







文章目录
- 数据存储的发展
- 一、epoll介绍
- 二、单节点安装部署
- 三、常用命令(与数据类型无关)
- 四、String数据类型
- 五、list数据类型
- 六、hash数据类型
- 七、set数据类型
- 八、sorted_set
- 九、管道
- 十、发布订阅
- 十一、事务
- 十二、module
- 十三、redis作为缓存——内存瓶颈
- 十四、持久化
- 十五、AKF
- 十六、CAP
- 十七、主从复制
- 十八、哨兵
- 十九、集群
- 二十一、分布式锁
- 二十二、数据一致性解决方案
- 缓存
- 秒杀

数据存储的发展
1、硬盘
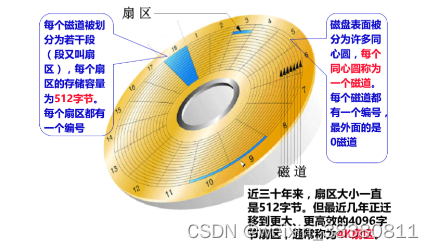
寻址时间:
- 磁盘的寻址时间时毫秒级
- 内存的寻址时间时纳秒级
带宽(单位时间内得传输量):
- 磁盘带宽G/m
- 内存大很多
磁盘数据度取
一个扇区得大小为512Byte,如此造成索引增多从而读取速度和磁盘空间占用成本变大。通常从磁盘读取数据时都是按照4k对齐规则进行获取,
IO成本变大。
2、数据库(关系型数据库)
关系型数据库在创建表时就必须指定各个字段的类型以及占用空间,插入数据时即使某一行没有数据依旧规定占用空间,如此若倾向于行级存储时无需移动数据空间索引。
数据库的使用如果不加索引的话,性能不会比磁盘文件直接读取写入快。
一但使用了索引:
- 增删改会变慢,因为需要维护索引
- 少量查询变很快
高并发查询时,会受到硬盘带宽影响速度
3、数据存储参考网站
数据库存储引擎参考网站
Redis VS Memcache: redis计算向数据移动
一、epoll介绍
1、BIO
2、NIO
3、多路复用NIO
4、epoll
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、单节点安装部署
1、linux安装
1、下载redis
[root@localhost /]# cd /
[root@localhost /]# mkdir redis
[root@localhost /]# cd redis
[root@localhost redis]# wget http://download.redis.io/releases/redis-6.0.8.tar.gz
2、解压
[root@localhost redis]# tar xzf redis-6.0.8.tar.gz
3、编译
[root@localhost redis]# cd redis-6.0.8
[root@localhost redis-6.0.8]# make
4、运行redis服务端
[root@localhost redis-6.0.8]# cd src
[root@localhost src]# ./redis-server
5、运行redis客户端
再打开一个客户端连接redis服务器
[root@localhost redis-6.0.8]# cd src
[root@localhost src]# ./redis-cli
6、将redis作为服务安装到系统中(提取安装环境分离源码)
[root@localhost redis-6.0.8]# cd utils
[root@localhost utils]# ./install_server.sh
This script will help you easily set up a running redis server
This systems seems to use systemd.
Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!
---------------*************-出现上述问题,将如下内容注释掉即可************----------------------
vim /redis/utils/install_server.sh
#bail if this system is managed by systemd
#_pid_1_exe="$(readlink -f /proc/1/exe)"
#if [ "${_pid_1_exe##*/}" = systemd ]
#then
# echo "This systems seems to use systemd."
# echo "Please take a look at the provided ece unit files in this directory, and adapt and install them. Sorry!"
# exit 1
#fi
再次安装服务
[root@localhost utils]# ./install_server.sh
----------------------------------------------------------------------------------------------------
Welcome to the redis service installer
This script will help you easily set up a running redis server
Please select the redis port for this instance: [6379] ---端口号
Selecting default: 6379
Please select the redis config file name [/etc/redis/6379.conf] ----配置文件
Selected default - /etc/redis/6379.conf
Please select the redis log file name [/var/log/redis_6379.log] ----日志文件
Selected default - /var/log/redis_6379.log
Please select the data directory for this instance [/var/lib/redis/6379] -----数据文件
Selected default - /var/lib/redis/6379
Please select the redis executable path [/opt/redis/bin/redis-server] -----服务安装路径(根据配置好得path得来的)
Selected config:
Port : 6379
Config file : /etc/redis/6379.conf
Log file : /var/log/redis_6379.log
Data dir : /var/lib/redis/6379
Executable : /opt/redis/bin/redis-server
Cli Executable : /opt/redis/bin/redis-cli
Is this ok? Then press ENTER to go on or Ctrl-C to abort. ----提示回车表示同意执行 Ctrl-C取消
Copied /tmp/6379.conf => /etc/init.d/redis_6379 ----可执行文件得位置
Installing service...
