







目录
#gcc环境
yum install gcc-c++
#解压
tar -zxvf redis-6.2.1.tar.gz
#进入解压目录
cd redis-6.2.1/
#编译 安装
make
make install
配置(这种配置方式可以通过脚本自启动,配合生产。也可以直接用redis.server手动启动)
#创建用来存放redis相关配置和数据目录
mkdir /usr/local/redis
#创建做数据持久化的目录
mkdir /usr/local/redis/working
#复制配置文件到刚创建的文件夹内,方便后续管理
cp redis.conf /usr/local/redis
#进入文件夹
cd /usr/local/redis
#修改配置文件
vim redis.conf
需要修改的配置如下
#yes代表后台启动
daemonize yes
#指定工作空间,可以做持久化操作等
dir /usr/local/redis/working
#允许外部访问
bind 0.0.0.0
#解开下面配置的注释(大概在879行),配置redis的登录密码
requirepass yourpassword
继续配置
#复制脚本文件到如下文件夹
cp /home/software/redis-6.2.1/utils/redis_init_script /etc/init.d/
#进入文件夹
cd /etc/init.d/
#增加文件的执行权限
chmod 777 redis_init_script
#修改脚本文件
vim redis_init_script
需要修改的配置如下
#下面两行注释要添加进去,拿来做开机自启动
#chkconfig: 22345 10 90
#description: Start and Stop redis
#指定配置核心配置文件启动
CONF="/usr/local/redis/redis.conf"
#找到对应的位置,添加 -a "yourpassword" 赋予 stop命令关闭权限
REDISPORT ....
.....$CLIEXEC -a "yourpsssword" -p $REDISPORT shutdown
.........
redis_init_script文件的截图如下

以下是一些常用的命令
#启动redis
./redis_init_script start
#关闭redis
./redis_init_script stop
开机自启动
#执行命令 注册自启动,可以通过reboot重启服务器,重启后执行ps -ef | grep redis 来检查redis是否已经启动
cd /etc/init.d/
chkconfig redis_init_script on
#Linux下进入客户端,直接执行 redis-cli -a yourpassword 可以免除 auth yourpassword步骤
redis-cli
127.0.0.1:6379> auth yourpassword
#Ctrl + c 可以退出二.五种数据类型
String:set get
Hash:hset hmset hget hkeys hvals hdel hgetall ...
List:lpush lrange rpush lpop rpop llen lindex lset lrem ltrim
Set:sadd scard srem smembers spop srandmember smove sdiff(差集) sinter(交集)
ZSet:zadd zrange zrank zscore zcard zcount zrangebyscore zrem
三.SpringBoot整合Redis
整合相当于是让Java端与redis-cli相连接。
1.引入依赖,直接去maven仓库搜索redis可以查看发布的各个版本,如果配有parent标签,那可以不用写版本
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.4.0</version>
</dependency>2.修改配置文件
spring:
redis:
database: 0
host: 127.0.0.1
port: 6379
password: yourpassword
3.使用
可以在网上百度封装好的方法
private final StringRedisTemplate redisTemplate;四.利用fastJson实现String和List<T>互转(Redis存储Java对象)
这种方法可以用于初始化数据库内的数据到redis内,实现对象和redis内数据(String)的互相转换
1.加入依赖包
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>2.使用
这是一个序列化和反序列化的过程,T需要支持序列化和反序列化,以及需要默认的无参构造函数
List<T> list = ....
