






-
工作队列使Linux内核中把工作延迟执行的一种手段,其目的不同于软中断,软中断使提高CPU的相应,尽可能的缩短关中断的时间。而工作队列主要目的使节省资源,其比较适合微小的任务,比如执行某个唤醒工作等,通过创建线程同样可以达到目的,但是线程毕竟有其自身的资源开销如CPU、内存等。如果某个任务很小的话,就不至于在创建一个线程,因此linux内核提供了工作队列这种方式。工作队列成为Concurrency
Managed Workqueue(cmwq) -
总体描述
-
工作队列相关结构体
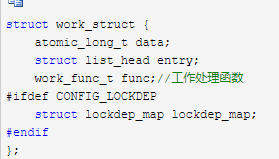
-
这是工作队列机制暴露给外部(使用方)的工作对象,entry维护该结构在work_pool中的链表,func是一个函数指针,指向该工作需要执行的处理函数,一个驱动程序后者内核模块要使用工作队列,创建一个work_struct结构,填充其中的func字段即可,之后调用schedule_work提交给对象。
-
内核中既然把工作队列作为一种资源使用,其自然有其自身的管理规则,因此在内核中涉及到一下对象:
-
worker 工作者,顾名思义为处理工作的单位
-
worker_pool 工作者池,每个worker必然属于某个worker_pool,一个worker_pool可以有多个worker
-
workqueue_struct 官方解释是对外部可见的workqueue
-
pool_workqueue 链接workqueue_struct 和worker_pool的中介,每个workqueue_struct可以有多个worker_pool,而一个worker_pool只能属于一个workqueue_struct

-
-
外部使用的意思就是如果要使用工作队列,就是创建好work_struct结构,然后调用schedule_work即可,剩下的处理任务就是系统部分完成了。每个和外部交互的workqueue_struct,对应有多个pwq(pool_workqueue),pool_workqueue 链接workqueue_struct和worker_pool的桥梁,worker_pool是核心所在,其包含有所有的worker,以及该pool对应的item即work_struct。其中worker其实就是一个线程,根据busy后者空闲位于hash表或者链表中。而所有的item就通过双链表的方式链接到worker_pool维护的链表头上。
-
具体介绍
- workqueuq(workqueue_struct)
-
该结构是 externally visible workqueue,即外部可见的工作队列,而其本身主要描述队列的属性,既不包含worker也不包含work。一个workqueue对应多个pwd,这些pwq链接在workqueue_struct结构中的pwqs链表头上。而系统中所有的workqueue通过list字段链接成双链表。系统内部已经定义了几个workqueue,如下所示

-
系统中通过schedule_work均是把work加入到system_wq中。从代码来看,系统中的workqueue根据使用情况可以分为两种:普通的workqueue和unbound
workqueue。前者的worker一般是和CPU绑定的,系统会为每个CPU创建一个pwd,而针对后者,就不和单个CPU绑定,而是针对NUMA节点,创建pwd。
- worker
-
worker是具体处理work的对象,系统把worker作为一种资源管理,提出了worker_pool的概念,一个worker必定会属于某个worker_pool,worker结构如下

-
一个worker根据自身状态不同会处于不同的数据结构中,当worker没有任务要处理就是idle状态,处于worker_pool维护的链表中;当worker在处理任务,就处于worker_pool维护的hash表中。task字段指向该worker对象线程的task_struct结构。pool指向其隶属的worker_pool。而如果该worker是一个rescuer
worker,最后一个字段指向其对应的workqueue。当worker在处理任务时,current_work指向正在处理的work,current_func是work的处理函数,current_pwd指向对应的pwq。worker的线程处理函数为worker_thread。

-
从该函数可以看出worker只有在处理任务时,才是idle状态。在执行任务前通过worker_leave_idle把worker从idle链表摘下并清除idle标志。然后会检查当前pool是否需要更多的worker,如果不需要则继续睡眠。怎么判断是否需要呢?这里有一个函数need_more_worker

