







一、IO
1.1、IO模型
我们常说的IO,指的是文件的输入和输出 ,但是在操作系统层面是如何定义IO的呢?到底什么样的过程可以叫做是一次IO呢?
拿一次磁盘文件读取为例,我们要读取的文件是存储在磁盘上的,我们的目的是把它读取到内存中。可以把这个步骤简化成把数据从硬件(硬盘)中读取到用户空间中。
举例:一次完整的钓鱼(IO)操作,是鱼(文件)从鱼塘(硬盘)中转移(拷贝)到鱼篓(用户空间)的过程。
以 Linux 为例,它有五种 IO 模型:
阻塞IO模型、非阻塞IO模型、IO复用模型、信号驱动IO模型以及异步IO模型
在Java中,主要有三种IO模型,分别是阻塞IO(BIO)、非阻塞IO(NIO)和 异步IO(AIO)
比如在Linux 2.6以后,Java中NIO和AIO都是通过epoll来实现的,而在Windows上,AIO是通过IOCP来实现的。
可以把Java中的BIO、NIO和AIO理解为是Java语言对操作系统的各种IO模型的封装。程序员在使用这些API的时候,不需要关心操作系统层面的知识,也不需要根据不同操作系统编写不同的代码。只需要使用Java的API就可以了。
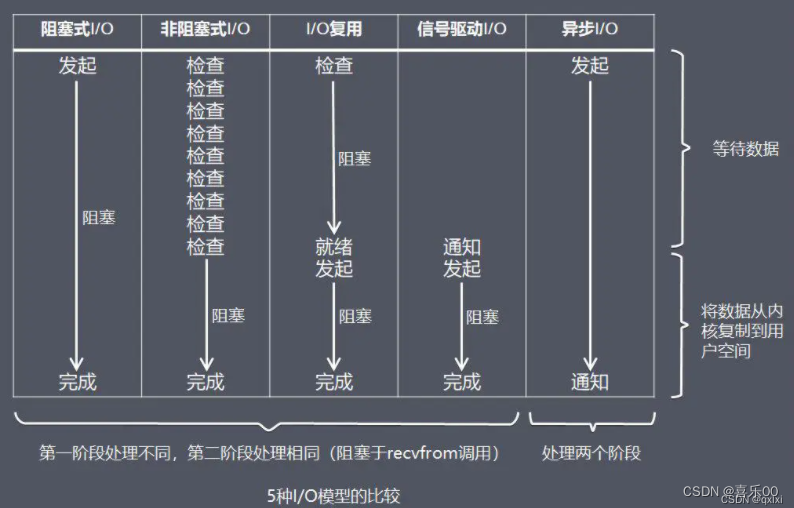
1.2 阻塞IO模型(Blocking IO)
这是最基础的IO模型,当进行IO操作时,线程会被阻塞,直到操作完成。
首先,要从你常用的IO操作谈起,比如read和write,通常IO操作都是阻塞I/O的,也就是说当你调用read时,如果没有数据收到,那么线程或者进程就会被挂起,直到收到数据。无法处理并发。
阻塞 I/O 是最简单的 I/O 模型,一般表现为进程或线程等待某个条件,如果条件不满足,则一直等下去。条件满足,则进行下一步操作。
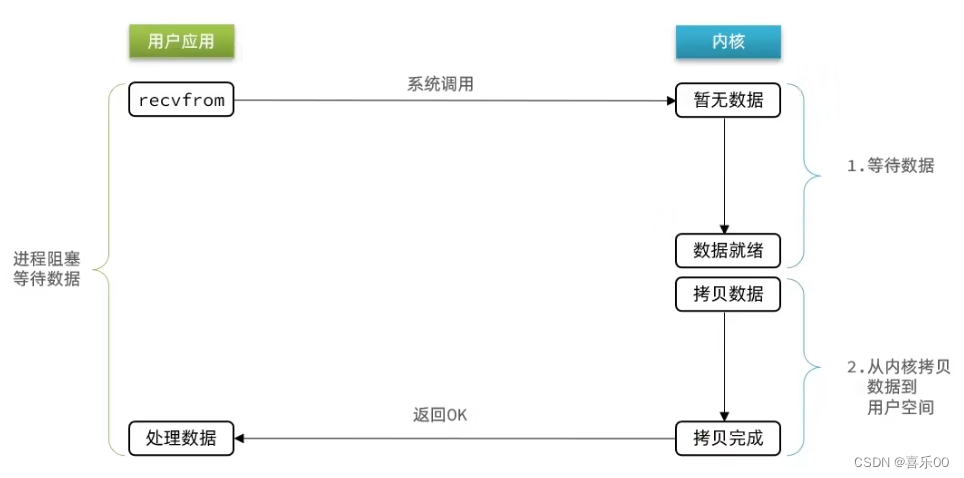
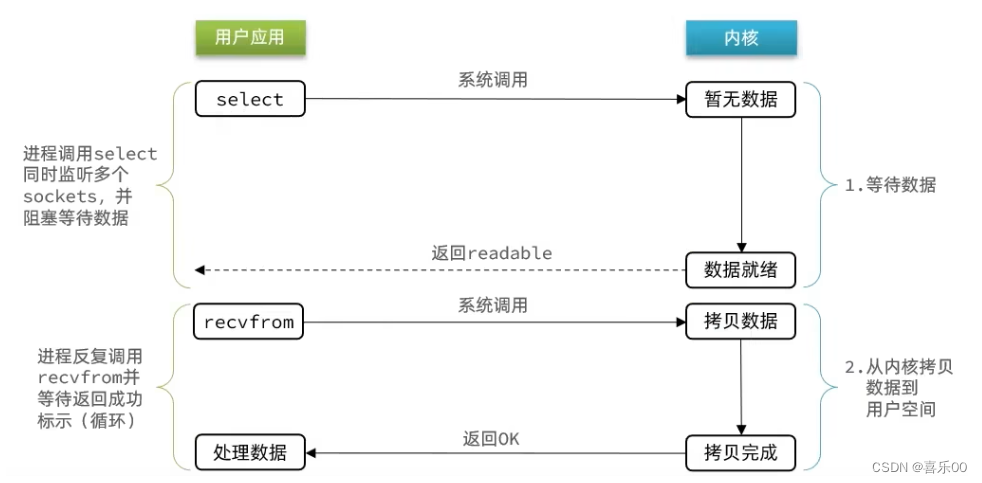