String jsonStr = JSONObject.toJSONString(list);
redisTemplate.set("list",jsonStr);
list = JSONObject.parseArray(redisTemplate.get("list"),T.class);五.发布(pub)和订阅(sub)
一般redis只做缓存就行了,此种发布订阅的消息可以交给MQ来做,这里只是记录一下Redis拥有此功能
1#>>subscribe pig dog snake
2#>>subscribe pig dog cat duck
3#>>psubscribe p*
4#>>publish pig "~~" #123所有订阅者都能收到
六.持久化
官方持久化介绍:
https://redis.io/topics/persistence
执行命令 /usr/local/redis/redis.conf 修改配置文件
#设置备份数据存储的文件夹
dir /usr/local/redis/working
RDB(Redis Database)
原理是设置各个时间点满足条件后保存当前快照到指定文件
优:这种方式非常适合用于文件的备份,来保存数据在不同时间段的版本。
而且相较于AOF,RDB更适合大数据集的重启。
缺:可能丢失宕机前一段时间的数据(不能很好的保证数据的完整性)
进行持久化操作需要子线程去持久化整个数据集,如果数据集很大,对CPU性能会有影响
#设置RDB备份数据存储的文件名
dbfilename dump.rdb
# 代表3600s内发生至少1次修改,备份一次,可以设置多个条件
save 3600 1
save 300 100
save 60 10000
#在保存过程中出现错误就停止保存,如果使用no可能会导致崩溃
stop-writes-on-bgsave-error yes
AOF(
Append Only File
)
原理是以记录操作日志的方式来实现持久化,在执行BGREWRITEAOF命令时,会写入重建当前数据集最短的指令,后续的操作也会在此新文件追加。
优:一般使用每一秒追加一次,即使宕机,也最多丢失一秒的数据,较好的保持了数据的完整性。
AOF存储的是日志操作的记录,即使执行了flushall命令,只要没有重写日志,还是可以通过删除最新命令,然后重启Redis来恢复数据
缺:AOP保存的文件通常情况下会比RDB的大,并且AOF对文件追加命令的方式,相较于RDB重新创建整体数据快照的方式来说,对错误率的抵抗会低一些。
#开启AOF
appendonly yes
#设置AOF数据存储的文件名
appendfilename "appendonly.aof"
#设置备份策略
appendfsync everysec
一般在生产环境下,两种备份方法都会被开启,RDB偏重于文件备份,而AOF更偏重于数据完整性,在redis重启的过程中,如果同时开启了RDB和AOF,也会优先以AOF的方式恢复数据。
七.主从复制(读写分离)Master :Slave
但业务量达到服务器硬件瓶颈时,为了减小Redis的压力,可以采用此种模式来减缓压力。想要使用此功能,RM必须开启数据持久化功能,比较常用的模式是一主二从(由于服务器资源有限,只做一主一从)。一台服务器负责提供写数据操作,其他负责提供读数据操作。
1.原理
首先需要有一台启动的Redis服务充当Master,并开启数据持久化,随后准备一台Redis Slave服务器,通过配置,让它启动以后去ping通Redis Master,之后会进行数据拷贝,第一次传出RM会将RDB文件写入磁盘后通过内网传输给RS,这部分是全量传输,也可以说是初始化的过程,之后RM只要有写入数据,都会将命令传输给RS。
2.搭建
#两台服务器先进入redis-cli,查看信息
cd /etc/init.d/
redis-cli -a yourpassword
127.0.0.1:6379> info replication
可以看到两台服务器都是主节点(master)

#以下操作为从节点(slave)服务器操作,我是以Tencent Cloud做slave的
cd /usr/local/redis
vim redis.conf# replicaof <masterip> <masterport> 配置主节点的ip和端口号
replicaof 192.168.1.171 6379
# masterauth <master-password> 配置主节点的密码
masterauth yourpassword
#其他配置解析(以下配置不用更改,只是提取出来作解析)
#表示作为从节点时,只读,不能写
replica-read-only yes#重启一下redis
cd /etc/init.d/
./redis_init_script stop
./redis_init_script start
#进入redis-cli
redis-cli -a yourpassword
127.0.0.1:6379> info replication
到这里就已经配置好了主从复制(读写分离)了,需要注意的是配置了主从复制之后,从节点不能再写入数据,主节点的写操作会同步到从节点,如果需要多个从节点,按照如上配置即可,记得打开从节点数据持久化功能。
3.无磁盘化复制(使用磁盘能满足要求就没必要使用这个了)
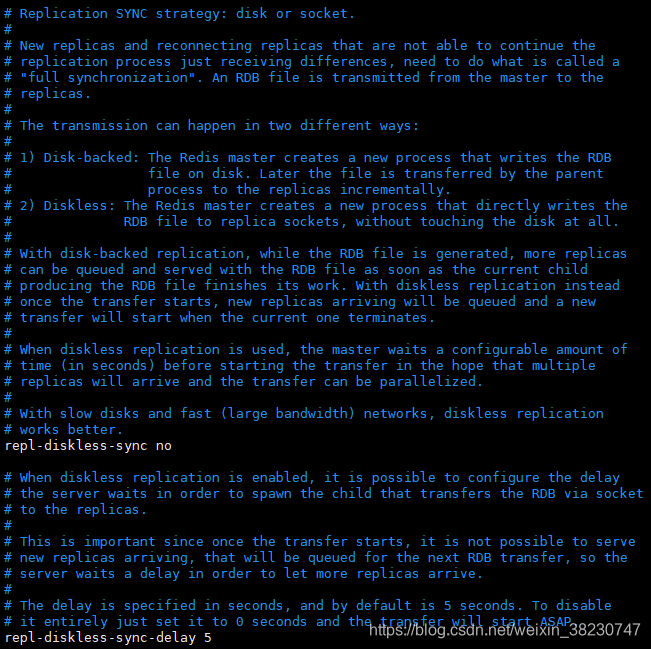
