






Kafka高吞吐特性分析
Kafka的特性之一就是高吞吐率,但是Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,但是Kafka即使是普通的服务器。Kafka也可以轻松支持每秒百万级的写入请求,超过了大部分的消息中间件,这种特性也使得Kafka在日志处理等海量数据场景广泛应用。Kafka会把收到的消息都写入到硬盘中,防止丢失数据。为了优化写入速度Kafka采用了两个
技术顺序写人和MMFile 1115211849342
因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最讨厌随机I/O,最喜欢顺序1/O。为了提高读写硬盘的速度,Kafka就是使用顺序1/O。这样省去了大量的内存开销以及节省了1O寻址的时间。但是单纯的使用顺序写入,Kafka的写入性能也不可能和内存进行对比,因此Kafka的数据并不是实时的写人硬盘中。
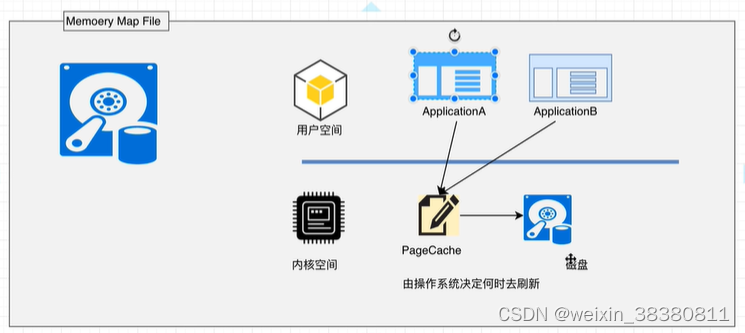
Kafka充分利用了现代操作系统分页存储来利用内存提高1/O效率。Memorv Mapped Files(后面简称mmap)也称为内存映射文件,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的Page实现文件到物理内存的直接映射。完成MMP映射后,用户对内存的所有操作会被操作系统自动的刷新到磁盘上,极大地降低了1O使用率。
一、Message Queue
消息队列是一种在分布式和大数据开发中不可或缺的中间件。在分布式开发或者大数据开发中通常使用消息队列进行缓冲、系统间解耦和削峰填谷等业务场景,常见的消息队列工作模式大致会分为两大类:
-至多一次:消息生产者将数据写人消息系统,然后由消费者负责去拉去消息服务器中的消息,-旦消息被确认消费之后,由消息服务器主动删除队列中的数据,这种消费方式一般只允许被一个消费者消费,并且消息队列中的数据不允许被重复消费。
没有限制:同上诉消费形式不同,生产者发不完数据以后,该消息可以被多个消费者同时消费。并且同一个消费者可以多次消费消息服务器中的同一个记录。主要是因为消息服务器一般可以长时间存储海量消息。
二、Kafka基础架构
Kafka集群以Topic形式负责分类集群中的Record每一个Record属于一个Topic,每个Topic底层都会对应一组分区的日志用于持久化Topic中的Record。同时在Kafka集群中,Topic的每一个日志的分区都一定会有1个Borker担当该分区的Leader,其他的Broker担当该分区的follower
