






问题背景:
先说下架构,生产MQ架构3m-3s sync master,async slave架构,总共6台虚拟机构成。
生产环境MQ由3.2.2升级至4.1.0后,Producer出现很多[TIMEOUT_CLEAN_QUEUE]broker busy报错,查了很多帖子,均说是MQ性能不够,由于是金融行业,仅开启slave异步刷盘,master仍然是同步刷盘。
第一次写文章还请见谅。
调优手段:
1、调整参数
sendMessageThreadPoolNums=32
useReentrantLockWhenPutMessage=true
#broker的默认发送消息任务队列等待时长
waitTimeMillsInSendQueue=500
2、扩容Broker机器
由3m-3s调整为6m-6s,容量扩大一倍。
一般金融行业的调优上述手段已足够,除非master也开启async flush,但是消息不能保证,所以不建议master开启异步。
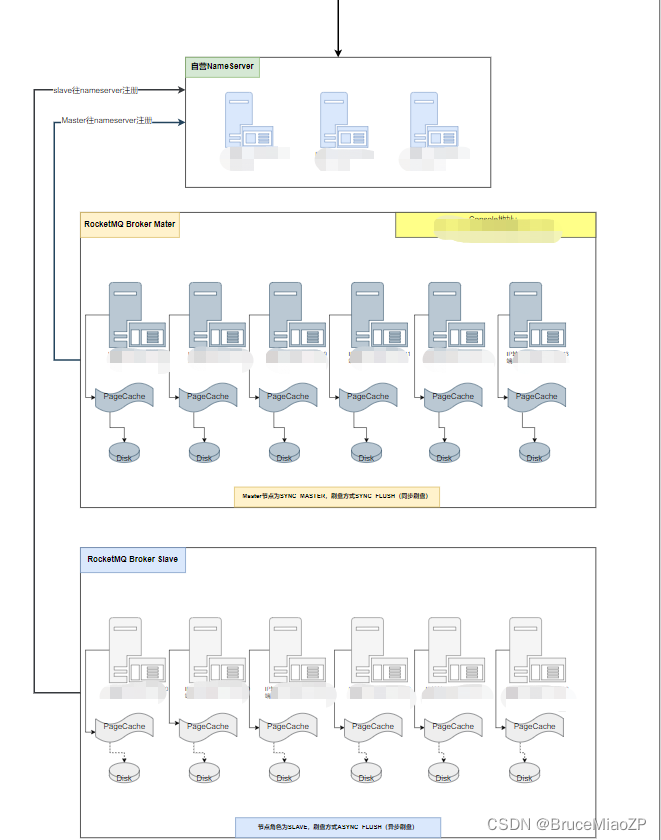
上述调优手段实施后,仍然有broker busy报错。
原因排查及处理过程:
- 开始我们是觉得等待太多,会不会是因为Broker读写队列太少了,导致发送太多,来不及处理,于是我们扩大了topic的读写队列数,但是结果发现队列数多了,应用没有限流,可劲的发消息,Broker busy的错误更多了。
说到读写队列扩容,RockerMQ的一点好处,读写队列在线扩容,一般而言,写队列<=读队列,缩容的时候,先调降写队列,在对应的读队列消费完成offset变成0后,再调降读队列。
经历了队列的扩容,没有达到预期效果。反而效果更差,不得已空闲时间,将队列进行缩容。降低broker压力。 - 我们排查异常时间段,发现Broker写压力还可以,但是Broker读的压力非常大,之前我们排查方向一直放在写上面,没有想到读也会造成IO压力。