通过上面的配置,基本实现了功能,但是在主从复制刚开始第一次传输的时候,主节点会将RDB文件保存到磁盘中,然后传输给从节点,下面介绍一种无磁盘化的复制方法,直接从master的内存复制到slave的内存中(Socket方式)。(硬盘分为很多种类型,如果机器的硬盘读写速度(IO)很低,在数据集较大的情况下会非常耗时,所以延伸出无磁盘化的复制方法,但是此种方法要求有较高的带宽)
#修改配置文件
repl-diskless-sync yes
相关原理如下图,大致是会开启一个新的线程通过socket去传输这个rdb文件
八.缓存过期处理和内存淘汰策略
1.缓存过期处理
计算机内存有限,越大越贵,redis 的高并发高性能都是基于内存的,设置了 expire 的 key 缓存过期了,服务器的内存还是会占用,这是因为 redis 删除缓存是基于两种删除策略的:
-
(主动)定期删除:定时的去抽查随机的key,如果是过期,则清理删除。可通过配置hz来自定义检测规则,默认 hz 10 ,表示每秒检测10次
-
(被动)惰性删除:当客户端请求一个已经过期的 key 的时候,那么 redis 会检查这个 key 是否过期,如果过期则删除,返回一个 nil,这种策略对 CPU 比较友好,不会有太多的损耗,但是内存占用会比较高,因为极端情况下很多内存不会被再次访问。
2.内存淘汰机制
在我们的服务器中,不止有redis一个服务,并且在非常极端的情况下,缓存过期处理已经无法有效的通过清理缓存来满足要求了,那么就需要有一个较好的淘汰机制。
#规定触发淘汰的最大内存 1,073,741,824 = 125M
# maxmemory <bytes>
# 1G 1024MB 1048576KB 1073741824Bytes 8589934592Bit
maxmemory 1,073,741,824
#淘汰策略:allkeys-lfu 删除最不经常使用的缓存
# maxmemory-policy noeviction
maxmemory-policy allkeys-lfu
其他策略:
# maxmemory-policy 内存淘汰策略值枚举:
volatile-lru:在使用 expire 设置了过期时间的 key 中,删除最近最少使用的缓存,然后保存新的缓存
allkeys-lru:删除最近最少使用的缓存,然后保存新的缓存(推荐使用)
volatile-lfu:在使用 expire 设置了过期时间的 key 中,删除最不经常使用的缓存,然后保存新的缓存
allkeys-lfu:删除最不经常使用的缓存,然后保存新的缓存(推荐使用)
volatile-random:在使用 expire 设置了过期时间的 key 中,随机删除一个 key
allkeys-random:在所有 key 中,随机删除一个 key
volatile-ttl:在使用 expire 设置了过期时间的 key 中,删除最快要过期的 key,即删除 TTL 最小的 key
noeviction:不删除任何数据,报出写操作异常(默认值)
LRU和LFU区别
* LRU:(按时间)Least Recently Used,即最近最少使用页面置换算法,淘汰访问时间最早的数据
* LFU:(按次数)Lease Frequently Used,即最不经常使用页面置换算法,将数据按照访问频次排序,淘汰访问频次最低的数据九.哨兵机制
在主从复制(读写分离)的模式下,大大减小了单个Redis的压力,但是如果Master出现问题的话,Slave不管有多少个,都是用不了的,为了增强Redis的可用性,可以用哨兵机制来解决这个问题。
1.哨兵机制的重要功能:
-
集群监控,监控Master和Slave进程是否正常工作
-
通知,当被监控的某个节点出现问题时,可以通过API向管理员或者其他应用程序发送通知
-
故障自动转移,如果Master出现问题,那么Sentinal会修改值节点的配置文件,让它升级为主节点
2.故障转移机制:
-
每个哨兵都会向其他哨兵(Master、Slave)定时发送消息,以确认对方是否正常工作,如果在指定时间内未响应,则会将节点暂时判定为主观宕机(sdown)
-
若哨兵集群中多数都认为节点宕机,则会将节点判定为客官宕机(odown),此时会通过选举算法来将一个slave节点升级为master
-
原master恢复正常,会成为新master下的slave节点
3.选举算法:
-
需要关注四个点:断开连接链接,slave优先级,复制的offset,runid
-
①如果slave节点与master节点断开的时间已经超过了down-after-millseconds的十倍加上dmaster宕机时长,那么slave就会被认定为不适合选举为master
-
②先按照slave优先级排序,slave优先级越高,排序越前
-
③按照复制的offset排序,复制的数据越多,排序越靠前
-
④如果以上两个条件都相同,那么就直接将run id较小的slave升级为master
4.配置:
cp sentinel.conf /usr/local/redis
cd /usr/local/redis
vim sentinel.conf#两种模式,一种是对指定ip开放,一种是禁用保护模式,任何ip都能访问
protected-mode no
#启动哨兵
daemonize yes
#运行日志
logfile /usr/local/redis/sentinel/redis-sentinel.log
#工作空间
dir /usr/local/redis/sentinel
#ucloud-amster为昵称,随后是自身的ip,端口,最后面2代表的是如果有超过2台sentinel判定当前服务器主观下线,则标记为客观下线,开启故障转移
