HOME/sbin/start-dfs.sh
脚本启动YARN集群:
$HADOOP_HOME/sbin/start-yarn.sh
验证结果
默认服务端口

查看HDFS集群状态
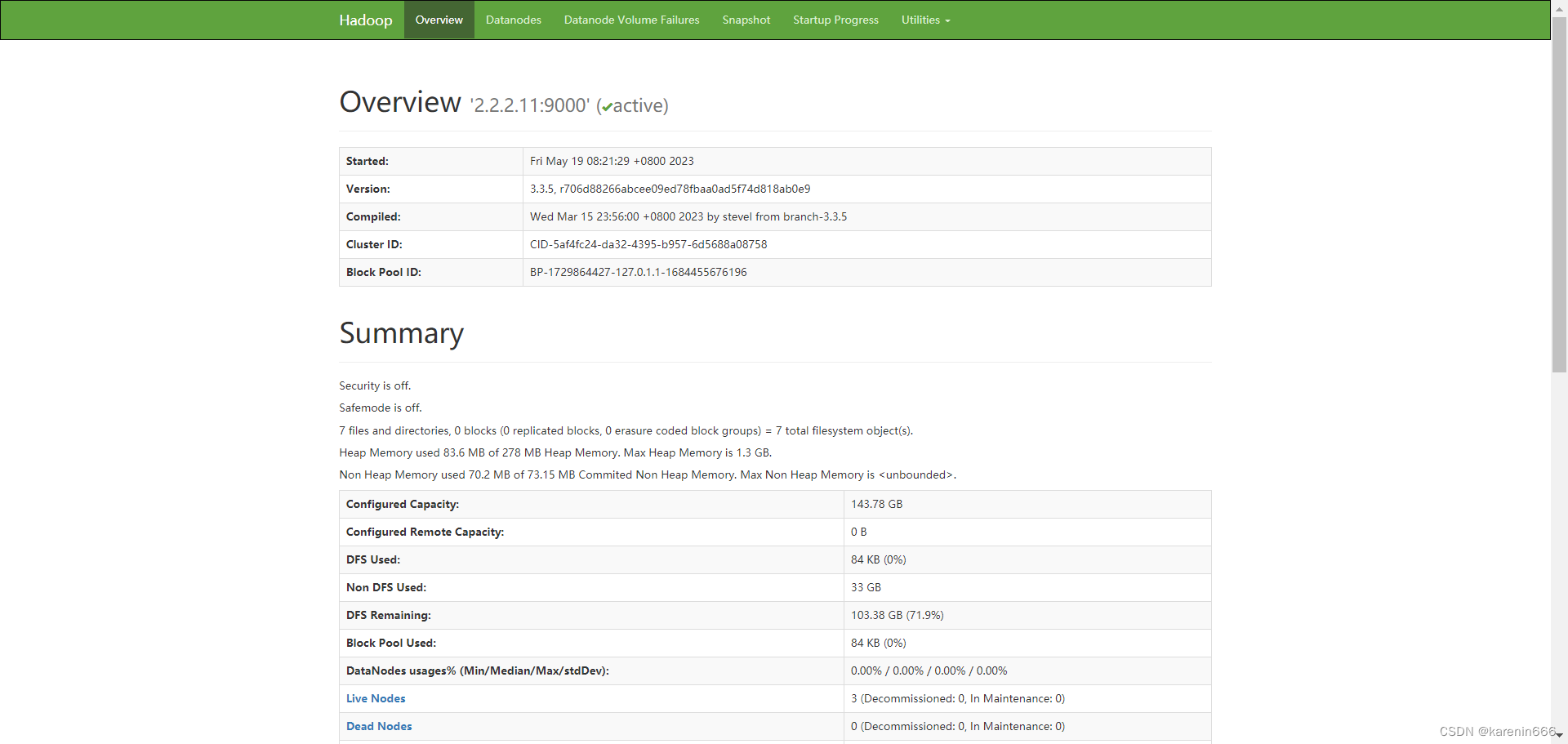
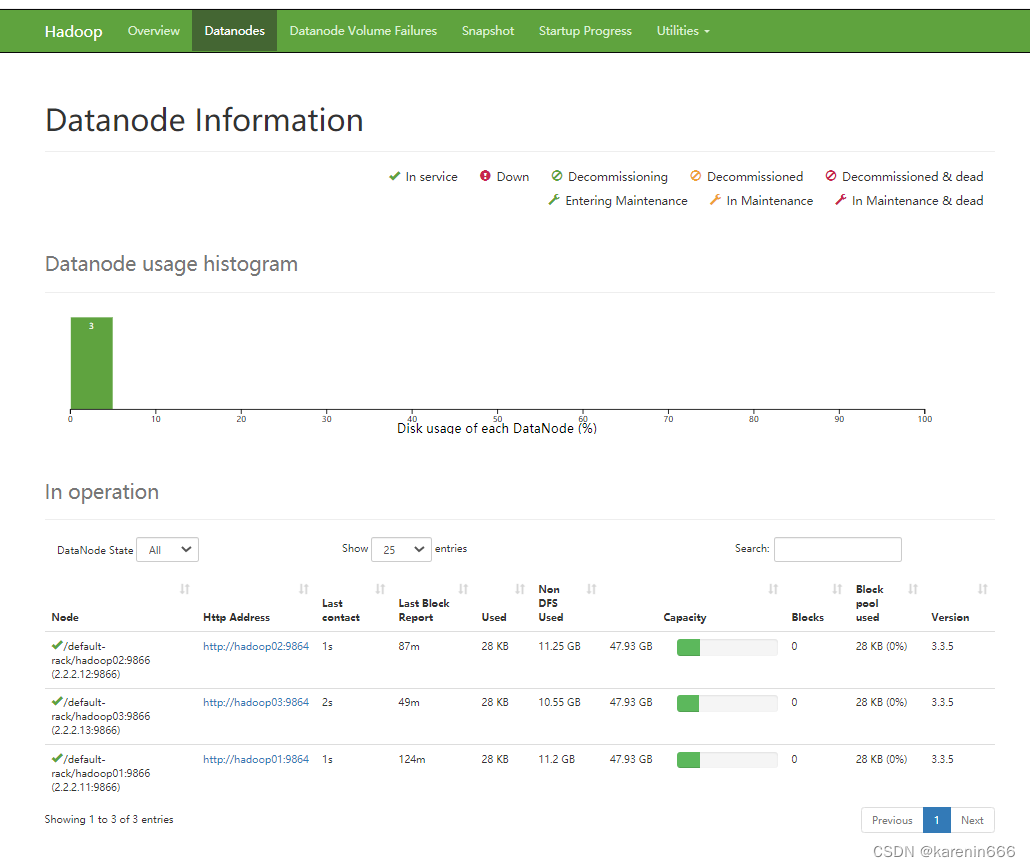