-
针对unbound pool,只要存在work,那么该函数就返回true,因为unbound的pool并不计算nr_running。但是从这里看,针对普通的pool,只有在worklist不为空且没有正在运行的worker时才会返回true,那么怎么同时让多个worker同时运行呢??不解!如果确实需要则检查下是否需要管理worker,因为此时需要worker,所以需要判断下有没有idle的worker,如果没有则调用manage_workers进行管理,该函数中两个核心处理函数就是maybe_destroy_workers和maybe_create_worker。待检查过后,就开始具体的处理了,核心逻辑都在一个循环体中。
-
具体处理过程比较明确,先从pool的worklist中摘下一个work,如果该work没有设置WORK_STRUCT_LINKED标志,就直接调用process_one_work函数进行处理,如果worker->scheduled链表不为空,则调用process_scheduled_works对链表上的work进行处理;如果work设置了WORK_STRUCT_LINKED标志,则需要把work移动到worker的scheduled链表上,然后通过process_scheduled_works进行处理。而循环的条件是keep_working(pool),即只要worklist不为空且在运行的worker数目小于等于1(这里也不太明白,为何是小于等于1)。处理单个work的流程看process_one_work
-
该函数一个比较重要的验证就是判断当前work是否已经有别的worker在处理,如果存在则需要把work加入到对应worker的scheduled链表,以避免多个worker同时处理同一work;如果没问题就着手开始处理。具体处理过程比较简单,把worker加入到busy的hash表,然后设置worker的相关字段,主要是current_work、current_func和current_pwq。然后把work从链表中删除,之后就执行work的处理函数进行处理。当worker处理完成后,需要把worker从hash表中删除,并把相关字段设置默认值。
-
process_scheduled_works就比较简单,就是循环对worker中scheduled链表中的work执行处理,具体处理方式就是调用process_one_work。
- worker_pool
-
worker_pool本身的重要任务就是管理worker,除此之外,worker_pool还管理用户提交的work。在worker_pool中有一个链表头idle_list,链接worker中的entry,对应于空闲的worker;而hash表busy_hash链接worker中的hentry,对应正在执行任务的worker。nr_workers和nr_idle代表worker和idle worker的数量。系统中worker_pool是一个perCPU变量,看下worker_pool的声明
-
static DEFINE_PER_CPU_SHARED_ALIGNED(struct worker_pool [NR_STD_WORKER_POOLS], cpu_worker_pools);
-
每个CPU对应有两个worker_pool,一个针对普通的workqueue,一个针对高优先级workqueue。而PWQ也是perCPU变量,即一个workqueue在每个CPU上都有对应的pwq,也就有对应的worker_pool。
-
workqueue的创建以及worker的管理。
-
工作队列的创建(__alloc_workqueue_key)


-
该函数主要任务就是通过kzalloc分配一个workqueue_struct结构,然后格式化一个名称,对workqueue进行简单初始化;’接着就调用 和pwd建立关系。我们暂且不考虑WQ_MEM_RECLAIM的情况,那么该函数主要就完成这两个功能。所有的workqueue会链接成一个链表,链表头是一个全局静态变量
- static LIST_HEAD(workqueues); / PL: list of all workqueues /
-
本函数比较重要的就是和pwq建立关系了

-
这里先知考虑普通的workqueue,不考虑WQ_UNBOUND。函数通过alloc_percpu为workqueue分配了pool_workqueue变量,然后通过for_each_possible_cpu,对每个CPU进行处理,实际上就是把对应的pool_workqueue和worker_pool通过init_pwq关联起来。如上一篇文章所描述的,worker_pool分为两种:普通的和高优先级的。普通的为第0项,而高优先级的为第一项。建立关联后在通过link_pwq把pwq接入wq的链表中。
- worker的创建
-
在创建好workqueue和对应的pwq以及worker_pool后,需要显示的为worker_pool创建worker。核心函数为create_and_start_worker

