







提及Java中的编码问题,许多博客都会提及Java中的getBytes()方法,不过笔者在研究这个问题的时候,会陷入一个疑惑中,getBytes()方法的作用是将字符串按照指定的charset编码,但是这些字符串本身其实已经以某种编码方式存在内存中了,那这个方法的指定参数不会导致乱码吗,假如原本是以unicode码存在内存,getBytes("BGK")用BGK对原来的编码进行再编码?要较好的理解这个问题,需要了解Java从编译开始,再到Jvm内存中编码方式,这个按照网上定义叫做Java的内部编码(概念也许并不权威,但其实并不重要);而程序本身涉及到的外部文件读写,与数据库的交互等则称为Java的外部编码(与内部编码相对的概念而已)。
**
Java的内部编码
Java内部的编码体系大致如图: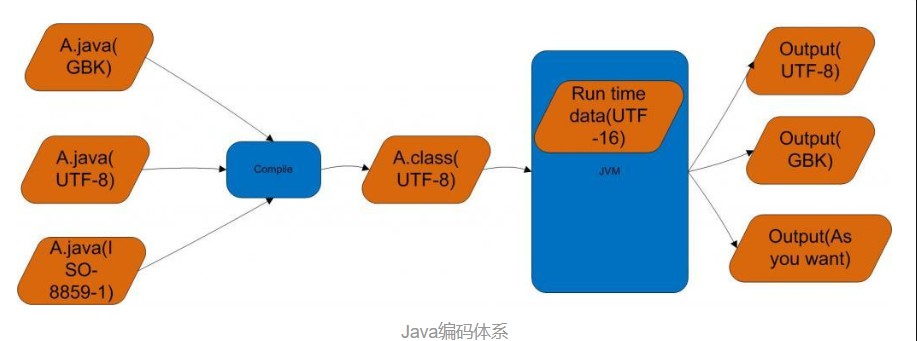
- Javac在编译的时候,会解析Java的源文件从而形成语法树(具体过程自行google,这里不重点讨论),需要知道的时候这个解析的过程是解析Java源文件中的一个个字面的字符(import,public,private,int等)。我们都知道Java的源文件是任意的编码,就像普通的文本文件一样,而在经过编译之后的class文件是以UTF-8(其实是一种modified UTF-8,先以UTF-8统称)编码的,那就说明在这个过程中存在两种字符集之间的映射规则,例如GBK->UTF-8等等,也说明了如果搞错了映射规则,就会编译失败,例如源文件是UTF-8编码,然而javac用ASCII的规则去映射,就有可能超过了ASCII的范围而导致映射失败。具体过程可见下图:
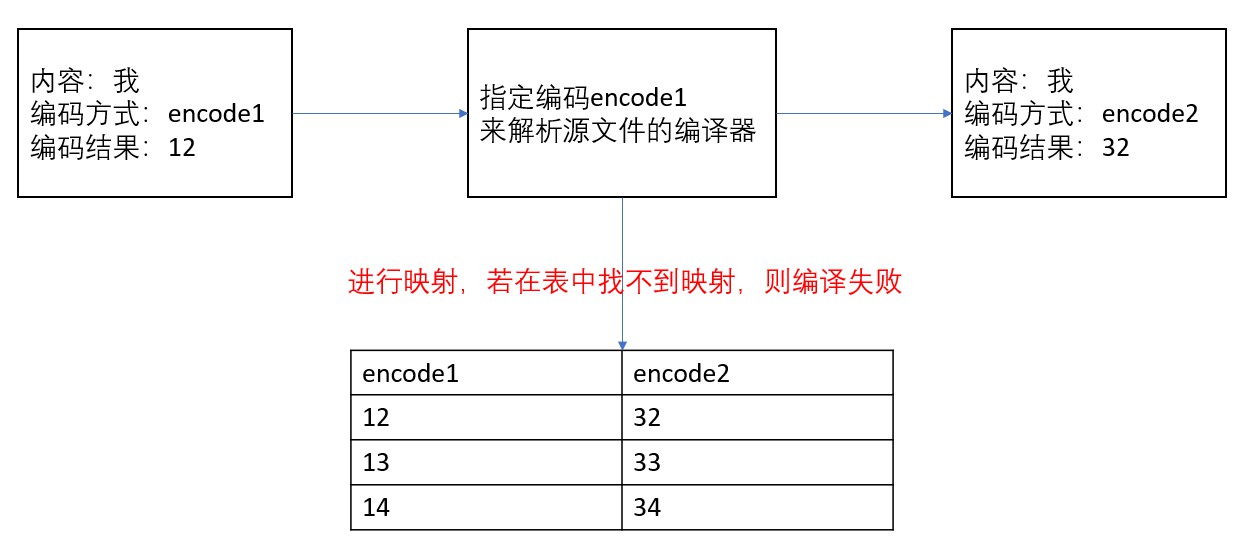
所以在编译期要防止乱码和编译错误的情况发生就得指定编码来读取源文件,需要使用-encoding参数来指定。
- “运行时的UTF-16”指的是Java语言的内建数据结构char类型规定是UTF-16 code unit(注意不是UTF-16 code point),所以辨识char类型的最小单位是2个字节大小的代码单元一定要理解“运行时的UTF-16”的含义,是特指char类型的一个定义。这样,从外界进入Java世界的字符/字符串数据,无论原本编码是什么,一旦转换为java.lang.String来表示,都会变为UTF-16编码来处理;到最后要把数据输出回到外界的时候,再转换为外界期望的编码去输出。这样的好处是在Java内部的时候,处理可以统一在UTF-16一种编码下,简化了程序需要考虑的情况。但具体JVM实现可以在保持String是UTF-16的表象的基础上,在内部做进一步优化。例如说可以实际用1字节的Latin(扩展的ASCII)来存储那些没有超出Latin编码范围的字符串。请参考HotSpot的JEP 254: Compact Strings。使用定长的UTF-16来表示字符串,可以提高字符串的访问效率,因为都是两个字节的代码单元,如果使用变长的UTF-8,在随机访问字符串的时候,只能从头开始辨识。**
Java的外部编码
具体详情请见:深入分析 Java 中的中文编码问题中的Java如何编解码章节。下面列举笔者在阅读过程的疑惑和理解。
- 文章中的例子字符串char[]中表示的是这个字符串在unicode中的code point,并不是char的内部编码。
getBytes()方法会使用系统默认编码把字符串内容编码一遍再输出,getBytes()并不返回Java字符串的内部形态,这个系统的默认编码可以通过Charset.defaultcharset()查看。- 所以阅读完文章后我的理解是,getBytes()方法做的事就是对两种字符集(unicode和我们指定的Charset)进行映射,映射不存在就会乱码。















 2142
2142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