Leader负责分区数据的读写操作,follower负责同步改分区的数据。这样如果分区的Leader宕机。改分区的其他follower会选取出新的leader继续负责该分区数据的读写。其中集群的中Leader的监控和Topic的部分元数据是存储在Zookeeper中。
三、分区&日志
Kafka中所有消息是通过Topic为单位进行管理,每个Kafka中的Topic通常会有多个订阅者负责订阅发送到改Topic中的数据。Kafka负责管理集群中每个Topic的一组日志分区数据。
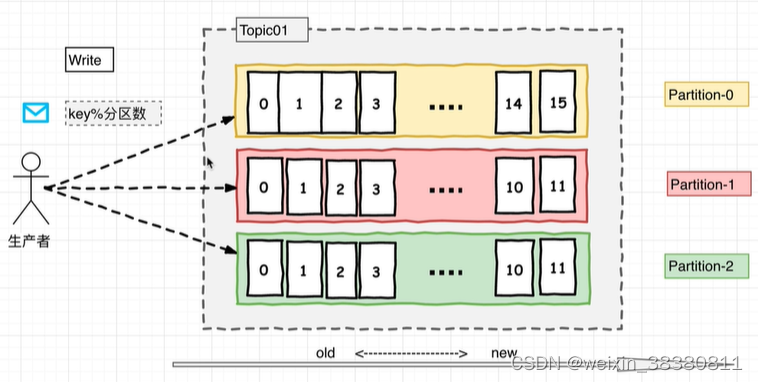
生产者将数据发布到相应的Topic。负责选择将哪个记录分发送到Topic中的哪个Partition。例如可以round-robin方式完成此操作,然而这种仅是为了平衡负载。也可以根据某些语义分区功能(例如基于记录中的Key)进行此操作。
每组日志分区是一个有序的不可变的的日志序列,分区中的每一个Record都被分配了唯一的序列编号称为是offsetKafka集群会持久化所有发布到Topic中的Record信息,改Record的持久化时间是通过配置文件指定,默认是168小时。
log.retention.hours=168
Kafka底层会定期的检查日志文件,然后将过期的数据从log中移除,由于Kafka使用硬盘存储日志文件,因此使用Kafka长时间缓存一些日志文件是不存在问题的。
在消费者消费Topic中数据的时候,每个消费者会维护本次消费对应分区的偏移量,消费者会在消费完一个批次的数据之后,会将本次消费的偏移量提交给Kafka集群,因此对于每个消费者而言可以随意的控制改消费者的偏移量。因此在Kafka中,消费者可以从一个topic分区中的任意位置读取队列数据,由于每个消费者控制了自己的消费的偏移量,因此多个消费者之间彼此相互独立。
Kafka中对Topic实现日志分区的有以下目的:
-首先,它们允许日志扩展到超出单个服务器所能容纳的大小。每个单独的分区都必须适合托管它的服务器,但是一个Topic可能有很多分区,因此它可以处理任意数量的数据。
-其次每个服务器充当其某些分区的Leader,也可能充当其他分区的Follwer因此群集中的负载得到了很好的平衡。
四、顺序写入&MMF
五、零拷贝
Zero Copy
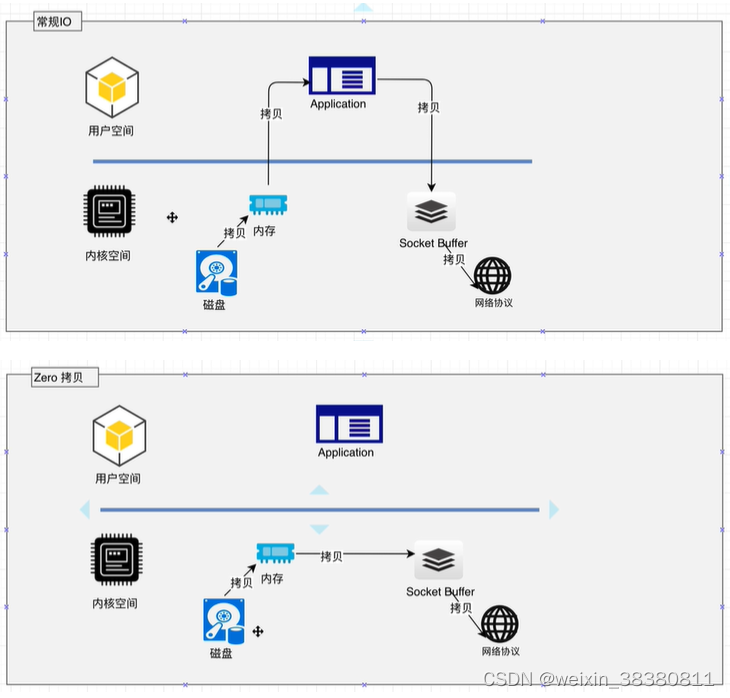