-
这里是针对worker_pool创建worker,所以worker_pool作为参数传递进来,而具体执行创建任务的是create_worker函数,且由于有专门的worker manager,故这里给worker_pool增加worker需要加锁。create_worker函数其实也不复杂,核心任务主要包含以下几个步骤:
-
通过alloc_worker分配一个worker结构,并执行简单的初始化
-
在worker和worker_pool之间建立联系
-
通过kthread_create_on_node创建工作线程,处理函数为worker_thread
-
设置线程优先级
-
-
初始状态下是为每个worker_pool创建一个worker。创建好之后通过start_worker启动worker
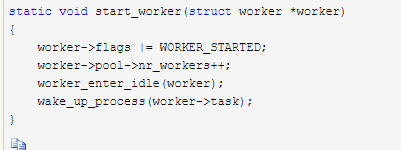
-
该函数较简单,首先就更新worker状态为WORKER_STARTED,增加pool中worker统计量;然后通过worker_enter_idle标记worker目前处于idle状态;最后通过wake_up_process唤醒worker。我们看下中间设置idle状态的过程

-
该函数会设置WORKER_IDLE,递增pool的nr_idle计数,然后更新last_active为当前jiffies。接着把worker挂入pool的idle_list的链表头.默认状态下,一个worker在idle状态停留的最长时IDLE_WORKER_TIMEOUT,超过这个时间就要启用管理工作。这里的last_active便是纪录进入idle状态的时间,
-
worker的管理
-
系统中会根据实际对worker的需要,动态的增删worker。针对idle
worker,worker_pool中有个定时器idle_timer,其处理函数为idle_worker_timeout,看下该处理函数
-
该函数主要是针对系统中出现太多worker的情况进行处理,如何判定worker太多呢?too_many_workers去完成,具体就是 nr_idle > 2 && (nr_idle - 2) * MAX_IDLE_WORKERS_RATIO >=nr_busy决定,其中MAX_IDLE_WORKERS_RATIO为4。当的确idle worker太多了的时候,取最先挂入idle链表中的worker,判定其处于idle状态的时间是否超时,即超过IDLE_WORKER_TIMEOUT,如果没有超时,则通过mod_timer修改定时器到期时间为该定时器对应的最长idle时间,否则设置pool的POOL_MANAGE_WORKERS状态,唤醒pool中的first worker执行管理工作。在worker的处理函数worker_thread中,通过need_more_worker判断当前是否需要更多的worker,如果不需要,则直接goto到sleep

-
need_to_manage_workers就是判断POOL_MANAGE_WORKERS,如果设置了该标志则返回真。
管理worker的核心在manage_workers,其中只有两个关键函数
-
maybe_destroy_workers

-
该函数中会在此通过too_many_workers判断是否有太多worker,如果是,则再次取最后一个worker,检查idle时间,如果没有超时,则修改定时器到期时间,否则通过destroy_worker销毁worker。为什么要这样判断呢?通过对代码的分析,我感觉manage_work不仅负责删除,还负责增加worker,定时器主要是针对idle worker即目的是销毁多余的worker,但是执行管理任务的工作集成到了worker_thread中,因此就worker_thread而言,有可能需要增加、有可能需要删除、还有可能不需要管理。因此这里需要再次判断。
-
work的添加

-
主体就是__queue_work,其中一个核心工作就是调用了insert_work

-
函数首先调用set_work_pwq把pwd写入到work的data字段,然后把work加入到worker_pool维护的work链表中,在最后判断现在是否需要更多worker,如果需要,则执行唤醒操作。当然是针对当前worker_pool,且唤醒的是worker_pool的第一个worker。其实在queue_work中,为避免work重入,在选定worker_pool的时候会判断该work是否仍在其他worker_pool上运行,如果是,就把该work挂入对应worker_pool的work_list上
















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