Successfully added to chkconfig!
Successfully added to runlevels 345!
/var/run/redis_6379.pid exists, process is already running or crashed
Installation successful!
以上步骤中可能出现的问题:
Please select the redis executable path [] [/opt/redis/bin/redis-server]
Mmmmm... it seems like you don't have a redis executable. Did you run make install yet?
问题很明显[ ],里没有东西,这设置系统程序时其他[ ]里都是有路径的。
需要在[ ]没有路径下加入自己的/src/redis-server,这个路径一般是自己解压或者安装的路径。
Please select the redis executable path [] /redis/redis-6.0.8/src/redis-server
测试是否可以执行 redis的执行文件
[root@localhost /]# systemctl status redis_6379.service
Redis is not running
关闭防火墙
setenforce 0 #setenforce 0 表示关闭selinux防火墙
systemctl stop firewalld.service #关闭防火墙*
对外开启访问权限
1、 vim /etc/redis/6379.conf
protected-mode no ----注释掉redis.window.conf文件中的bind属性设置
#bind 127.0.0.1 ----注释掉redis.window.conf文件中的bind属性设置
这里可以使用快捷键查找 :/protected 按n健查找下一个关键词所在位置
重启redis
systemctl status redis_6379.service
systemctl stop redis_6379.service
systemctl start redis_6379.service
2、Windows安装
https://github.com/MicrosoftArchive/redis/releases
https://github.com/redis-windows/redis-windows/releases/tag/7.0.10
三、常用命令(与数据类型无关)
1、切换数据库
select 0
select 1
select 2
...
select 15
redis-cli -p 6379 -n 1 #开启客户端时指定连接的库
2、清库
flushdb
flushall
3、查看所有keys
keys *
4、帮助命令
help @string
help @list
四、String数据类型
redis是二进制安全的
1 字符串
set key value [nx | xx]
nx:当key不存在时才能设置成功;应用场景:分布式锁
xx:只有key已经存在才能更新成功
#批量设置
mset key1 value1 key2 value2
#批量获取
mget key1 key2
#追加字符串
append key1 valueappend
getrange key [startIndex] [endIndex]
getrange key 0 -1
# 从index位置开始覆盖
setrange key [index] [value]
# 获取字符串值得长度
strlen key
#原子性操作
msetnx key1 value1 key2 value2
2 数值
#设置数据
set key 99
#查看key类型
type key1
#查看编码类型
object encoding key1
incr key
incrby key [number]
incrbyfloat key [number]
decr key
decrby key [number]
3 bitmap(位图)
1byte = 8bit
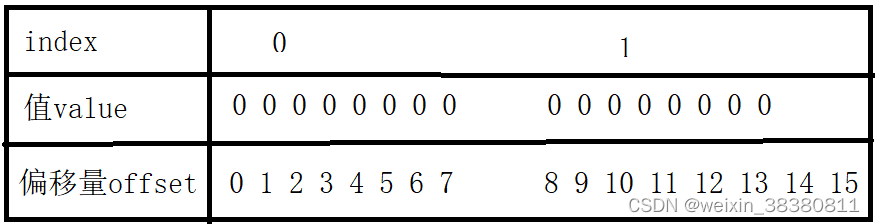
setbit key [offset] [value]
setbit key 1 1 #结果01000000
get key #结果01000000 = @
bitpos key bit [startIndex] [endIndex]
#查找字符串中start字节到end字节中第一个bit=0|1的位的offset
#如果在star到end之间不存在bit的值则返回-1
#如果在star和end省略不写,又不存在bit=0的值则返回下一位offset,因为字符串看成右边有无数个0
bitpos key 0 0 0 #结果0
bitpos key 1 0 0 #结果1
bitop operation deskey key [key...]
