






ES安装
中文
https://www.elastic.co/guide/cn/elasticsearch/guide/current/running-elasticsearch.html
英文(推荐)
https://www.elastic.co/guide/en/elasticsearch/reference/8.3/install-elasticsearch.html
安装时,根据操作系统选择安装程序
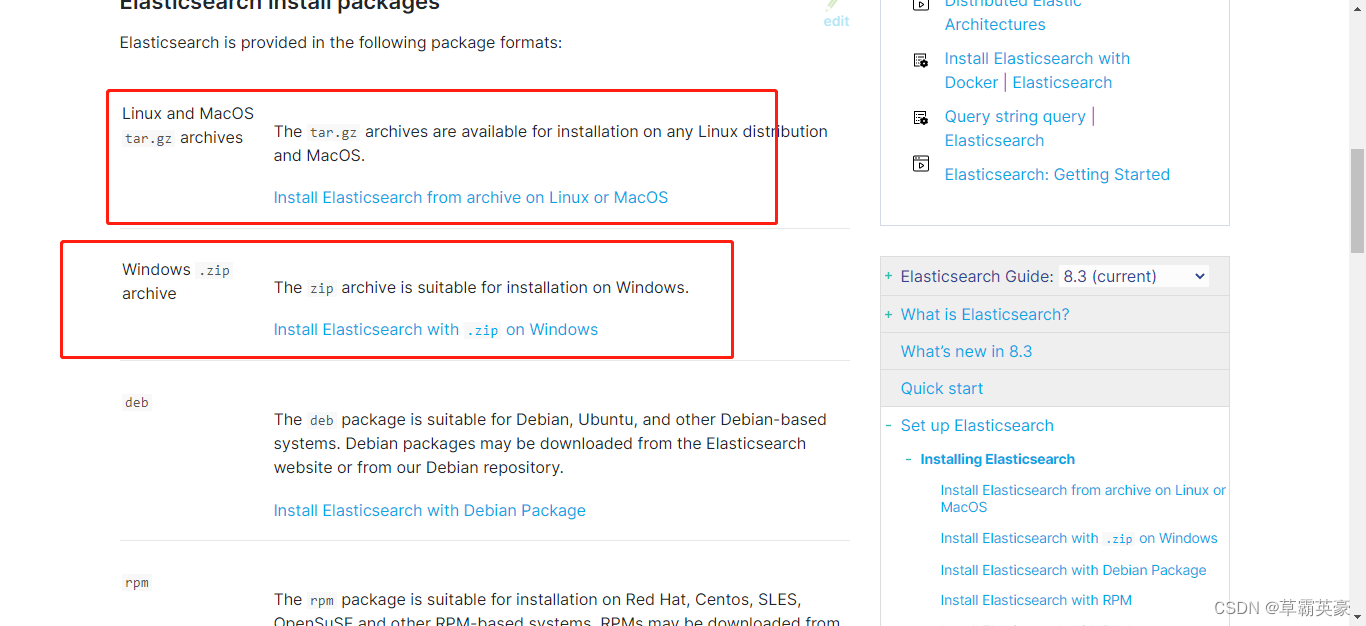
安装后启动的问题解决
https://blog.csdn.net/CalledJoker/article/details/122972170
KIBANA安装
https://www.elastic.co/guide/en/kibana/4.6/setup.html
集群健康
GET /_cluster/health
使用green、yellow、red表示集群状态
kibana搜索
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_search_lite.html
存放简单数据
POST logs-my_app-default/_doc
{
"@timestamp": "2099-05-06T16:21:15.000Z",
"event": {
"original": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"
}
}
批量存储数据
PUT logs-my_app-default/_bulk
{ "create": { } }
{ "@timestamp": "2099-05-07T16:24:32.000Z", "event": { "original": "192.0.2.242 - - [07/May/2020:16:24:32 -0500] \"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0" } }
{ "create": { } }
{ "@timestamp": "2099-05-08T16:25:42.000Z", "event": { "original": "192.0.2.255 - - [08/May/2099:16:25:42 +0000] \"GET /favicon.ico HTTP/1.0\" 200 3638" } }
搜索全量数据
GET logs-my_app-default/_search
{
"query": {
"match_all": { }
},
"sort": [
{
"@timestamp": "desc"
}
]
}
获取指定字段数据
GET logs-my_app-default/_search
{
"query": {
"match_all": { }
},
"fields": [
"@timestamp"
],
"_source": false,
"sort": [
{
"@timestamp": "desc"
}
]
}
查询区间数据
GET logs-my_app-default/_search
{
"query": {
"range": {
"@timestamp": {
"gte": "2099-05-05",
"lt": "2099-05-08"
}
}
},
"fields": [
"@timestamp"
],
"_source": false,
"sort": [
{
"@timestamp": "desc"
}
]
}
查询离现在多久时间段数据
GET logs-my_app-default/_search
{
"query": {
"range": {
"@timestamp": {
"gte": "now-1d/d",
"lt": "now/d"
}
}
},
"fields": [
"@timestamp"
],
"_source": false,
"sort": [
{
"@timestamp": "desc"
}
]
}
从内容中获取部分信息返回
GET logs-my_app-default/_search
{
"runtime_mappings": {
"source.ip": {
"type": "ip",
"script": """
String sourceip=grok('%{IPORHOST:sourceip} .*').extract(doc[ "event.original" ].value)?.sourceip;
if (sourceip != null) emit(sourceip);
"""
}
},
"query": {
"range": {
"@timestamp": {
"gte": "2099-05-05",
"lt": "2099-05-08"
}
}
},
"fields": [
"@timestamp",
"source.ip"
],
"_source": false,
"sort": [
{
"@timestamp": "desc"
}
]
}
合并查询
GET logs-my_app-default/_search