1.3非阻塞IO模型(Non-blocking IO)
在这种模型中,线程可以在不阻塞的情况下对文件描述符进行读写操作。
当你调用read时,如果有数据收到,就返回数据,如果没有数据收到,就立刻返回一个错误,这样是不会阻塞线程了。此时用户进程需要不断轮询,如果轮询频繁,则浪费了大量的CPU资源;如果轮询频率低,则不能实时地获取数据。过度浪费CPU资源。
不断轮询
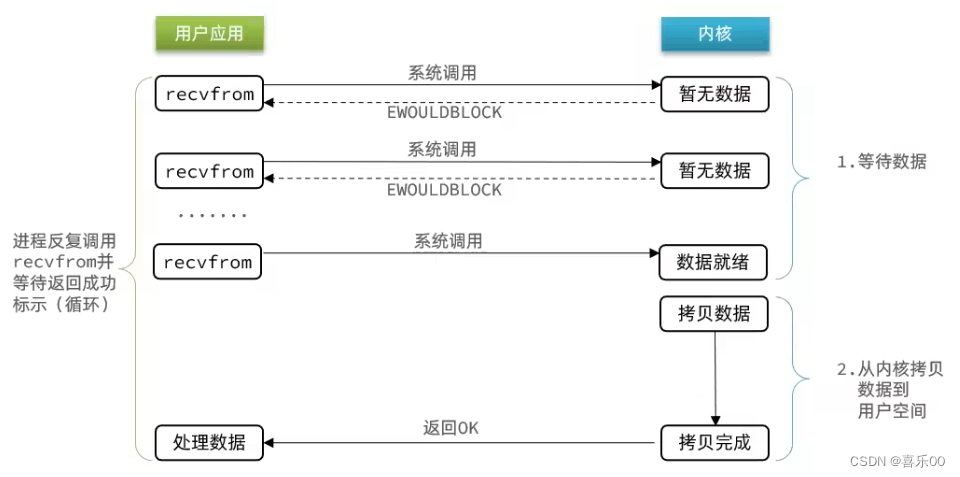
1.3信号驱动IO模型(Signal-driven IO)
这种模型使用信号来通知应用程序某个文件描述符的状态已经改变。
应用进程在读取文件时通知内核,如果某个 socket 的某个事件发生时,请向我发一个信号。在收到信号后,信号对应的处理函数会进行后续处理。
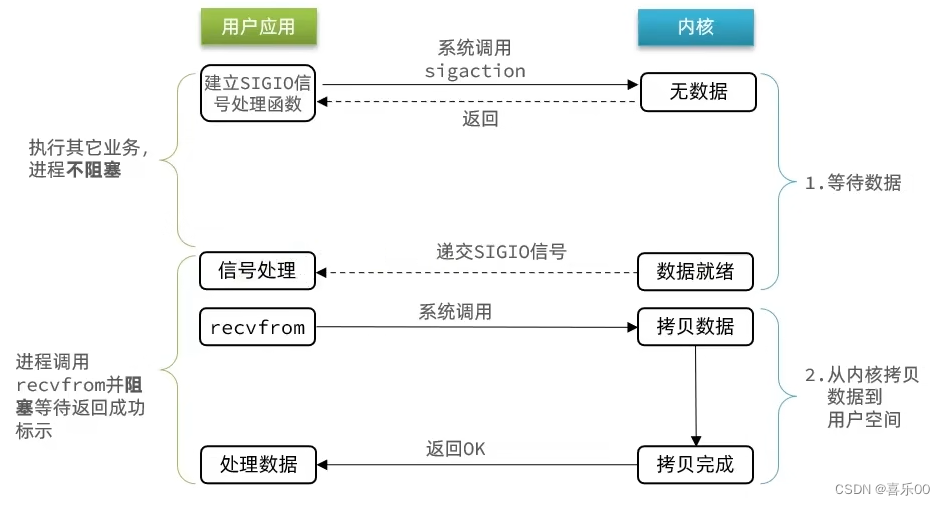
1.4异步IO模型(Asynchronous IO)
在这种模型中,应用程序发起IO操作后,可以继续执行其他任务,当IO操作完成时,会以某种方式通知应用程序。
当调用read时,不需要等到数据返回就可以继续去干别的事情,调用write的时候同理。但是频繁的切换线程会出现浪费过多CPU资源的问题。
应用进程把IO请求传给内核后,完全由内核去操作文件拷贝。内核完成相关操作后,会发信号告诉应用进程本次IO已经完成。
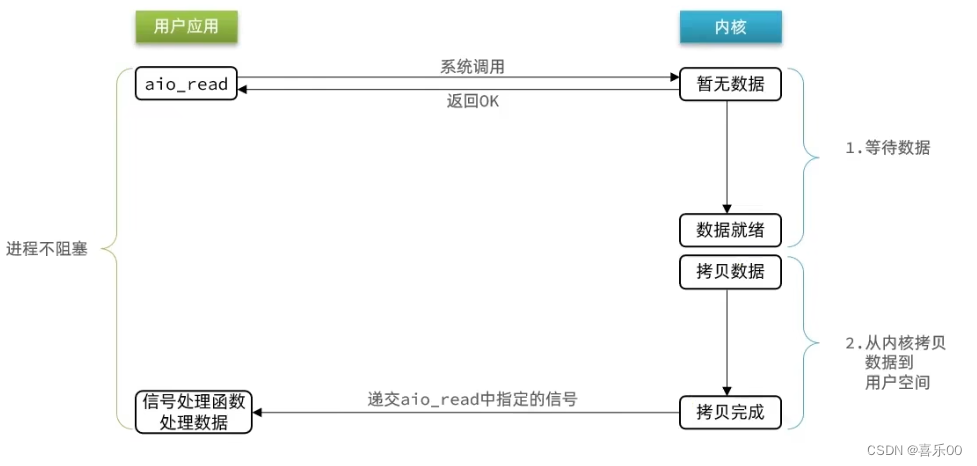
1.5 IO多路复用
多个进程的IO可以注册到同一个管道上,这个管道会统一和内核进行交互。当管道中的某一个请求需要的数据准备好之后,进程再把对应的数据拷贝到用户空间中。
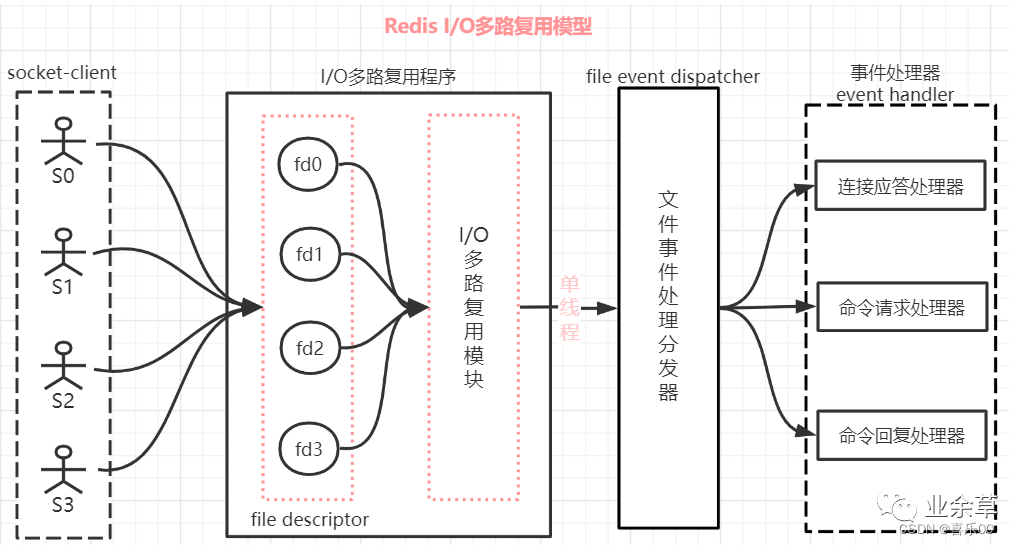
二、Redis IO多路复用模型
在面试中通常会有这样子的场景
↓↓↓↓↓↓
面试官:看你的简历写到项目中有用到redis,可以聊聊redis吗
