









redis基础数据结构与分布式锁
Redis大纲
- 是什么 + 优缺点 + 为什么用
- 性能高的原因
- 单线程与NIO模型 https://www.cnblogs.com/my_life/articles/5320230.html 单reactor单线程模式
- 基础数据结构有哪些、应用场景
底层数据结构有哪些 - 应用:
分布式锁:简单写法与注意事项;redisson写法原理;
性能优化:分段;切换时候的锁丢失
一定要注意锁的释放:finally
获取锁的时候加时间,防止过程中失效;加时间注意原子性
释放锁的时候避免误释放,需要加线程判断
锁续命,避免释放的过程中阻塞
最大问题,主从切换时候的锁丢失:readlock。zookeeper比较
6. 缓存与数据库一致性问题解决方案
7. 持久化:RDB、AOF
RDB:when、where、how(fork)、原理
AOF:why、when(no、always、1s)、how(缓冲区-》磁盘)、重写机制(子进程,影响性能)
混合
8. 过期key + 内存淘汰
9. 主从,如何同步。全量-》增量,手动恢复
10. 三种集群:哨兵的三种同步与选举主的策略
集群原因与插槽
为什么要集群、各自解决什么问题
11. 事务与pipeline
12. 缓存穿透、击穿、雪崩,原因与解决
redis是什么
是一个高性能的、基于内存的、key-value型数据库。
Redis 与其他 key - value 缓存产品有以下特点:
优点
- 读写性能优异, Redis能读的速度是110000次/s,写的速度是81000次/s。
- 支持数据持久化,支持AOF和RDB两种持久化方式。
- 支持事务,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
- 数据结构丰富,除了支持string类型的value外还支持hash、set、zset、list等数据结构。
- 支持高可用,支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
- 容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
- 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
- 高并发的局限性,数据不一致问题:主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
- 高可用的局限性,Redis 较难支持在线扩容:在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
为什么要用 Redis /为什么要用缓存
主要从“高性能”和“高并发”这两点来看待这个问题。
高性能:磁盘IO-》内存IO
高并发:缓存能够承受的请求是远远大于直接访问数据库的
redis性能高的原因
- 基于内存操作
- IO模型:多路复用IO模型。采用了NIO单Reactor单线程模型,避免了IO阻塞。
- 单线程,避免频繁的上下文切换
- 底层数据存储结构非常高效
底层数据结构解释:
数据存储在全局哈希表中
redis底层实现了自己的hash算法。hash碰撞时,用链表继续向这个数组存储,会对性能造成影响
redis渐进式rehash以及动态扩容机制能够有效防止hash碰撞,也是性能高的原因之一。

hash的key都是string,value有许多种存储结构。不同的value底层有不同的存储形式
value为String时候的几种不同存储结构实例:

其中object encoding key为查看key对应value的具体存储类型。zhuge对应的是纯int类型,因此可以自增

不同的value有不同的存储结构也有不同适用的操作类型
不同数据类型的使用场景
String
对象转化为json串存入,取出的时候自己做解析即可
计数器:自增key即可
ID分发器:分库分表的时候,不能使用数据库自己的自增ID,可以用redis进行管理,但是不能一个个管理id,否则会造成较大性能损耗,可以以百为单位管理,应用程序批量获取100个ID,而不是每用一个ID就要请求一次redis
存在问题:ID丢失。但是面临部分ID丢失但是挽救了性能。


hash:可以理解为双层map

与json之间的区别:取决于对象字段是否经常发生变动,如果是一些固定字段发生变动,hash存储非常方便,直接定位与直接变动
如果是字段本身就有改变的需求,那么用json

list:

为什么不用jdk的数据结构而是使用redis?
因为jdk只能在一个应用程序中进行,无法完成跨集群的实例共享,而redis就能在一个集群中完成操作,实现分布式数据结构

list本身自带排序
实时推送消息的难点:按照最新消息排序,需要执行orderBy命令,效率低下,所以直接用list
对于推送的优化:在线用户实时推送,非在线用户起一个后台任务一批批去推送
set结构应用


求集合操作:实际上就是朋友圈点赞模型谁可以看的原型

SDIFF:set1 - (set2 + set3)