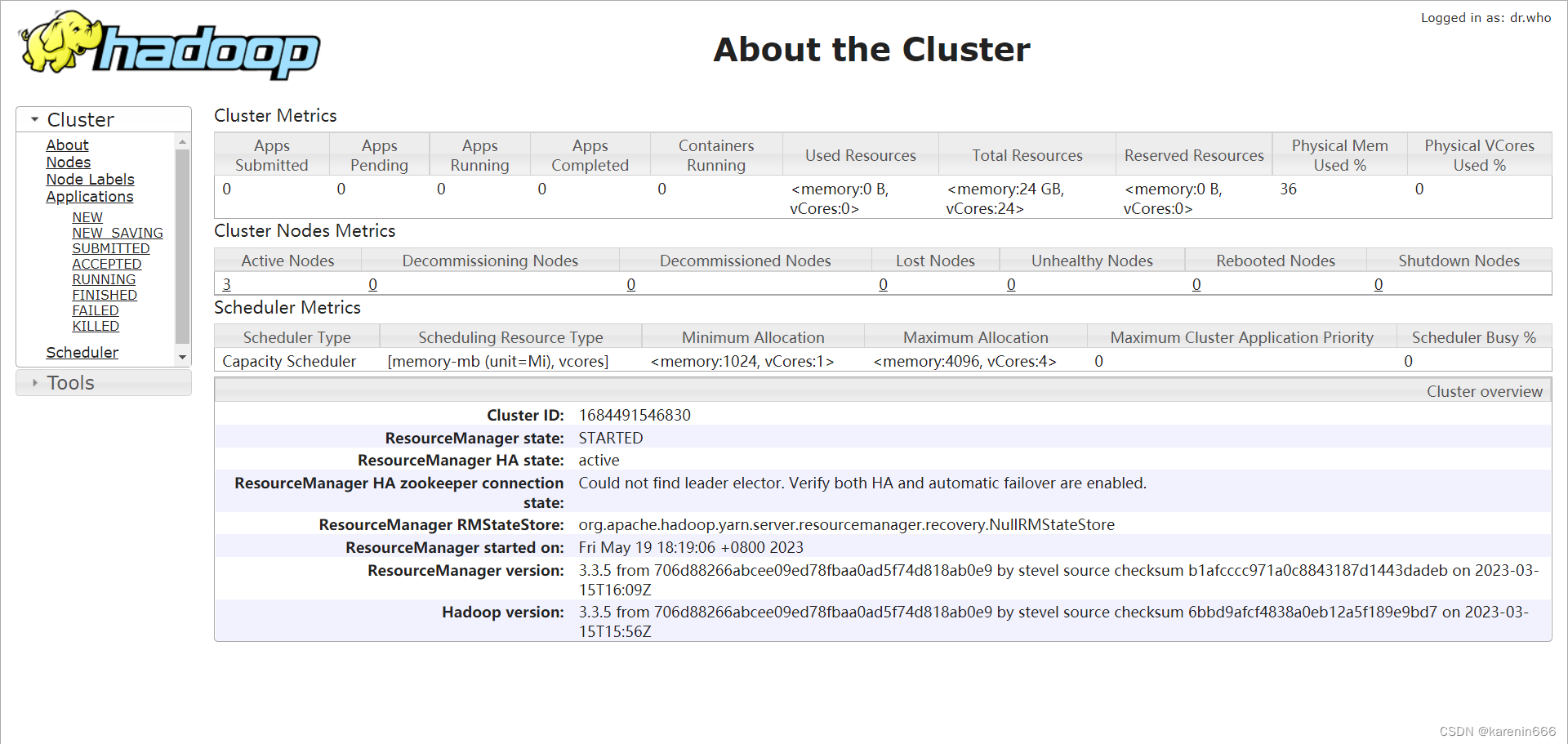
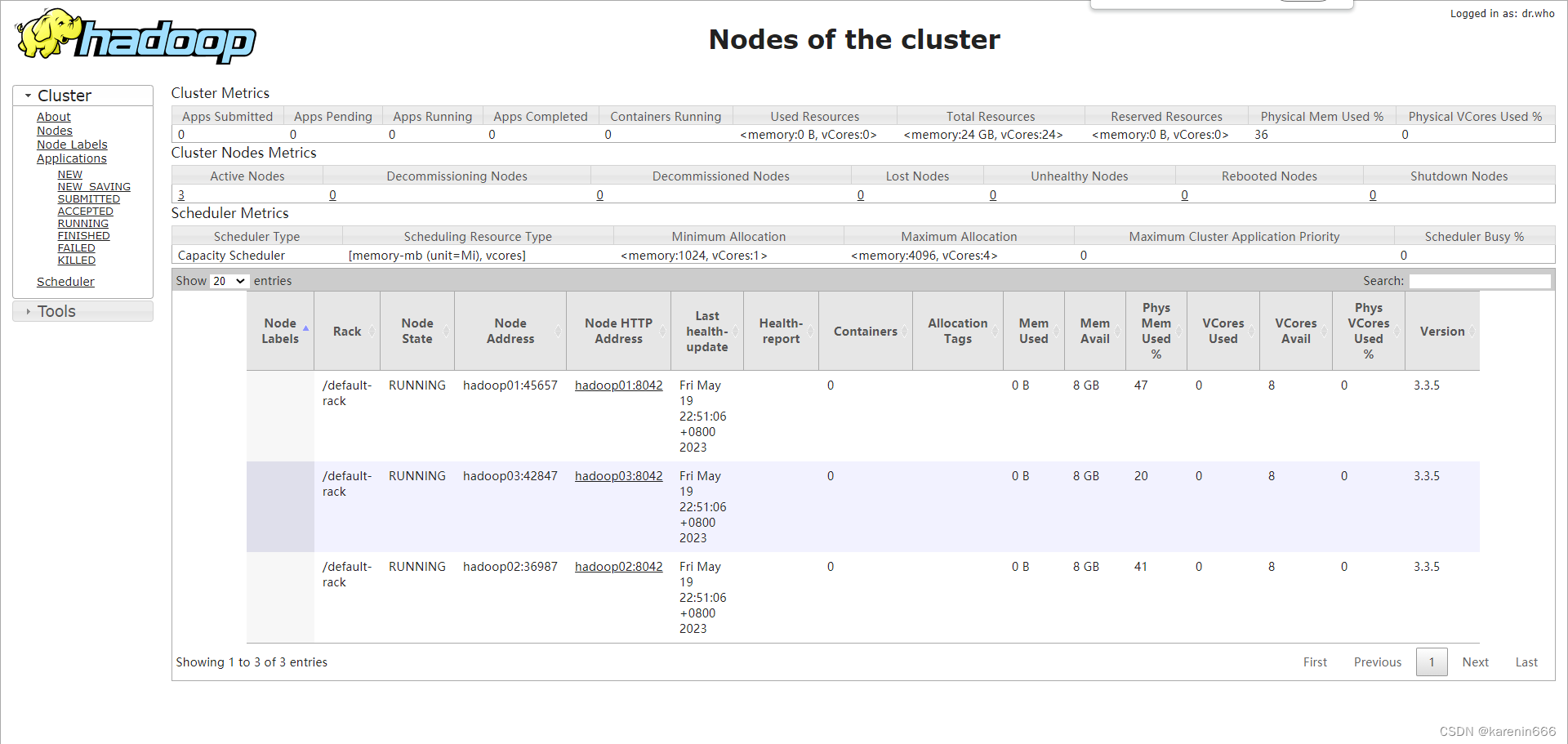
查看YARN集群状态
 问题记录
问题记录
问题1:ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes
问题2:Hadoop的start-dfs.sh的pdsh@connect: Connection refused
