







引言
随着应用程序变得越来越复杂,有效地管理缓存成为了提高性能和用户体验的关键。缓存不仅可以减少数据库的负载,还能显著提高数据访问速度。但是,选择合适的缓存模式可能是一个挑战,因为每种模式都有其独特的优势和适用场景
本文旨在深入探讨八种主要的缓存模式,帮助开发者理解每种策略的工作原理、优缺点以及最佳应用场景。从经典的Cache-Aside(旁路缓存)到复杂的Write-Through-Back(透写后缓存),将一一剖析这些策略模式如何在不同的业务需求和技术挑战中发挥作用
目录
- Cache-Aside (旁路缓存)
- Read-Through (透读缓存)
- Write-Through (透写缓存)
- Write-Back / Write-Behind (写后缓存)
- Write-Through-Back (透写后缓存)
- Refresh-Ahead (预刷新缓存)
- Lazy-Loading (懒加载)
- Write-Around (绕写缓存)
一、Cache-Aside Pattern (旁路缓存)
概述
Cache-Aside Pattern,也称为Lazy-Loading Pattern,是由应用程序负责直接从缓存中读取和写入数据。如果缓存未命中,应用程序将从数据库加载数据,并将其存储在缓存中以供未来使用
工作流程

- 读取数据:
- 应用程序首先查询缓存
- 如果缓存命中,直接返回数据
- 如果缓存未命中,应用程序从数据库查询数据,然后将数据存储在缓存中,并返回给用户
- 更新数据:
- 应用程序直接更新数据库
- 接着,应用程序移除或更新缓存中的相应数据
示例代码
public class CacheAsideExample {
private Cache cache;
private Database database;
public Data getData(String key) {
Data data = cache.get(key);
// 缓存未命中
if (Objects.isNull(data) {
// 从数据库获取
data = database.getData(key);
// 存储到缓存
cache.put(key, data);
}
return data;
}
public void updateData(String key, Data newData) {
// 更新数据库
database.updateData(key, newData);
// 更新或删除缓存中的旧数据
cache.updateOrDelete(key);
}
}
优缺点
- 优点:
- 自动化数据加载:减少了应用程序需要编写的缓存逻辑
- 减少数据库访问:提高了数据访问的效率
- 数据保鲜:确保缓存中的数据是最新的
- 缺点:
- 实现复杂性:需要缓存层能够处理数据源的加载逻辑
- 可能的延迟:对于缓存未命中的情况,需要一定的时间开销再从数据源加载数据
- 缓存与数据源的依赖性:缓存层需要知道如何从数据源加载数据
应用场景
- 适用于读操作比写操作频繁的场景:因为写入操作不会立即更新缓存,所以更适合读多写少的应用
- 数据更新不频繁的场景:如果数据经常变化,缓存未命中的情况会更频繁,可能存在性能问题
- 对数据一致性要求不是非常严格的应用:由于缓存更新可能会有延迟,所以对于需要高度一致性的应用,这种模式可能不是最佳选择
二、Read-Through Pattern (透读缓存)
概述
Read-Through Pattern是由缓存层负责从数据源(如数据库)加载数据。当应用程序请求数据时,如果缓存中存在该数据,则直接返回;如果不存在,则缓存层负责从数据源加载数据,存入缓存,并返回给应用程序。
工作流程
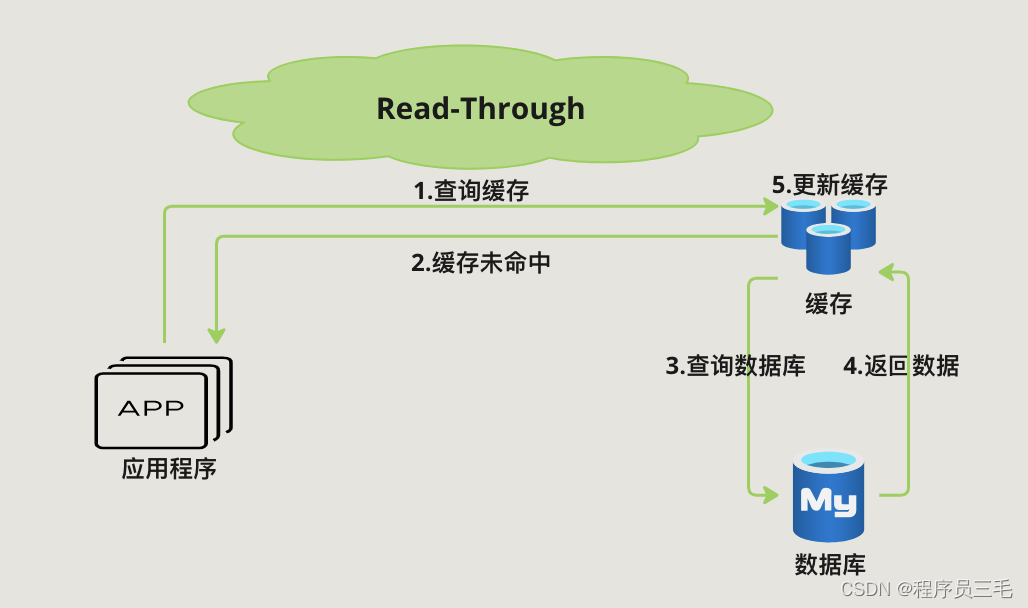
- 读取数据
- 应用程序请求数据
- 如果缓存命中,缓存层直接返回数据
- 如果缓存未命中,缓存层从数据源加载数据,更新缓存