Zset
与set的区别;有序。根据传入的分值进行排序

底层数据结构

Zset
默认使用压缩列表
压缩列表:比起链表而言,存储了偏移量,方便迅速定位到具体的元素

详解:
https://blog.csdn.net/g6u8w7p06dco99fq3/article/details/106821287?ops_request_misc=&request_id=&biz_id=102&utm_term=redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E8%AF%A6%E8%A7%A3&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-5-106821287.first_rank_v2_pc_rank_v29
跳表:十字链表
在链表上进行优化,每两个元素建立索引层。实际上有二分查找的思路,元素越多查找效率越高

空间换时间,多占用了一倍空间,换取了一倍的时间
顶层存储的是索引键值,不是完整的数据,类似MySQL B+树的索引

元素越多,使用跳表,效率越高


可以自定义转为跳表的元素个数
Redis分布式锁
Java锁失效的原因
单机场景下的redis库存checkOut功能实现:

在分布式集群场景下是无法使用该锁的,这种锁只能处理单机,对于多个jvm无法防护

只能锁单个
分布式锁的一般实现思路
分布式锁实现应该考虑哪些条件
• 在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
• 高可用、高性能的获取锁与释放锁;
• 具备可重入特性;
• 具备粒度控制,读写锁分离;
• 具备锁失效机制、防止死锁;
• 具备非阻塞锁特性,即没有获取到锁直接返回获取锁失败;
• ……
分布式锁的具体实现方案有如下三种:通过对控制可以共同访问的资源的并发度实现
基于数据库实现;
基于缓存(Redis、ignite等)实现;
基于Zookeeper实现;
使用redis创建分布式锁:SETNX

分布式锁的进化之路
几个注意点:
- 一定要注意锁的最终释放:finally
- 获取锁加时间的原子性
- finally块中释放锁的时候避免误释放,需要加线程判断
- 锁续命,避免finally释放的过程中二次阻塞
- 最大问题,主从切换时候的锁丢失:readlock

问题1:
业务逻辑出现异常的场景,在执行delete锁过程前抛出异常,就会造成死锁
所以第一个优化点要将delete放入finally当中

问题2:
宕机场景:即执行业务逻辑过程中突然一台服务器宕机,无法执行任何操作,这个时候也走不到finally中
所以:超时时间

宕机场景下,后续redis也可以处理
问题3:原子性问题,即如下2行代码不具备原子性

在result到下一步的操作之间不是原子性的,如果两步中间出了问题,也会死锁
解决:用redis的原子性加锁方式

问题4:执行超时导致的分布式锁失效
线程1执行时间

超过10s,于是锁自动释放;线程2申请进来拿到锁,这个时候线程1执行完毕,删掉锁,线程2的锁立即失效
同时导致对于数据库数据的保护失效

在删除锁之前判断该锁当前是否还是自己持有的,通过clientID进行判断。如果ID不再是自己的ID说明已经失效掉了,这只是初步解决了删除锁的问题:即线程1删除了线程2持有的锁
另一个问题出现了:
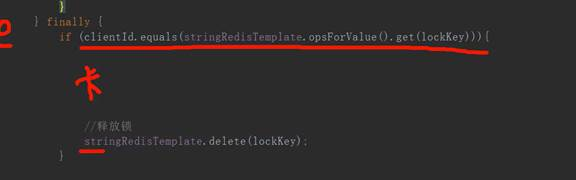
非原子性的操作,出现与问题3一样的错误,线程1又删除了线程2的锁
解决方案:锁续命。再开一个线程起一个定时器,每过30s给锁续一次命,保证锁一直没有失效。
一个解决方案:
Redisson:开源框架,提供了一种分布式锁,提供了对应的API,解决了上述锁续命问题

修改如下:

