







一、概述
1.0 研究背景
最近在研究网站仿真,供给公司内产品使用,但是现有程序(基于aiohttp的项目)无法获取php的网页,导致爬取的页面如下:

当然,预期是正常的什么页面,这里就不列了,可以想象电子商城,所以特此研究些新东西。
之前研究发现,浏览器访问另存为是可以保留html的,不会出现背景中的图示错误,虽然会丢失js、css、不过其他爬取也会丢失,样式、js等可以额外爬取。
这里就想使用python模拟另存为这个功能。考虑到是浏览器模型功能,所以搜了些博客,想基于下面参考文献去突破这个想法落地。
1.1 参考文献
1.0.1 debian 11上安装 Google Chrome
1.0.2 Selenium安装
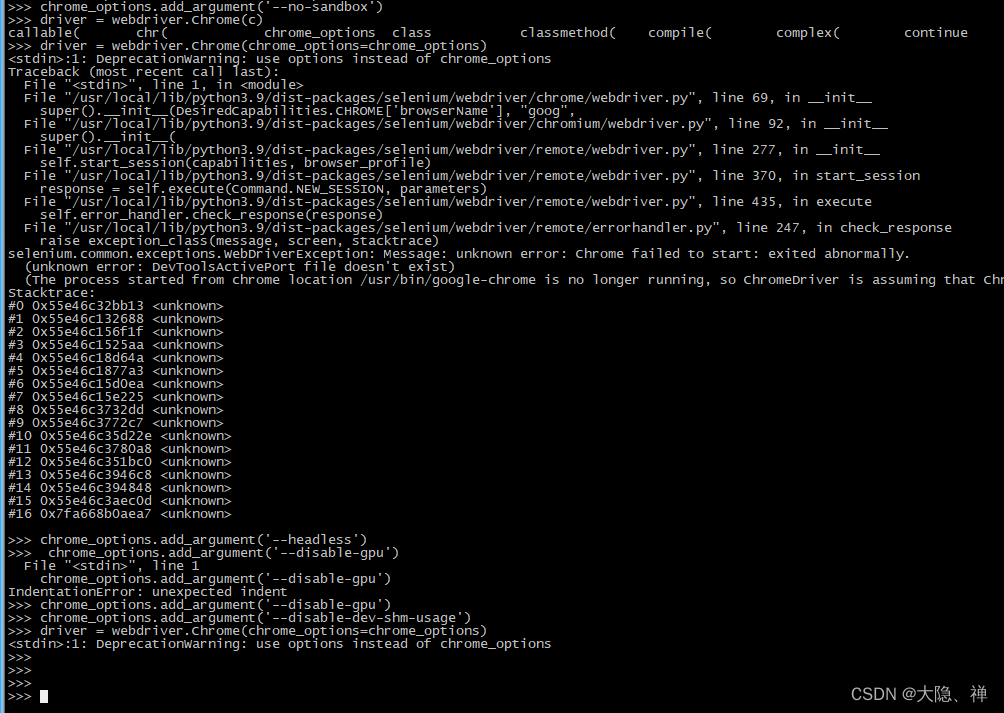
1.0.3 selenium.common.exceptions.WebDriverException处理
1.0.4 保存mhtml
1.2 文献综述
根据文献,可以解决一些问题,进入到

