








最近维护代码时,看到同事有写这种ef查询得
//获取图片
var images = await (await _supplyInfoImagesRepository.GetQueryableAsync()).Where(p => p.SupplyInfoId == curInfo.Id).OrderBy(p => p.Sort).FirstOrDefaultAsync();第一想到得估计是考虑到,后期图片表数据大了,查询效率会影响,所以就使用GetQueryableAsync(),这个返回的是一个可以被LINQ to Entities或类似的ORM技术理解的IQueryable<T>对象,那么这个查询很可能会被翻译成一个SQL查询,并在数据库服务器上执行过滤和查找操作。这通常是非常高效的,因为数据库是为快速查询大量数据而优化的。
但是请确保后续得where过滤和排序是在数据库服务器中支持的并进行的,否则在内存中性能还是不是太优。
但是我看使用ef中的FirstOrDefaultAsync()过滤也是先执行GetQueryableAsync()的,如下:
//查询
await _supplyInfoImagesRepository.FirstOrDefaultAsync(p => p.SupplyInfoId == curInfo.Id);点击FirstOrDefaultAsync()会进入
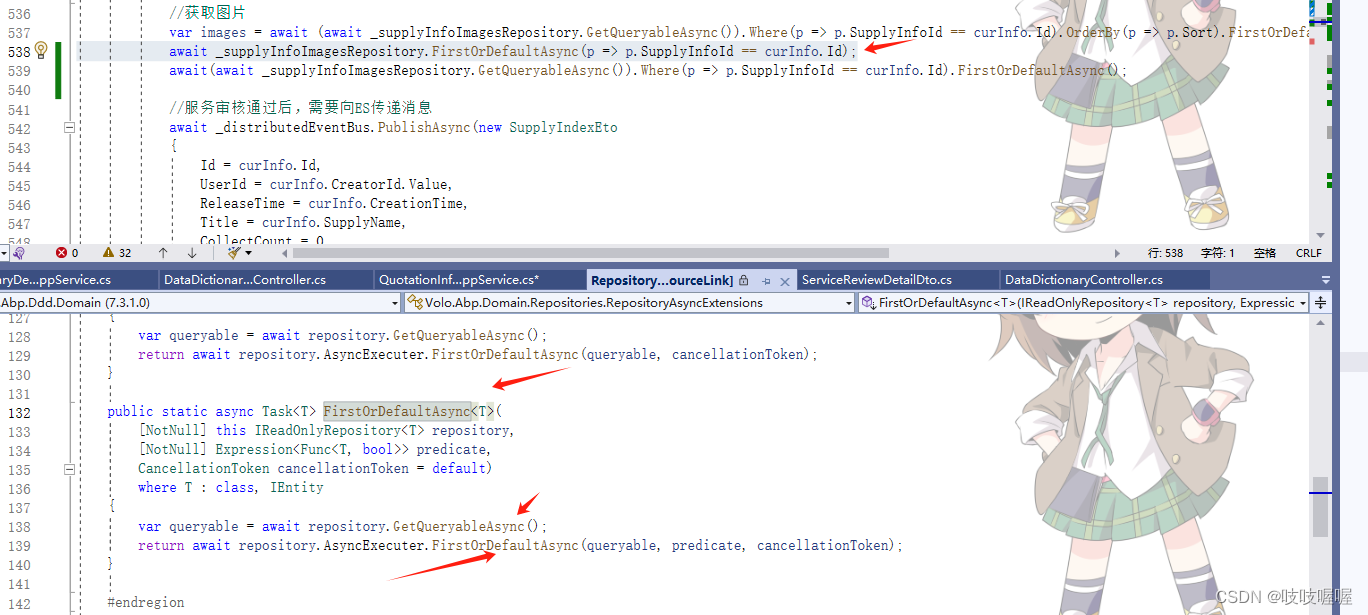
综上,在考虑代码的可读性和可维护性。如果两个查询在性能上相似,但其中一个查询的代码更清晰、更易于理解,那么你可能更倾向于使用那个查询,比如
await _supplyInfoImagesRepository.FirstOrDefaultAsync(p => p.SupplyInfoId == curInfo.Id);
但是在解析以上两个方式的时,发现
var images = await (await _supplyInfoImagesRepository.GetQueryableAsync()).Where(p => p.SupplyInfoId == curInfo.Id).OrderBy(p => p.Sort).FirstOrDefaultAsync();底层引用是
public static Task<TSource?> FirstOrDefaultAsync<TSource>(
this IQueryable<TSource> source,
Expression<Func<TSource, bool>> predicate,
CancellationToken cancellationToken = default)
{
Check.NotNull(predicate, nameof(predicate));
return ExecuteAsync<TSource, Task<TSource?>>(
QueryableMethods.FirstOrDefaultWithPredicate, source, predicate, cancellationToken);
}
而 await _supplyInfoImagesRepository.FirstOrDefaultAsync(p => p.SupplyInfoId == curInfo.Id);底层引用了
public static async Task<T> FirstOrDefaultAsync<T>(
[NotNull] this IReadOnlyRepository<T> repository,
[NotNull] Expression<Func<T, bool>> predicate,