{
"runtime_mappings": {
"source.ip": {
"type": "ip",
"script": """
String sourceip=grok('%{IPORHOST:sourceip} .*').extract(doc[ "event.original" ].value)?.sourceip;
if (sourceip != null) emit(sourceip);
"""
}
},
"query": {
"bool": {
"filter": [
{
"range": {
"@timestamp": {
"gte": "2099-05-05",
"lt": "2099-05-08"
}
}
},
{
"range": {
"source.ip": {
"gte": "192.0.2.0",
"lte": "192.0.2.240"
}
}
}
]
}
},
"fields": [
"@timestamp",
"source.ip"
],
"_source": false,
"sort": [
{
"@timestamp": "desc"
}
]
}
聚合查询
GET logs-my_app-default/_search
{
"runtime_mappings": {
"http.response.body.bytes": {
"type": "long",
"script": """
String bytes=grok('%{COMMONAPACHELOG}').extract(doc[ "event.original" ].value)?.bytes;
if (bytes != null) emit(Integer.parseInt(bytes));
"""
}
},
"aggs": {
"average_response_size":{
"avg": {
"field": "http.response.body.bytes"
}
}
},
"query": {
"bool": {
"filter": [
{
"range": {
"@timestamp": {
"gte": "2099-05-05",
"lt": "2099-05-08"
}
}
}
]
}
},
"fields": [
"@timestamp",
"http.response.body.bytes"
],
"_source": false,
"sort": [
{
"@timestamp": "desc"
}
]
}
查询数据总量
GET /_cat/shards?v
查询出所有的索引及索引占据的大小
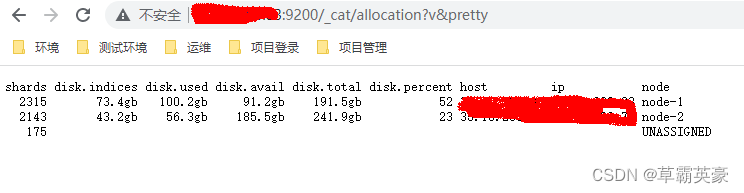
_cat/allocation?v&pretty
可以获取到总量数据
es数据类型(mapping)
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
可以参考文档,分为binaray,text,keyword,ip,date等等,用于定义文档结构,存入数据时,数据内容与文档结构相对应。
查询内容:视频参考
term查询
关键字不会进行分词,相当于是where province = ‘北京’
POST /f5-request/_search
{
"query":{
"term":{
"province":{
"value":"北京"
}
}
}
}
terms查询
关键字不会进行分词,相当于是where province in (‘北京’,‘上海’)
POST /f5-request/_search
{
"query":{
"terms":{
"province":[
"北京",
"上海"
]
}
}
}
match查询
高层查询,将多个term查询进行封装后返回。
如果查询的是日期或者数值,会将基于字符串的查询转为日期或数值
如果查询keyword,则跟term查询一致
如果查询的是text,则会进行分词
match_all查询
会查询出所有数据
POST /f5-request/_search
{
"query":{
"match_all":{}
}
}
match查询
根据字段进行查询,字段中的内容首选会被分词器进行分词,然后找到文档中,smsContent包含分词器分好的哪些词
POST /f5-request/_search
{
"query":{
"match":{
"smsContent":"我爱北京天安门"
}
}
}
Boolean match查询
根据字段进行查询,字段中的内容首选会被分词器进行分词,然后找到文档中,smsContent包含分词器分好的哪些词,然后根据操作符进行匹配,and(表示多个都有才算是匹配),or(表示有任意一个即算是匹配)
POST /f5-request/_search
{
"query":{
"match":{
"smsContent":{
"query":"快递 菜鸟",
"operator":"and"
}
}
}
}
Multi match查询
给一个value,在多个field中进行匹配。在province和smscontent中找【北京】
POST /f5-request/_search