二、详情
2.1 解决无法爬取的链接
www.lxnews.cn 拿这个网站举例,它的页面logo是无法在html源码中查询到的,如这个链接。
http://www.lxnews.cn/images/zy_logo.png
但是在mhtml中
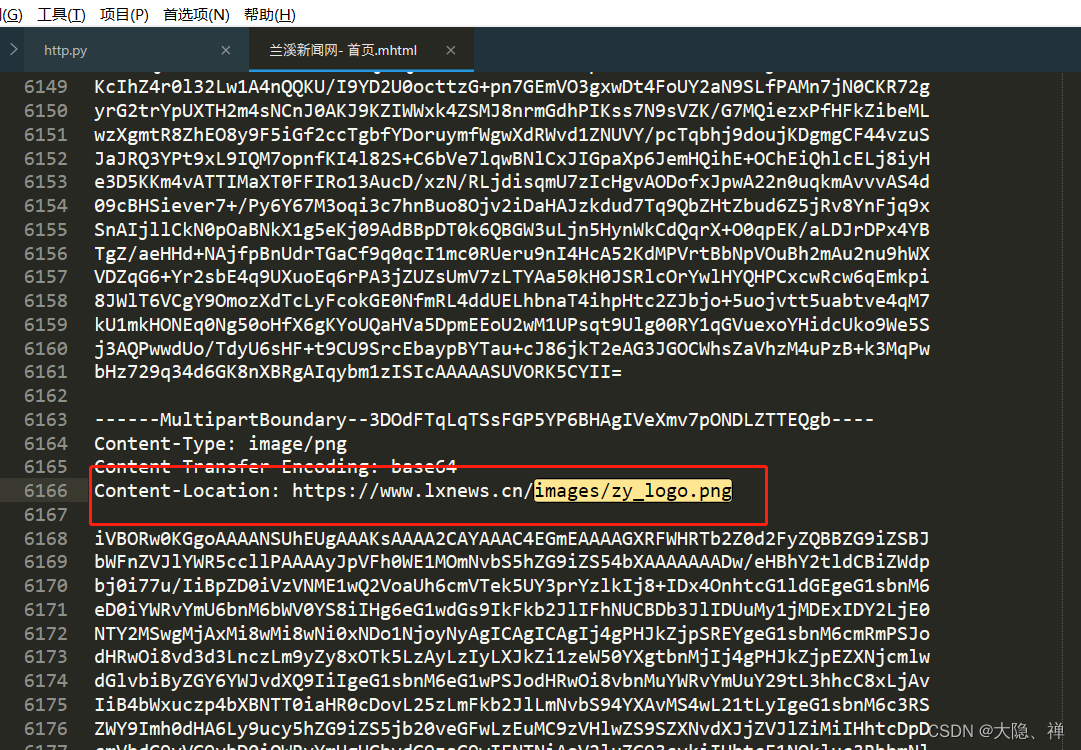
这个链接完美的在这个Content-Location 中
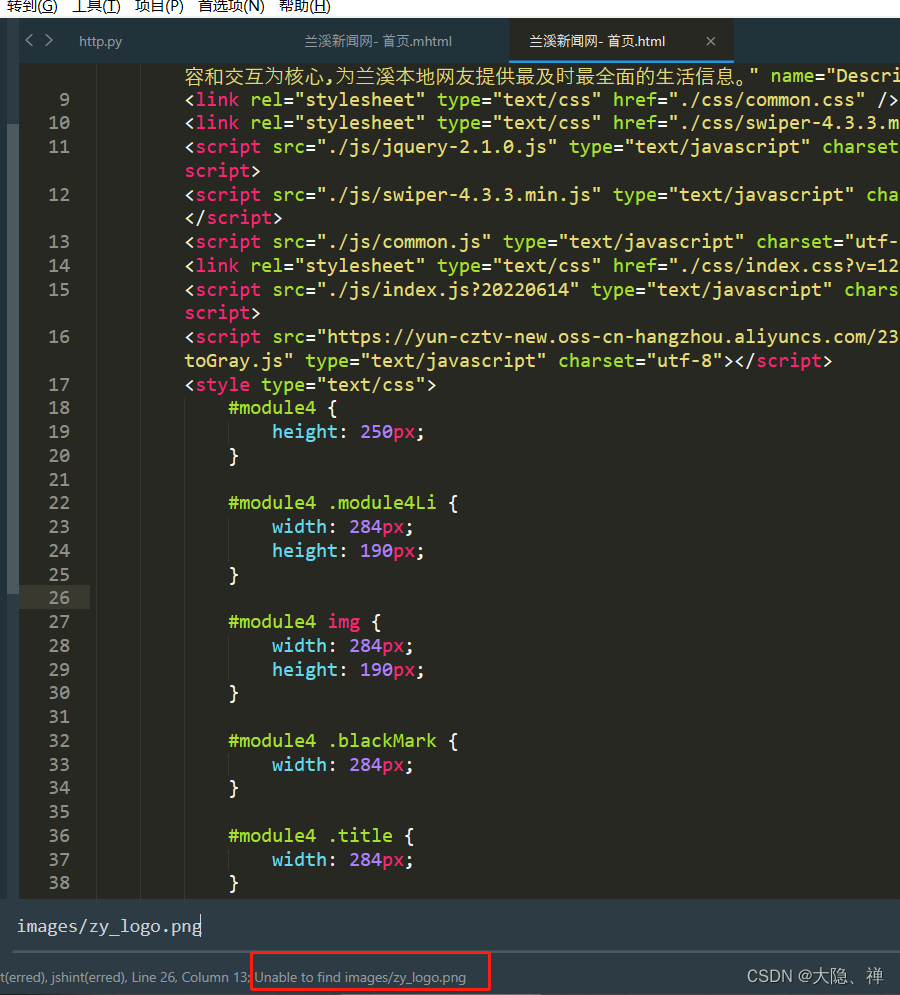
对比源码page_source在下图看,明显没有mhtml中的logo链接。
2.2 爬取mhtml

这样mhtml 就这样保存下来了。
当然,如果只需要其中的链接,这个文件可以不必保存。只需要把resp(是dict字典类型)中的data中的需要数据过滤出来即可。















 2482
2482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