CancellationToken cancellationToken = default)
where T : class, IEntity
{
var queryable = await repository.GetQueryableAsync();
return await repository.AsyncExecuter.FirstOrDefaultAsync(queryable, predicate, cancellationToken);
}这两则特点:
在查询性能上,这两个
FirstOrDefaultAsync方法的主要区别在于它们如何与底层数据源交互以及它们所在的抽象层级。但是,实际的查询执行和性能差异更多地取决于底层数据访问逻辑的实现和使用的数据访问技术(如 Entity Framework、Dapper 等)。第一个方法(
IQueryable<TSource>上下文)这个方法直接操作
IQueryable<TSource>接口,这通常意味着它直接与某种查询提供程序(如 Entity Framework 的 LINQ 提供程序)交互。查询是在编译时解析的,并且当查询真正执行时(即调用ExecuteAsync时),它会被转换成针对特定数据源的查询(如 SQL 语句),并在该数据源上执行。这种方法的一个优势是,由于查询是在编译时解析的,因此可以优化查询的某些部分,并且查询的执行计划可以被缓存和重用(尽管这取决于具体的查询提供程序和数据源)。
第二个方法(
IReadOnlyRepository<T>上下文)这个方法首先通过调用
repository.GetQueryableAsync()获取一个IQueryable<T>对象,然后使用该对象以及提供的谓词(predicate)来执行查询。但是,这里有一个额外的步骤:通过repository.AsyncExecuter来执行查询。这意味着在调用实际的查询方法之前,可能存在额外的封装或逻辑处理。这种方法的一个潜在缺点是,由于存在额外的抽象层,查询的执行可能不如直接在
IQueryable<TSource>上执行那么高效。然而,这也取决于AsyncExecuter的实现和它是如何与底层数据源交互的。性能考虑
- 编译时解析与运行时解析:第一个方法可能在编译时解析查询,而第二个方法可能在运行时解析查询(取决于
AsyncExecuter的实现)。编译时解析通常可以提供更好的性能,因为它允许查询提供程序进行更多的优化。- 查询缓存:如果第一个方法使用的查询提供程序支持查询缓存,并且相同的查询被多次执行,那么性能可能会得到显著提升。然而,第二个方法可能不会利用这种缓存,除非
AsyncExecuter也实现了相应的缓存逻辑。- 网络延迟和序列化:如果底层数据源位于远程服务器上(如数据库服务器),那么网络延迟和序列化/反序列化成本也可能成为性能瓶颈。这两个方法都可能受到这些因素的影响,但具体的影响取决于数据是如何从数据源检索和传输的。
- 错误处理和日志记录:第二个方法可能包含额外的错误处理和日志记录逻辑,这可能会影响性能。然而,这种影响通常是可以接受的,因为错误处理和日志记录对于生产环境的健壮性至关重要。
总结
在大多数情况下,直接从
IQueryable<TSource>执行查询可能会比通过自定义仓库接口执行查询具有更好的性能。但是,具体的性能差异取决于多种因素,包括查询提供程序的实现、数据源的位置、网络延迟、序列化成本以及错误处理和日志记录逻辑的实现等。因此,在实际应用中,最好通过基准测试来确定哪种方法更适合你的特定用例。

















 1885
1885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