{
"query":{
"multi_match":{
"query":"北京",
"fields":["province","smsContent"]
}
}
}
id查询
根据id查询文档
id查询
根据单个id查询,查询id为1的数据
GET /f5-requext/1
ids查询
查询多个id的数据
POST /f5-request/_search
{
"query":{
"ids": {
"values": ["1","2","3"]
}
}
}
prefix查询
前置查询,可以查询keyword类型前面的内容,在这个查询中,corpName类型为keyword,全名为上东科技,下面prefix查询,可以查询到数据,如果使用match查询,则查询不到数据
POST /f5-request/_search
{
"query":{
"prefix": {
"corpName": {
"value":"上东"
}
}
}
}
fuzzy查询
模糊查询,允许出现错别字查询,keyword为盒马鲜生,则fuzzy查询中,使用河马鲜生可以查询到数据。也可以使用prefix_length来确定,前面几个字符不能有错。
POST /f5-request/_search
{
"query":{
"fuzzy": {
"corpName": {
"value":"盒马鲜生",
"prefix_length":3
}
}
}
}
wildcard查询
通配符查询,可以使用和?来进行占位。如果使用星号,则表示任意字符长度,比如【中国】,可以查询到中国移动,中国联通等,如果使用【中国?】,则只能查询到中国人这种三个字符的
POST /f5-request/_search
{
"query":{
"wildcard": {
"corpName": {
"value":"中国*"
}
}
}
}
range查询
范围查询,可以筛选某个field的范围。gte、lte、gt,lt,大于等于,小于等于,大于,小于
POST /f5-request/_search
{
"query":{
"range": {
"fee": {
"gt":"5",
"lte":"10"
}
}
}
}
regexp查询
正则查询,匹配正则表达式,比如要查手机号码是180开头的,就可以使用正则180[0-9]{8}
POST /f5-request/_search
{
"query":{
"regexp": {
"mobile": "180[0-9]{8}"
}
}
}
scroll深分页
分页可以使用from和size实现,但是这种实现有个问题就是每次都是查询全部数据,如果数据量大,则会非常消耗资源和时间。此时就出现了深分页,深分页查询时,首次查询后,会将查询内容存放在内存中,后续查询可以直接从内存中读取数据,这种相对于数据量较大的分页查询,速度会快很多。但是也有一个缺点,就是不能实时查询,查询到的数据会有滞后。
首次查询
查询时可以制定每次查询多少条数据,也可以指定排序,按照那个,或者哪些字段进行排序
# 在最后添加scroll=1m表示scroll查询到的数据在内存中存放1分钟
POST /f5-request/_search?scroll=1m
{
"query":{
"match_all": {}
},
"size":2,
"sort":[
{
"fee":{
"order":"desc"
}
}
]
}
首次查询后,会返回一个scrollId
再次查询
再次查询时,同样要制定scroll的存活时间,
POST /_search/scroll
{
"scroll_id":"skdjf93j2lj34928ulskdjfosijeflsdkjfoeijwo***",
"scroll":"1m"
}
删除scroll
最后带上要删除的scrollid
DELETE /_search/scroll/skdjfoiewlfkejwifeowifejijlskdjfsj***
delete-by-query删除查询到的内容
用于删除查询到的文档,要删除的文档数据量大的时候,不推荐使用,因为后台还是一条条删除,比较耗时。下面例子中,是删除fee小于4的所有文档
POST /f5-request/_delete_by_query
{
"query":{
"range":{
"fee":{
"lt":"4"
}
}
}
}
复合查询
复合的bool查询,相当于是多条件查询,在条件中可以使用must(and),must_not(not),shoud(or)三种。里面再嵌套term、match等查询方式
比如要查询运营商不是联通,内容中包含中国和平安,省份是北京或武汉
POST /f5-request/_search
{
"query"{
"bool":{
"shoud":[
{
"term":{
"province":{
"value":"北京"
}
}
},
{
"term":{
"province":{
"value":"武汉"
}
}
}
],
"must_not":[
{
"term":{
"operatorId":"2"
}
}
],
"must":[
{
"term":{
"smsContent":"中国"
}
},
{
"term":{