Hadoop的start-dfs.sh的pdsh@connect: Connection refused错误的解决方法_51CTO博客_hadoop的dfs启动未找到命令
问题3:sbin/start-yarn.sh报错
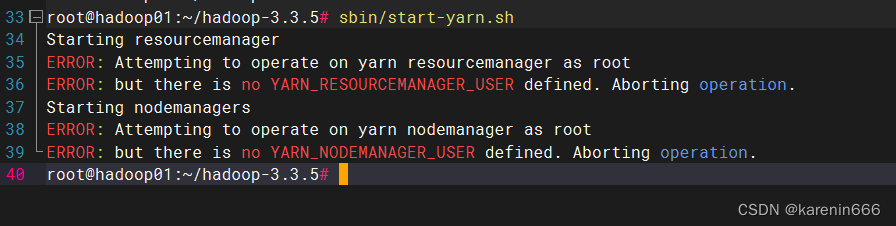
修改增加:
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
问题4:启动nodemanager报错

查看日志,有提示是配置文件错误。修改正确即可。
问题5:启动yarn后,nodemanager节点连接不到resourcemanager服务器。

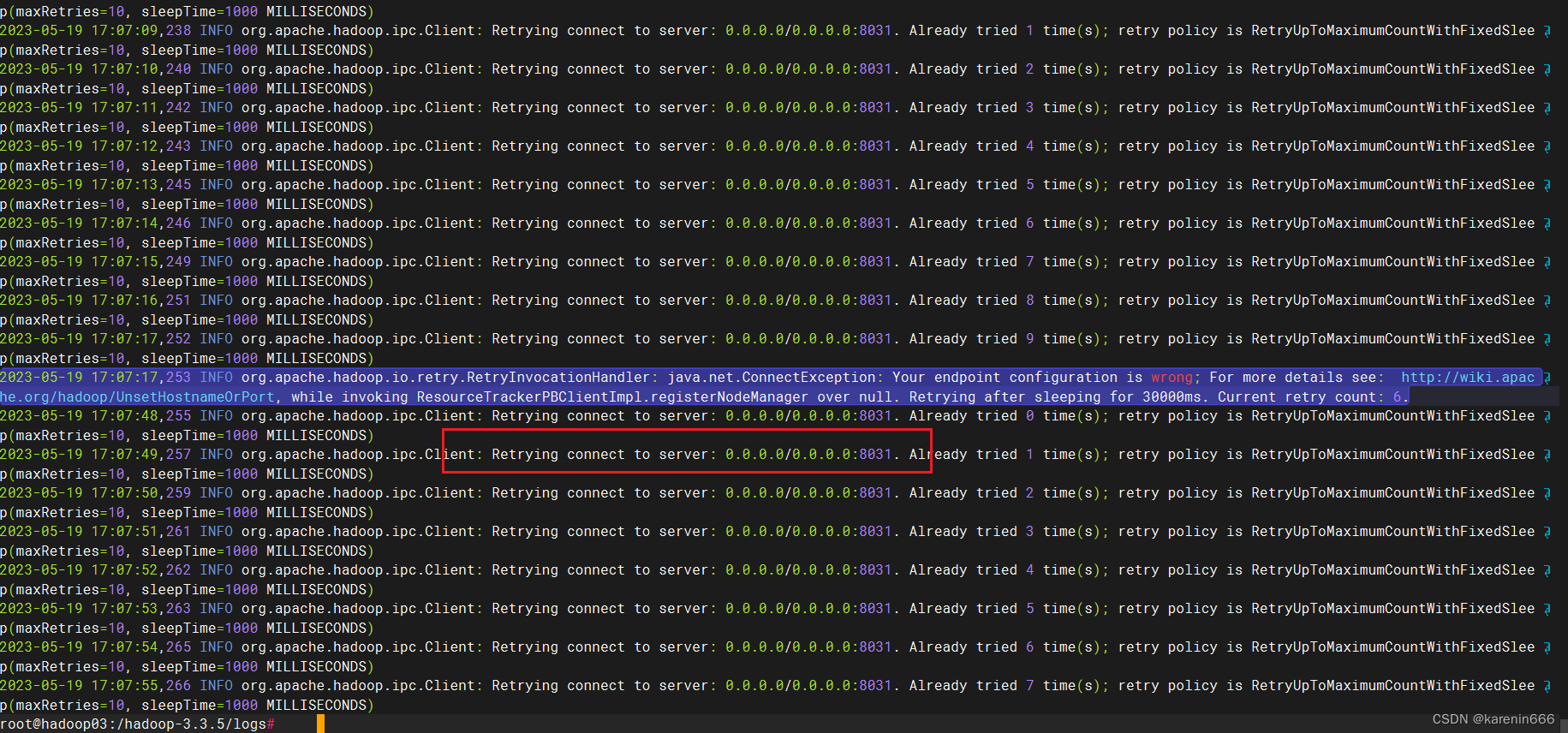
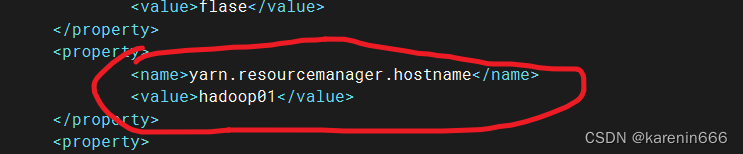
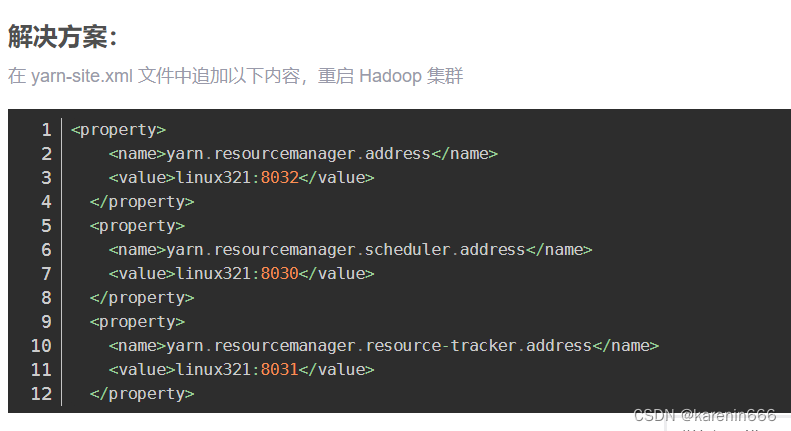
需要在nodemanager节点yarn-site.xml指定resourcemanager服务器地址















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