sentinel monitor ucloud-master 192.168.1.171 6379 2
#配置账号密码,ucloud-master为昵称,
sentinel auth-pass ucloud-master yourpassword
#哨兵超过10000ms未收到master正确的回传消息,则会判定节点为主观下线,当达到条件的哨兵认为master节点主观下线的数量满足设置,则会转为客观下线,开启故障转移
sentinel down-after-milliseconds ucloud-master 10000
#并行同步原master的数据到slave,配置为1则代表一次只能同步一台,如果从节点用于提供查询,尽量设置较小的数字,这样就不会造成无从节点可提供服务了。
sentinel parallel-syncs ucloud-master 1
#用途多种,
sentinel failover-timeout ucloud-master 180000#由于是集群,配置文件的集群基本都是一样的,所以直接通过远程拷贝命令将文件传输给其他子节点
scp sentinel.conf root@192.168.1.172:/usr/local/redis/
....
cd /usr/local/redis
mkdir sentinel
#通过配置文件启动哨兵
redis-sentinel sentinel.conf
#以同样的方式启动其他子节点
注意:由于服务器资源有限,所以用的两台服务器(两个Sentinel服务)测试的,但是一直都行不通,后来查阅了官方文档才知道,至少需要三个Sentinel服务才可以做哨兵机制。
5.SpringBoot集成Redis哨兵
修改配置文件(将原来的配置删除或者注释)
spring:
redis:
database: 0
password: yourpassword
sentinel:
#对应的是主节点配置文件中sentinel monitor ucloud-master 192.168.1.171 6379 2的昵称
master: ucloud-master
#配置从节点的ip和端口号,多个从节点用逗号分隔
nodes: 192.168.1.172:26379,192.168.1.173:26379十.集群搭建(水平扩展)(机器有限,使用三台单节点的Redis搭建集群)
通过Redis的主从复制(读写分离)可以增加并发性能,但是单个master的内存是有限的,数据量非常庞大的时候服务器性能会达到瓶颈,可以采用集群的方式解决此问题。
1.配置
#由于服务器不够,就先将原来slave节点redis.conf的主节点信息配置注释,改为与master平级。如果是有够多的服务器做slave节点,忽略本步骤
#replicaof 192.168.1.171 6379
#masterauth yourpassword
对集群的所有节点做如下操作
#解开以下注释
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 5000
#进入working目录,删除.aof和.rdb文件,不删除在构建集群的时候会报错,清空内容也可以
cd working
rm appendonly.aof dump.rdb
在早期的版本,构建redis集群需要借助ruby脚本:/home/software/redis-6.2.1/src/redis-trib.rb,新版本使用redis-cli命令,如下配置(在机器192.168.1.171操作)
#可以先用此命令查看帮助文档
redis-cli --cluster help
#开始搭建(需要注意的是Redis集群最少需要三个节点),注意ip:port是需要填写所有节点的,如果本机也部署了redis,也需要。执行完后输入yes确认构建
redis-cli -a yourpassword --cluster create 192.168.1.171:6379 192.168.1.172:6379 192.168.1.173:6379
yes
#注意,这里部署的是无slave的集群,所以执行如上命令即可。可能因为没有删除持久化文件而报错,记得删除
#如果在master下还配置有slave,那么第一个修改slave为master的动作就不需要做了,使用如下命令,最后一个数字“1”代表的是 slave/master ,即1个master对应1个slave
#假设 171(Master) 172(Master) 137(Slave) 174(Slave)
#redis-cli -a yourpassword --cluster create 192.168.1.171:6379 192.168.1.172:6379 192.168.1.173:6379 192.168.1.174:6379 --cluster-replicas 1
#使用如下命令检查节点(无论检查哪个节点,集群所有节点的状态都会列出)
redis-cli -a yourpassword --cluster check 192.168.1.171:6379
#使用如下命令进入集群查看信息,进入任一节点都可以
redis-cli -c -a yourpassword -h 192.168.1.171 -p 6379
192.168.1.171:6379> cluster info
192.168.1.171:6379> cluster nodes
如何在不删除的情况下部署集群?