setbit k1 0 1
setbit k2 0 1
bitop and resultkey k1 k2 #对k1 k2按位与,结果resultkey=11000000
bitop orresultkey k1 k2 #对k1 k2按位或,结果
BITCOUNT key [startINdex] [endINdex]
统计字符串被设置为1的bit数
应用场景:时间窗口随机
1、统计每个用户登录系统次数,按天计算:
setbit userId 00000.....0000 一共365位,每一位代表一天即可统计每个用户一年随机窗口内登录的天数 365/8=46byte就可以存储一个用户一年数据
2、统计系统活跃用户数:多个日期按位或即可
setbit 20221001 0 1 #0位置代表某一个用户,10月1日0用户登录过
setbit 20221001 5 1 #5位置代表某一个用户,10月1日5用户登录过
setbit 20221002 7 1 #7位置代表某一个用户,10月2日7用户登录过
setbit 20221003 0 1 #0位置代表某一个用户,10月3日0用户登录过
按位或:bitops or reskey 20221001 20221002 20221003
统计用户数:bitcount reskey
4、数据结构
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。

如图中所示,内部len为当前字符串实际分配的空间,capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M
内部结构是一个带长度信息的字节数组;
可以包含任何数据,比如jpg图片或者序列化的对象,规定字符串的长度不得超过512MB
5、应用场景
- 单个值缓存:
网关:第一次请求的服务节点生成一个用户token,并存储到Redis服务器,然后可以根据需要设置对应的过期时间,从而保证token过期之后的信息从Redis服务器移除
之后请求的节点只需要通过get命令从缓存中获取token验证合法性
- 对象缓存:
将对象进行json序列化后缓存起来。这样的数据可以采用String数据类型进行存储
一次性序列化
或者
mset uersId:name userId:age
- 计数器
接口限流用Redis作为计数器,
因为每秒会生成一个键,为了节省内存空间,可能需要一个定时任务,定时删除这些已经使用过的键 - 唯一自增的ID或者流水号
- 文章阅读数或者网页浏览数统计
- 简单的分布式锁
#给键seckil1001赋值并设置过期时间,如果之前不存在,则新增成功,返回1,表示抢到了锁
setnx secki11001 true ex 20 nx
#当其他客户端进来之后执行如下命令,返回0则表示锁被占用,只能后期继续尝试再次执行
setnx secly 11001 true ex 20 nx
#当第一个抢到锁的线程执行完业务之后,便可以删除键,让其他线程能抢到锁
del seckil1001
#其他线程执行如下命令时返回的结果是1,表示拿到了锁
setnx seckil1001 true
五、list数据类型
1、数据结构(双向链表)
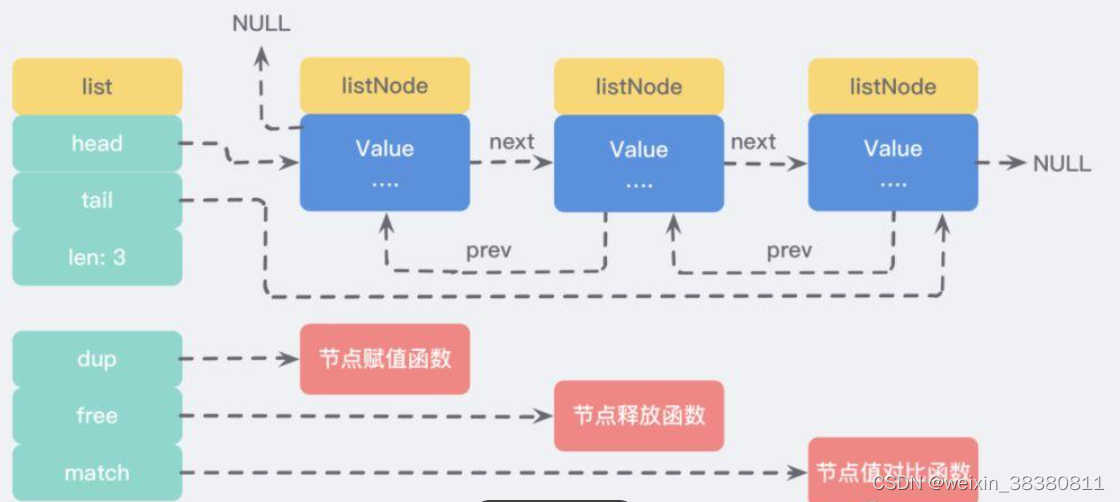
List的数据结构为快速链表quickList。
首先在列表元素较少的情况下会使用 ziplist 也即是压缩列表。
当数据量比较多的时候才会改成quicklist。
Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
2、特性
- 可以实现顺序排队和插队的操作
- List中的元素可以是重复的
- List(列表)中的元素是有序的,可以通过下标(或称为索引)来获取某个元素或者某个范围内的元素列表
- 增删快,提供了操作某一段元素的API
- 普通的链表需要的附加指针空间太大,会浪费空间,加重内存的碎片化
3、常用命令
3.1 栈操作:同向命令(先进后出)
lpush key value1 value2 value3....
lpop key
rpush key value1 value2 value3....