"smsContent":"平安"
}
}
]
}
}
}
boosting查询
相对于普通查询,如果查询出来的数据中,有需要将某部分数据的分值降低,则可以使用boosting查询。比如一个普通查询,查出来10条数据,分数最高的是A记录,但是A记录中有某个特征(比如说里面含有奥特曼三个字),则可以使用negative匹配,匹配后再使用negative_boost作为系数(小于1),原有的分值是1.5份,给了一个系数0.2,则计算后的分数就变成了0.3。分值变小了,就往后面排了。
POST /f5-request/_search
{
"query":{
"boosting":{
"positive":{
"match":{
"smsContent":"收获安装"
}
},
"negative""{
"match":{
"smsContent":"王爷"
}
},
"negative_boost":0.2
}
}
}
filter查询
相对于match查询,filter查询不做分数计算,同样也没有排序,只有符合条件的结果被筛选出来
POST /f5-request/_search
{
"query":{
"bool":{
"filter":[
{
"term":{
"corpName":"盒马鲜生"
}
},
{
"range":{
"fee":{
"lte":4
}
}
}
]
}
}
}
高亮查询
将查询到的内容进行高亮显示,有三个属性,一个是pre_tags(迁至标签),post_tags(后置标签),fragment_size(展示多少个字符)。查询得到的结果中,之前的source不会改变,会多出来一个highlight文档,这里面的文档直接放到html中即可进行高亮展示。
POST /f5-request/_search
{
"query":{
"match":{
"smsContent":"盒马"
}
},
"highlight":{
"fields":{
"smsContent":{}
},
"pre_tags":"<font color='red'>",
"post_tags":"</font>",
"fragment_size":10
}
}
聚合查询
将数据进行聚合展示
去重计数查询
使用cardinality进行查询。下面例子中,aggs是固定写法,agg是聚合的名称,这个名称在查询得到的结果中使用。根据省份进行去重计数,得到总共有多少个不同的省份数据。
POST /f5-request/_search
{
"aggs":{
"agg":{
"cardinality":{
"field":"province"
}
}
}
}
范围统计
使用range,date_range,ip_range进行范围查询。from包含,to不包含。下面统计费用小于5的有多少,大于等于5,小于10的有多少,大于等于10的有多少
POST /f5-request/_search
{
"aggs":{
"agg":{
"range":{
"field":"fee",
"ranges":[
{
"to":5
},
{
"from":5,
"to":10
},
{
"from":10
}
]
}
}
}
}
查询2010年前有多少数据,2010年后有多少数据
POST /f5-request/_search
{
"aggs":{
"agg":{
"date_range":{
"field":"createTime",
"format":"yyyy",
"ranges":[
{
"to":2010
},
{
"from":2010
}
]
}
}
}
}
聚合统计查询
查询某个字段的最大值,最小值,平均值,平方和等内容
POST /f5-request/_search
{
"aggs":{
"agg":{
"extended_stats":{
"field":"fee"
}
}
}
}
其他聚合
聚合查询有非常多中,可以参考官网
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-iprange-aggregation.html
地图经纬度搜索
es中有geo_point类型,用于存储位置信息。且es提供了3中搜索方式来检索数据
- geo_distance:直线距离检测,以当前点为圆心画圆
- geo_bounding_box:以两个点画一个矩形,找到矩形框内的所有数据
- geo_polygon:多个点(至少3个)画一个多边形,找到多边形中所有的数据
POST /f5-request/_search
{
"query":{
"geo_distance":{
"location":{
"lon":116.988729,
"lat":39.2283495
},
"distance":3000,
"distance_type":"arc" #圆形
}
}
}
文档在网盘,参考:链接: https://pan.baidu.com/s/1y_kz7r3Ubn4ImhATfjSz2A 提取码: 6666














 1296
1296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