1)通过sar -b -f /var/log/sa/saXX,saXX找对应日期的sa文件就行。发现异常时间段,磁盘读压力相当的大。
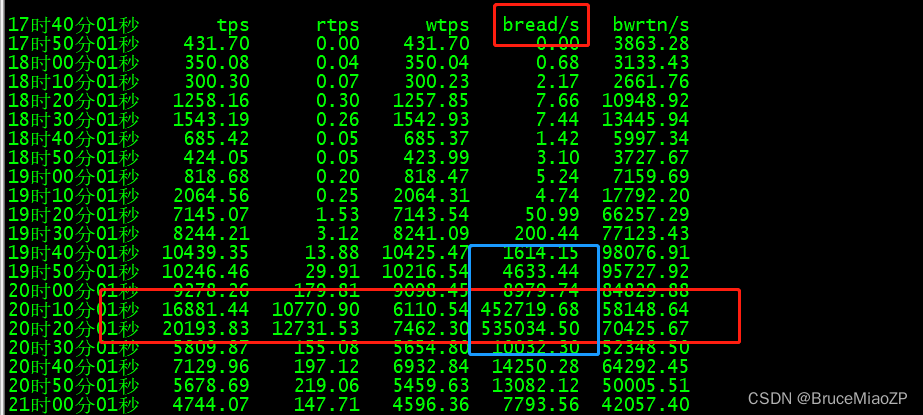
2)通过监控工具发现异常时间段Out流量也特别高
3)通过MQ Console发现异常时间段,消费TPS 瞬间达到20万。
结合上述的各种迹象,我们在console发现一个topic,姑且叫A,A topic是我们一个清算系统的统一的一个topic,RocketMQ可以根据tag进行过滤消费,所以这个系统的A topic,统计了一下,大概被50多个Consumer订阅了。订阅关系,虽然最终成功消费会根据tag去过滤,但是拉取消息的时候,是所有的订阅组都去拉取消息。当业务数据一下子过来的时候,50个订阅组都会去拉取消息,从而造成消费压力剧增,broker IO被读的压力撑爆,从而导致发送出现异常。
从下图我们就能很直观的看到这种现象。
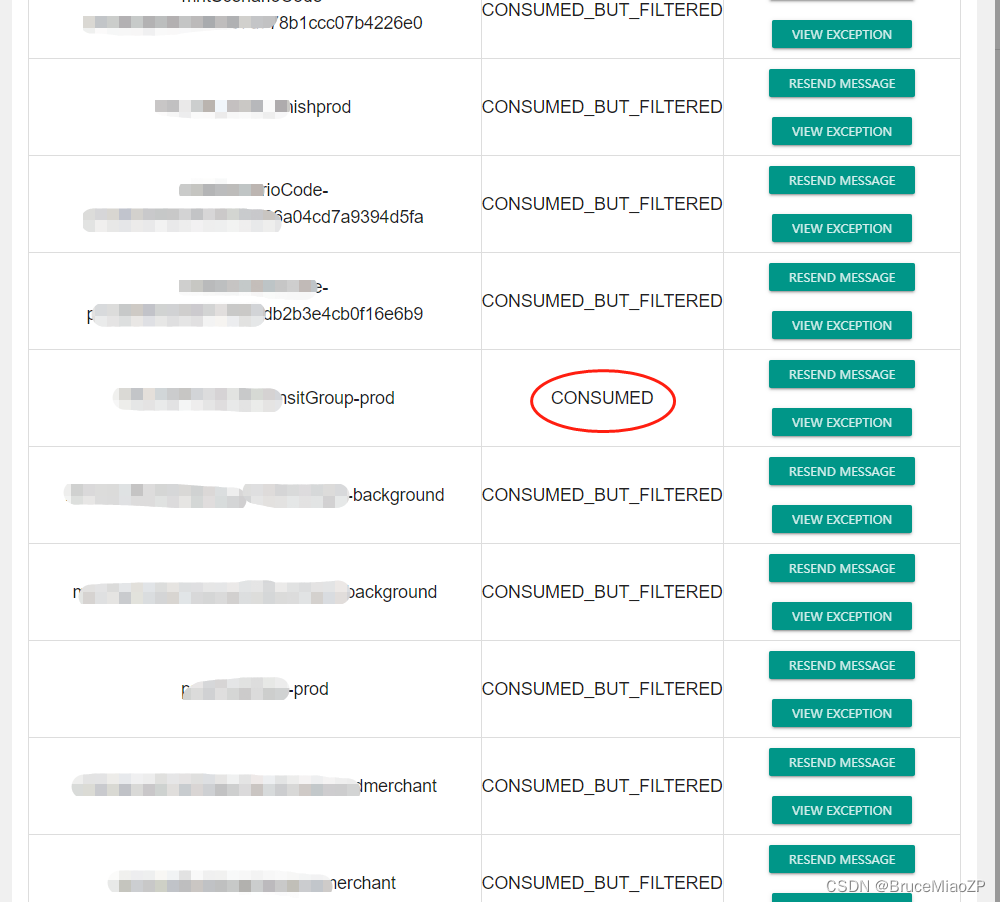
结合上述的分析,根本原因如下:
1、老的使用方式,一个业务系统一个topic,通过不同tag去区分消费的方式,导致一个topic订阅组太多,当消息量大的时候,消费量成倍的增加,造成IO性能异常,从而导致Broker Busy出现。
2、因为目前使用的是虚拟机搭建集群方式,磁盘性能肯定跟NVME的不可同语,读写性能较差。
解决方案:
1、改变现有的业务模式,将topic精细化,不能统用一个。
2、后续采用NVME的物理服务器搭建迁移MQ集群。














 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