rpop key
3.2 队列操作:反向命令(先进先出)
lpush key value1 value2 value3....
rpop key
rpush key value1 value2 value3....
lpop key
3.3 数组操作:list元素正负索引特性
lpush key value1 value2 value3.... ##设置
lrange key 0 -1 ##取所有
lindex key [index] ##根据索引获取
lset key [index] [newValue] ##更新修改
3.4 双向链表特性的相关操作
linsert key before oldValue newValue
linsert key aflter oldValue newValue
lrem key +num value #移除前num个value值
lrem key -num value #移除后num个value值
ltrim key [startIndex endIndex] ##删除两端数据
3.5 阻塞单播队列FIFO(first in first out)
blpop key1 key2 key...... [timeout]
blpop key 0
4、应用场景:
- 消息排行等功能(比如朋友圈的时间线)
- 消息队列
六、hash数据类型
1、数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。
当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
2、常用命令
hset key attribute1 value1 attribute2 value2
hget key attribute1
hmget key attribute1 attribute2
hkeys key
hvals key
hgetall key
hincrby key attribute1 10
hincrby key attribute1 -10
hincrbyfloat key attribute1 10.5
hincrbyfloat key attribute1 -10.5
3、特点
适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去)。
4、应用场景
- String可以实现为何还要使用Hash呢?
内存占用率、时间复杂度和使用的简便性
-
作用实时数据库
存储、读取、修改对象属性,比如:用户(姓名、性别、爱好),文章(标题、发布时间、作者、内容)
//设置设备001的当前异常码为1 hset device:001 code 1
//设置设备001的温度为10 hset device:001 temperature 10
//设置设备的两种状态 hmset device:001 s1 start s2 stop
//获取设备001的所有属性 hgetall device:001
- 作为计数器
记录博客文章每月访问量
记录商品的好评数量、差评数量
记录网站实时在线人数
- 使用Hash数据类型实现购物车
以每个用户的userid作为Redis的键(Key),每个用户的购物车都是一个哈希表,它存储了商品ID与商品订购数量之间的映射关系。在商品的订购数量出现变化时,操作Redis哈希对购物车进行更新
七、set数据类型
Redis的集合相当于Java语言里面的HashSet,内部的键值对是无序的、唯一的
Set的结构底层实现是字典,只不过所有的value都是NULL,其他的特性和字典一摸一样
1、数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
2、特点
- 添加、删除、查找的复杂度都是O(1)
- 为集合提供了求交集、并集、差集等操作
- 无序,不可重复
- 很好的交集并集差集
3、常用命令
sadd key member1 member2.... #设置
smembers key #查看所有元素
srem key member1 member3 #移除
#交集
sinter key1 key2
sinterstore keyres key1 key2
#并集
sunion key1 key2
#差集
sdiff key1 key2
sdiff key2 key1
#随机取出,不对原有集合元素产生影响
(
正数:取出一个去重的结果集(不能超过已有集合元素数)
负数:取出一个带重复结果集,一定满足数量
)
srandmember key [±count1 ±count2......... ]
#随机取出后删除原有集合中数据
spop key [num]
4、应用场景
- 共同好友、可能认识的人