如何在集群运行中添加节点?
2.槽节点
在集群构建完毕之后,可以看到redis分配了16438个槽节点,每一个master节点都会分配到一定量的slot槽节点,且每个master节点所分配到的空间都是一样的。
槽:类似于内存插槽,一台主机可以拥有多个内存插槽,主机是共享这些内存的。
假设有请求get(key),会根据hash(key)/16438来计算数据存储在哪个槽,从而去对应的节点取数据。
在配置了集群之后,在171机器上进入redis-cli存入的数据不一定存放在171,而是会存放在计算出的slot对应的节点(有点类似于一致性哈希算法找到对应的节点)。如下:
192.168.1.171:6379> keys *
1) "171"
192.168.1.171:6379> set name shixin
-> Redirected to slot [5368] localted at 192.168.1.172:6379
OK
192.168.1.172:6379> keys *
1) "name"
192.168.1.172:6379> get name
-> Redirected to slot [5368] localted at 192.168.1.171:6379
"shixin"
192.168.1.171:6379>
3.SoringBoot集成Redis集群
redis:
password: shixin
cluster:
#配置所有节点的ip和port
nodes: 192.168.1.171:6379,192.168.1.172:6379,192.168.1.173:6379十一.缓存穿透和缓存雪崩
1.缓存穿透
有些本应该去访问redis的请求,因为redis里没有对应的数据,所以会去访问数据库,然而数据库中也没有数据,所以无法再此步骤将数据存入缓存,导致一直会去访问数据库,这就是缓存穿透。
在某些方法里,可能会通过判断缓存中是否有数据来判定是去数据库取还是直接用缓存中的数据,但是在数据库取也会存在为空的风险,所以可以设定不管数据库是否为空,都应该将数据存到缓存,并且设定一定的过期时间,这样就可以避免恶意用户通过缓存穿透来攻击数据库。
解决方案:
if (StringUtils.isBlank(redisStr)){
list = myService.getList(id);
if (CollectionUtils.isEmpty(list)){
redisOperator.set("key:"+id,JSONObject.toJSONString(list),5*60);
}else {
redisOperator.set("key:"+id,JSONObject.toJSONString(list));
}
}else {
list = JSONObject.parseArray(redisStr);
}
2.缓存雪崩
在缓存中我们会为很多的key去设置过期时间,如果这些key过期的时间刚好集中在一段时间,也就是缓存大面积失效,而恰巧在这段时间我们的网站有很大的流量,那么这个时候所有的请求都会打到数据库上,数据库就会面临很大的压力,甚至宕机。(如果已经宕机,可以通过不断重启数据库来慢慢解决,在重启的过程中部分请求需要的数据已经存到缓存中),对于缓存雪崩是无法完完全全解决的,只能提前的去做一定的防护措施。
预防措施:
①.永不过期
一些热点数据都是可以不设置过期时间的
②.过期时间错开
在系统初始化的时候设置的一些拥有有效期的缓存可以人为的错开他们的过期时间。
③.多缓存结合
可以使用多种缓存,如 redis->mencache->mysql
④.采购第三方Redis
十二.multiGet和pipeline批量查询优化
如果需要一次性获取多个key的值,采用for循环get会让redis不断创和关闭链接,可以采用如下方法:
multiGet批量查询优化 String... keys;
List<String> redisValues = redisTemplate.opsForValue().multiGet(Arrays.asList(keys));
pipeline 管道,类似于nginx的keeplives,保持常链接访问:
这种方式会保持一个管道访问,完成方法内所有命令执行完毕后才会关闭链接,并且会将获取的数据全部返回到Object内,这种方式不仅可以优化查询,重要的是可以做多样化操作
结果数据格式:["value1","value2","value3","value4"]
List<Object> result = redisTemplate.executePipelined(new RedisCallback<String>() {
@Override
public String doInRedis(RedisConnection redisConnection) throws DataAccessException {
StringRedisConnection src = (StringRedisConnection)redisConnection;
for (String k : keys){
src.get(k);
}
return null;
}
});十三.分布式锁
//有空再写















 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









