







logistics实现判断猫
任务
给定数据是一些图片,其中有部分是猫的图片,需要做的是训练模型,判断图片是否猫的图片
导入第三方库
import numpy as np
import matplotlib.pyplot as plt #画图工具
import h5py #处理h5文件工具包
from lr_utils import load_dataset #导入题目给出的数据读入代码
接下来开始一步步实现
第一步:认识数据
#导入数据,数据返回值与题目中同步
def loadData():
"""
返回值
train_set_x_orig:训练集图像数据
train_set_y_orig:训练集的图像类别,0表示不是猫,1表示是猫
test_set_x_orig: 测试集的图像数据
test_set_y_orig: 测试集的图像类别
classes :[b'non-cat' b'cat'],存储两个字符串,表示类别
"""
train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes = load_dataset()
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
#测试,了解数据的维度信息,通过输出结果,可以看到,图片尺寸为(64,64),通道数为3,训练集图片数目209,测试集50张
train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes = loadData()
print("train_set_x_orig",train_set_x_orig.shape)
print("train_set_y_orig",train_set_y_orig.shape)
print("test_set_x_orig",test_set_x_orig.shape)
print("test_set_x_orig",test_set_y_orig.shape)
print("classes",classes.shape)
print(type(test_set_y_orig))
print(train_set_y_orig.shape[1])
输出如下,数据是图片数据,图片尺寸为(64,64),通道数为3,训练集图片数目209,测试集50张

第二步:数据预处理
数据预处理部分包括拉伸维度和数据标准化,将数据维度变为下图
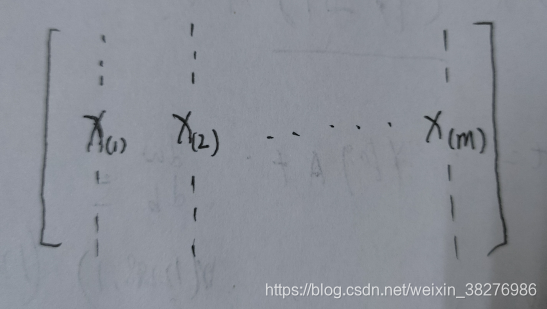
假设有m个样本,在本题中即为209个样本图片,对图片进行拉伸后,由三维到一维,即每一列为一张图片数据,图片特征数为(64643),即为像素点。则处理后的训练集的维度为(64643,m)
def predata(train_set_x_orig,test_set_x_orig):
"""
参数
train_set_x_orig 训练集,(209,64,64,3)
test_set_x_orig 测试集 (50,64,64,3)
返回值
train_x (64*64*3,209)
test_x (64*64*3,50)
"""
#以训练集为例,原始为(209,64,64,3),第一步变换为(209,64*64*3),参数 -1,自动计算图片矩阵的像素点个数,第二步,对其进行转置
train_x = train_set_x_orig.reshape(train_set_x_orig.shape[0],-1).T
test_x = test_set_x_orig.reshape(test_set_x_orig.shape[0],-1).T
return train_x,test_x
#归一化处理,图片像素值在0~255之间
def normalization(train_x,test_x ):
train_x = train_x/255.0
test_x = test_x/255.0
return train_x,test_x
第三步:模型实现
1、模型初始化
对w和b进行初始化,采用随机初始化,乘0.01必须要有,让w刚开始尽可能小点,因为最开始没有加,导致损失值一直为NaN
def initialize(dim):
w = np.random.randn(dim,1)*0.01
b = 0
assert(w.shape == (dim,1))
return w,b
2、前向传播
首先对一个样本处理,
目标函数:
z
(
i
)
=
w
T
x
(
i
)
+
b
z^{(i)}=w^{T} x^{(i)}+b
z(i)=wTx(i)+b
通过sigmoid函数将目标结果映射到0到1之间
y
^
(
i
)
=
a
(
i
)
=
sigmoid
(
z
(
i
)
)
\hat{y}^{(i)}=a^{(i)}=\operatorname{sigmoid}\left(z^{(i)}\right)
y^(i)=a(i)=sigmoid(z(i))
计算出损失值
L
(
a
(
i
)
,
y
(
i
)
)
=
−
y
(
i
)
log
(
a
(
i
)
)
−
(
1
−
y
(
i
)
)
log
(
1
−
a
(
i
)
)
\mathcal{L}\left(a^{(i)}, y^{(i)}\right)=-y^{(i)} \log \left(a^{(i)}\right)-\left(1-y^{(i)}\right) \log \left(1-a^{(i)}\right)
L(a(i),y(i))=−y(i)log(a(i))−(1−y(i))log(1−a(i))
对其进行向量化后
z
=
w
T
x
+
b
z=w^{T} x+b
z=wTx+b
y
^
=
a
=
sigmoid
(
z
)
\hat{y}=a=\operatorname{sigmoid}\left(z\right)
y^=a=sigmoid(z)
L
(
a
,
y
)
=
−
y
log
(
a
)
−
(
1
−
y
)
log
(
1
−
a
)
\mathcal{L}\left(a, y\right)=-y \log \left(a\right)-\left(1-y\right) \log \left(1-a\right)
L(a,y)=−ylog(a)−(1−y)log(1−a)
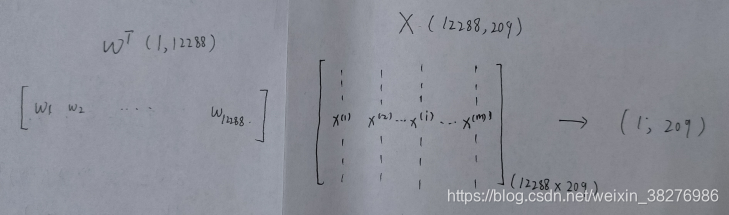
def pry(w,b,X):
"""
参数
w: 权重参数(64*64*3,1)=(12288,1)
X: (64*64*3,209)
返回值
y :(1,209)
"""
y = np.dot(w.T , X) + b
return y
def sigmoid(w,b,X):
z = pry(w,b,X)
y_m = 1/(1+np.exp(-z))
return y_m
def getcost(w,b,X,y):
"""
y_m :(1,209)
y: (1,209)
"""
y_m = sigmoid(w,b,X)
l = y*np.log(y_m) + (1-y)*np.log(1-y_m)
m = X.shape[1]
j = (-1/m)*np.sum(l)
return j
3、后向传播
后向传播即要算出dw,db,确定参数w和b的更新方向,下面是手推过程,特别要理解计算图。