Kafka服务器在响应客户端读取的时候,底层使用ZeroCopy技术,直接将磁盘无需拷贝到用户空间,而是直接将数据通过内核空间传递输出,数据并没有抵达用户空间。
传统IO操作
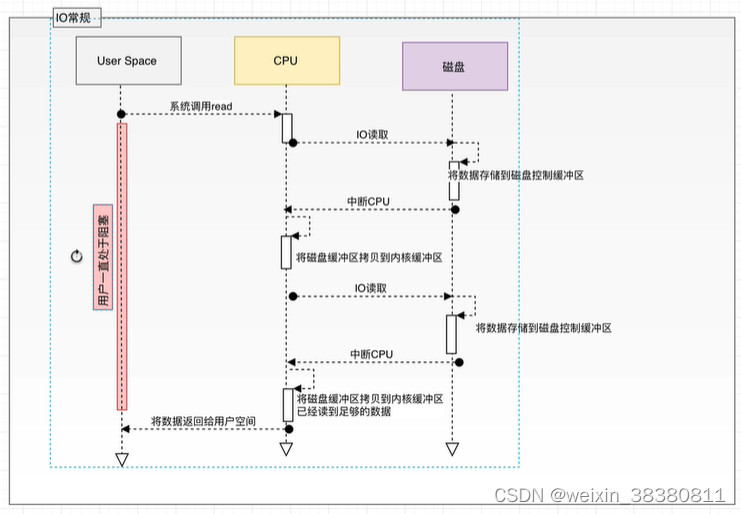
1.用户进程调用read等系统调用向操作系统发出O请求,请求读取数据到自己的内存缓冲区中自己进入阻塞状态。
-2.操作系统收到请求后,进一步将IO请求发送磁盘。
-3.磁盘驱动器收到内核的IO请求,把数据从磁盘读取到驱动器的缓冲中。此时不占用CPU。当驱动器的缓冲区被读满后,向内核发起中断信号告知自己缓冲区已满。
-4.内核收到中断,使用CPU时间将磁盘驱动器的缓存中的数据拷贝到内核缓冲区中。
-5.如果内核缓冲区的数据少于用户申请的读的数据,重复步骤3跟步骤4,直到内核缓冲区的数据足够多为止。
-6.将数据从内核缓冲区拷贝到用户缓冲区,同时从系统调用中返回。完成任务
DMA读取
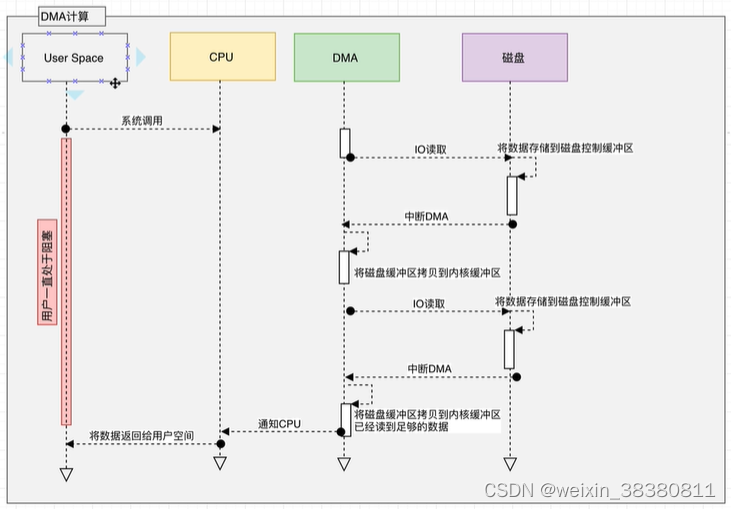
-1.用户进程调用read等系统调用向操作系统发出O请求,请求读取数据到自己的内存缓冲区中。自己进入阻塞状态。
- 2.操作系统收到请求后,进一步将IO请求发送DMA,然后让CPU干别的活去 -3.DMA进一步将1O请求发送给磁盘。
-4.磁盘驱动器收到DMA的IO请求,把数据从磁盘读取到驱动器的缓冲中。当驱动器的缓冲区被读满后,向DMA发起中断信号告知自己缓冲区已满。
-4.DMA收到磁盘驱动器的信号,将磁盘驱动器的缓存中的数据拷贝到内核缓冲区中。此时不占用CPU。这个时候只要内核缓冲区的数据少于用户申请的读的数据,内核就会一直重复步骤3跟步骤4,直到内核缓冲区的数据足够多为上
-5.当DMA读取了足够多的数据,就会发送中断信号给CPU
-6.CPU收到DMA的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回。
跟IO中断模式相比,DMA模式下,DMA就是CPU的一个代理,它负责了一部分的拷贝工9作425从而减轻了CPU的负担。DMA的优点就是:中断少,CPU负担低。
总结
Kafka高吞吐特性节点分析:
分区&日志、顺序写入&MMF、零拷贝 致使kafka高吞吐
















 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