- 利用唯一性,统计访问网站的所有独立ip
- 好友推荐时,根据tag求交集,大于某个阈值就可以推荐
- 热点新闻:对于热点的过多点赞或者评论会导致并发问题。如果将这些点赞和评论利用缓存来解决,然后不定时地把缓存数据刷到数据库中,那么将能提高性能
- 章点赞或者投票
- 不重复抽奖:清理所有数据 flushdb
//一次性存储多个用户信息
sadd luckuser userl user2 user3 user3 user4 user5
//随机抽取一个人,抽完从集合中删除获奖用户的信息,不能重抽
spop luckuser 1
//随机抽取两个人,抽完之后不能重抽
spop luckuser 2
//验证抽完之后获奖用户的信息是否被删除 smembers luckuser - 重复再抽奖品
/首先存入所有参与抽奖的用户信息
sadd luckuser userl
//当存入重复的用户信息时,存入操作会失败并返回结果0
sadd luckuser userl
//一次性存储多个用户信息
sadd luckuser userl user2 user3 user3 user4 user5
//查看所有参与抽奖人的信息,不会有重复的 smembers luckuser
//随机抽取一个人,抽完不删除信息可以再次抽奖
srandmember luckuser
//随机抽取三个人,抽完不删除信息可以再次抽奖
srandmember luckuser 3
//验证抽完之后人员信息是否被删除
smembers luckuser
八、sorted_set
Redis有序列表类似于Java的SortedSet和HashMap的结合体,
一方面是一个set,保证内部value的唯一性,另一方面可以给每个value赋予一个score,代表这个value的排序权重。
1、数据结构(skiplist跳跃表)
它的内部实现是一个Hash字典 + 一个跳表
存储数据时按排序好的顺序粗如物理内存,物理内存左小右大不随命令而变化
2、特性
可排序
元素不重复
查询速度快
3、常用命令
zadd [key] [score1] member1 [score2] member2
#取出member(从小到大)
zrange key indexstart indexend
按照从大到小的顺序取出member,取出前2个
zrevrange key 0 1
#取出score 和 member
zrange key startIndex endIndex withscore
#按score取出member
zrangebyscore key scoreMinValue scoreMaxValue
#根据元素member取出分值score
zscore key member
据元素取出排名即index
zrank key member根
#将member的分值加2.5
zincrby key [score] member
zincrby key 2.5 member
#并集(权重&聚合)
zunionstore reskey [keysNum] [key1 .... keyn] [weights weigth1...weightn] [aggregate sum min max]
zunionstore reskey 3 key1 key2 key3 #不指定权重默认都是1,不指定聚合默认是sum
zunionstore reskey 3 key1 key2 key3 weights 1 2 1 #不指定聚合默认是sum
zunionstore reskey 3 key1 key2 key3 aggregate max #不指定权重默认都是1
4、应用场景
- 排行榜,取TopN操作
- 带权重的消息队列
- 限流
- 新闻排行榜
- 直播打赏排行榜
九、管道
1、常用命令
2、应用场景:
批量操作数据:批量从文件插入数据到redis
十、发布订阅
1、常用命令
publish channelName value
subcribe channelName
2、应用场景
- 实时数据
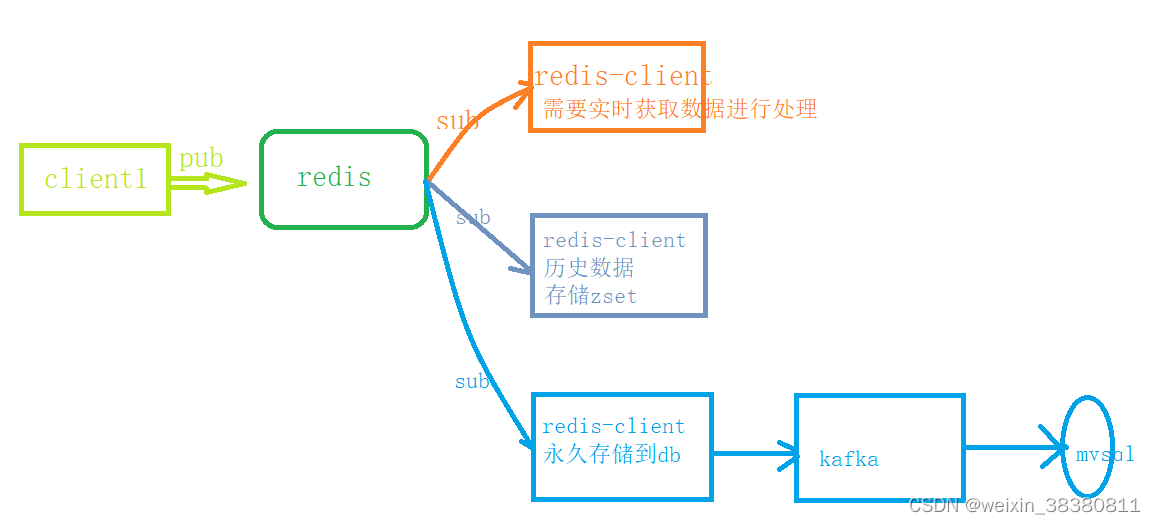
十一、事务
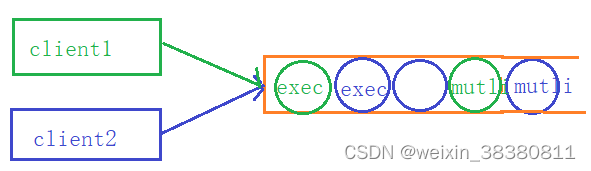
1、特性
- 并不像MySQL的事务,没有所谓的回滚
- 多个客户端同一时间段开启事务,哪个线程先提交那么哪个事务先生效
- 其他客户端的操作无法执行的命令失败,余下的命令依然执行
- 使用watch命令时整体的命令才是原子性的
- 不同线程的命令执行前都会有各自的内存缓冲区存储
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