实际上底层是封装了redis:
后台起了一个watchdog线程不断进行锁续命,比如锁的时间是30s,每过10s检测一下锁是否还存在,如果不存在就续命


源码:

https://mp.weixin.qq.com/s?__biz=MzU0OTk3ODQ3Ng==&mid=2247483893&idx=1&sn=32e7051116ab60e41f72e6c6e29876d9&chksm=fba6e9f6ccd160e0c9fa2ce4ea1051891482a95b1483a63d89d71b15b33afcdc1f2bec17c03c&mpshare=1&scene=23&srcid=1121Vlt0Mey0OD5eYWt8HPyB#rd
用了lua脚本
其中keys[1]就是之前代码中的lockKey;pexpire就是设置超时时间。第一段意思就是:查某个key是否存在,不存在设置值并且设置超时时间
核心实际上是:在redis在执行lua脚本的过程中将这些操作都当做原子性操作来执行,一条语句搞定
数据丢失问题:
异步复制过程中可能会出现的问题/主从节点切换过程中数据丢失问题:在主从节点复制过程中,master节点突然挂了,最新线程2加到的锁没有同步复制给slave节点。这个时候由于master节点挂点,slave节点被选举为主节点,这个时候原本运行的2线程在checkout资源,某一个新到的线程3也成功地在新master取到节点并且checkout资源。

由此引出zookeeper架构
结构上属于树形架构。

redis与zookeeper比较
从CAP角度去看

- redis主从之间使用的异步复制策略,主要保证AP,保证性能
- zookeeper则是保证CP,保证数据一致性。在线程向主节点申请key的时候,首先去向follower节点同步key,在保证半数以上节点都同步到数据之后才会返回给线程,告知线程申请成功。
zookeeper存在ZAB选举机制,在master节点挂掉之后,通过选举,一定能够保证同步了所有数据的follower节点被选举为master节点。
因此使用zookeeper,不会出现上述redis异步复制过程中出现的问题
在进行选型时要遵循CAP原则,看一下业务对哪个方面要求高,如果要保证1数据一致性,使用zookeeper实现分布式锁,如果要保证性能,使用redis
zookeeper性能不如redis
这种问题的解决使用readLock


锁的性能问题:
性能问题:只有一个加锁成功的线程会运行,其他线程都会自旋阻塞
分布式锁天生与高性能是违背的,将并行转化为串行,天性违背高并发
解决方案:
资源分段,分段锁;锁的粒度:读写锁;代码块控制:尽量少的代码;机制上:乐观锁而不是悲观锁
优化方案:借用并发包中的并发hashmap机制,分段锁

将一个资源分段存储,并将这些资源尽可能放置在不同的节点上去,进行性能的优化
要实现负载均衡,如果某个不够减,则进行多个资源的合并减。
分布式锁的例子:
https://blog.csdn.net/qq_40823910/article/details/107452493?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161415127916780357244926%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=161415127916780357244926&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-107452493.first_rank_v2_pc_rank_v29&utm_term=redis+%E5%88%86%E6%AE%B5%E9%94%81
原理:
https://yq.aliyun.com/articles/674394
缓存数据库双写不一致问题:
遇到的实际场景:权限变更

修改删除,读取更新:
修改数据库就删掉缓存,查询的时候更新缓存,一定程度上避免数据库与缓存不一致的问题,无法彻底避免:阻塞导致线程2的更新线程3并没有收到

1删除缓存
2查到缓存没了,开始查询数据库,并启动缓存更新,然而更新过程中阻塞了
3又删除了缓存
这个时候2阻塞结束,取自己在3之前时间段的过期数据更新了缓存
造成缓存数据库不一致问题
数据库与缓存一致性的设计:Mybatis即采用这种方案
从根本上解决问题的方案:读写锁控制

另一种方案:
延迟双删的方案:对应于延迟加载。blockingqueue的实例

一定程度上解决问题,但是如果线程3查数据库与更新缓存之间的时间超过了sleep的时间还是无法解决不一致问题
而且延迟双删造成了所有的写数据库的操作都要删除2次缓存,代价比较高
问题本质:非原子性操作导致
解决思路:使用分布式锁将所有操作都变为串行执行,线程1、2、3都加锁保证串行执行,但是问题是:性能问题

性能问题解决2:
解决方案1:读写锁
大多数场景读多写少,乐观锁


key相同就是同一把锁
底层也是用lua脚本实现
Mybatis的缓存一致性实现方案:就是采用并发包的读写锁实现的,先查询二级缓存然后查询一级缓存
https://blog.csdn.net/qq_25689397/article/details/52066179?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&dist_request_id=1328603.12044.16149349877007267&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.control
redis教程
http://www.redis.cn/documentation.html
https://www.runoob.com/redis/redis-commands.html
















 3192
3192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