下面是向量化后的实现方式。
def derivation(w,b,X,Y):
m = X.shape[1]
A = sigmoid(w,b,X)
dw = (1 / m) * np.dot(X, (A - Y).T)
db = (1 / m) * np.sum(A - Y)
return dw,db
3、模型综合
def updata(w,b,X,Y,num_iterations,learning_rate):
costs = []
#设置num_iterations次迭代
for i in range(num_iterations):
cost = getcost(w,b,X,Y)
dw ,db = derivation(w,b,X,Y)
#更新w和b
w = w - dw*learning_rate
b = b - db*learning_rate
#保存损失值
costs.append(cost)
if(i%100==0):
print("迭代的次数: %i , 误差值: %f" % (i,cost))
return w,b,costs
4、模型检验
模型预测函数,传入训练好的参数w,b
def predict(w,b,X):
#y_pre = np.zero(1,x.shape[1])
y_pre = sigmoid(w,b,X)
#当预测概率大于等于0.5,将值改为1,小于0.5,改为0
y_pre = np.where(y_pre < 0.5 , 0 , 1)
return y_pre
统计预测和数据集中的类别值相同元素的个数
def accuracy_rate(y_pre,y_ori):
#判断两个列表中值相同的
num = y_ori.shape[1]
y = y_pre-y_ori #元素对应位置相减
num_0 = np.sum(y == 0)#统计值为0的个数
return num_0/num
def showcosts(costs,learning_rate,num_iterations):
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations')
plt.title("learning rate = " + str(learning_rate) + "," + 'num_iterations = ' + str (num_iterations))
plt.show()
def model(num_iterations,learning_rate):
#导入数据并进行预处理
train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes = loadData()
train_x,test_x = predata(train_set_x_orig,test_set_x_orig)
train_x,test_x = normalization(train_x,test_x )
train_y = train_set_y_orig
test_y = test_set_y_orig
#初始化参数
w,b = initialize(train_x.shape[0])
w , b ,costs = updata(w,b,train_x,train_y,num_iterations,learning_rate)
showcosts(costs,learning_rate,num_iterations)
#计算在训练集上的准确率
y_pre = predict(w,b,train_x)
acc = accuracy_rate(y_pre,train_y)
print("训练集准确性:" , acc*100 ,"%")
#计算在测试集上的准确率
y_pre = predict(w,b,test_x)
acc = accuracy_rate(y_pre,test_y)
print("测试集准确性:" , acc * 100 ,"%")
def main():
#定义超参数
num_iterations = 2000
learning_rate = 0.005
model(num_iterations,learning_rate)














 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