求职者:可以哇。我在项目中主要使用了redis做商品信息的缓存,我会先从缓存中拿商品信息,如果缓存失效了再去数据库拿商品信息,最后更新缓存,这样子做直接提高了程序的性能并减少了DB的压力。
求职者:redis很快,主要是因为完全基于内存,而且是单线程,使用了I/O多路复用模型。
面试官:那你了解I/O多路复用技术在redis中的应用吗
求职者:不是很了解。。。
这里"多路"指的是多个网络连接,"复用"指的是复用同一个线程。
多路复用I/O模型是一种同步I/O模型。实现一个线程监听多个文件句柄(也叫做文件描述符,FileDescription,简称FD),当有一个FD就绪时,则通知对应的应用程序进行读写操作。当没有FD就绪时,就会阻塞并交出CPU。
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗)。
redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
redis是以socket方式通信,socket服务端可同时接受多个客户端请求连接,也就是说,redis服务同时面对多个redis客户端连接请求,而redis服务本身是单线程运行。
I/O 多路复用其实是使用一个线程来检查多个 Socket 的就绪状态,在单个线程中通过记录跟踪每一个 socket(I/O流)的状态来管理处理多个 I/O 流。
客户端与服务端建立连接交由socket,可以同时建立多个连接(这里应该是多线程/多进程), 从探测到数据处理再到数据返回,全程单线程。这应该就是所谓的redis单线程。
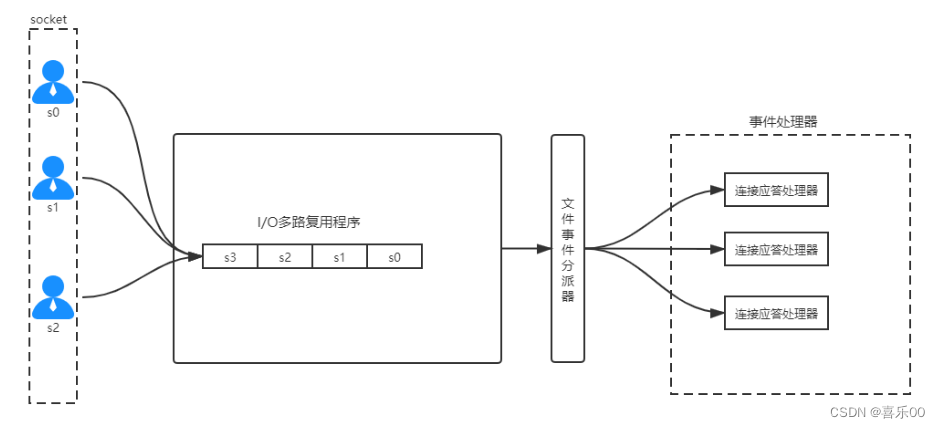
三、Redis为什么要引入多路复用I/O技术
I/O多路复用的本质是同步阻塞I/O模型,但是,它最大的优势在于可以在一次阻塞中监听多个文件描述符(FD)。我们带入redis的场景,来思考一下redis为什么使用多路复用I/O技术。
- 首先采用普通的同步阻塞I/O,那么Redis可能会在一个客户端上长期阻塞。该客户端可能长期没有数据到达,而Redis需要处理多个客户端的通信,当其他客户端有请求到达时,Redis则无法处理了,这显然是无法接受的。
- 如果使用同步非阻塞I/O,那么就需要不断轮循客户端,那么这种频繁的轮循会很浪费CPU资源,如果轮循不频繁,那么可能就会出现数据不能实时获取的问题。
- 如果使用 异步IO模型,线程的创建和频繁的上下文切换会浪费更多的资源。其次Redis本身就是单进程单线程的模式工作,多线程等待多个客户端显然与其系统思想不符。
- 综上,多路复用I/O技术是首选。
“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗)。可以直接理解为:单线程的原子操作,避免上下文切换的时间和性能消耗**;加上对内存中数据的处理速度,很自然的提高redis的吞吐量
四、总结
1. Redis使用的是同步阻塞I/O模型,I/O多路复用,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下文的切换和竞争。
2. Redis采用了单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
3. Redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大。
参考:
https://mp.weixin.qq.com/s/XzLHy41JrCV_y3BZpeTgwQ
https://blog.csdn.net/weixin_63566550/article/details/129121834














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