- 更新数据:
- 应用程序更新数据源
- 缓存层可以更新或删除缓存
示例代码
public class ReadThroughExample {
// 缓存管理器
private CacheManager cacheManager;
public Data getData(String key) {
// 尝试从缓存获取数据
Data data = cacheManager.getFromCache(key);
// 缓存未命中
if (Objects.isNull(data) {
// 从数据源加载数据
data = loadDataFromDataSource(key);
// 将数据存入缓存
cacheManager.putIntoCache(key, data);
}
return data;
}
public void updateData(String key, Data newData) {
// 更新数据源
updateDataSource(key, newData);
// 更新缓存
cacheManager.updateOrDeleteCache(key);
}
}
优缺点
- 优点:
- 自动化数据加载:减少了应用程序需要编写的缓存逻辑
- 减少数据库访问:提高了数据访问的效率
- 数据保鲜:确保缓存中的数据是最新的
- 缺点:
- 实现复杂性:需要缓存层能够处理数据源的加载逻辑
- 可能的延迟:对于缓存未命中的情况,需要时间从数据源加载数据
- 缓存与数据源的依赖性:缓存层需要知道如何从数据源加载数据
应用场景
- 数据访问模式稳定的应用:适用于数据访问模式相对固定,数据更新不频繁的场景
- 对数据实时性要求不高的应用:由于数据加载过程可能存在延迟,适用于对数据实时性要求不是非常高的场景
- 需要减轻数据库负载的应用:可以有效减少对数据库的直接访问,适用于需要减轻数据库负载的应用
三、Write-Through Pattern (透写缓存)
概述
Write-Through Pattern是由应用程序在更新数据时同时更新缓存和后端数据源(如数据库)。这种策略确保了缓存和数据源之间的一致性,并减少了数据丢失的风险
工作流程
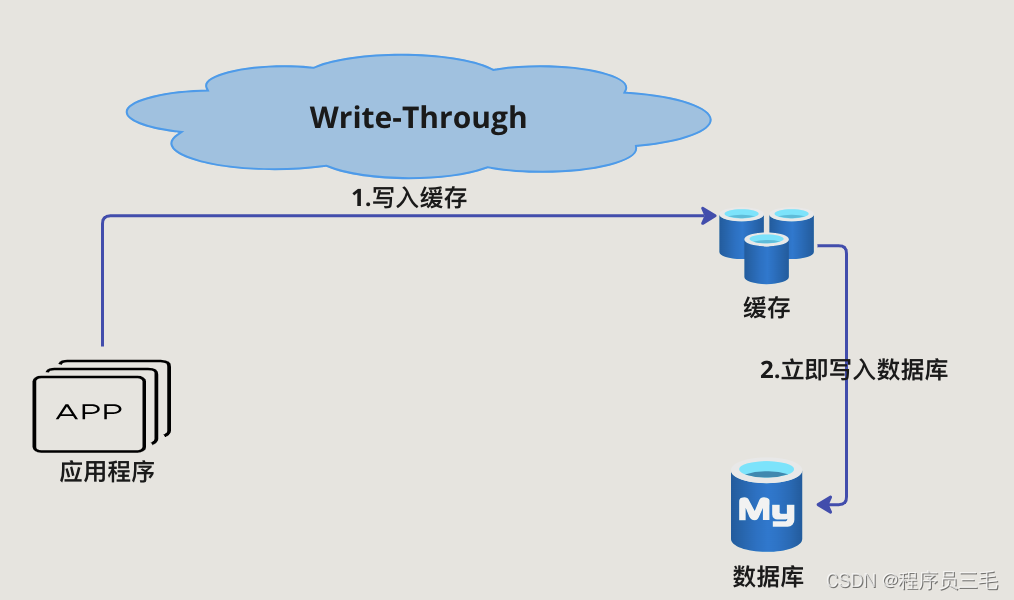
- 更新数据:
- 应用程序同时更新缓存和数据源
- 这确保了缓存中的数据总是最新的,并与数据源保持一致
示例代码
public class WriteThroughExample {
// 缓存管理器
private CacheManager cacheManager;
private Database database;
public void updateData(String key, Data newData) {
// 先更新缓存
cacheManager.updateCache(key, newData);
// 再更新数据库
database.updateData(key, newData);
}
}
优缺点
- 优点:
- 数据一致性:确保缓存和数据源之间的强一致性
- 减少数据丢失风险:由于同时更新缓存和数据源,减少了数据丢失的风险
- 缺点:
- 性能开销:每次写操作都需要同时更新缓存和数据源,可能会增加延迟
- 复杂性:需要确保缓存和数据源的更新操作都成功,增加了实现的复杂性
应用场景
- 对数据一致性要求高的应用:适用于需要确保数据在缓存和数据源之间保持一致的场景
- 写操作不频繁的应用:由于写操作会同时更新缓存和数据源,适用于写操作不是非常频繁的应用
四、Write-Back / Write-Behind Pattern (写后缓存)
概述
Write-Back / Write-Behind Pattern是由应用程序首先将数据写入缓存,然后再异步地更新后端数据源(如数据库)。这种策略可以减少对数据源的即时写操作,从而提高应用程序的性能,提升系统的TPS
工作流程
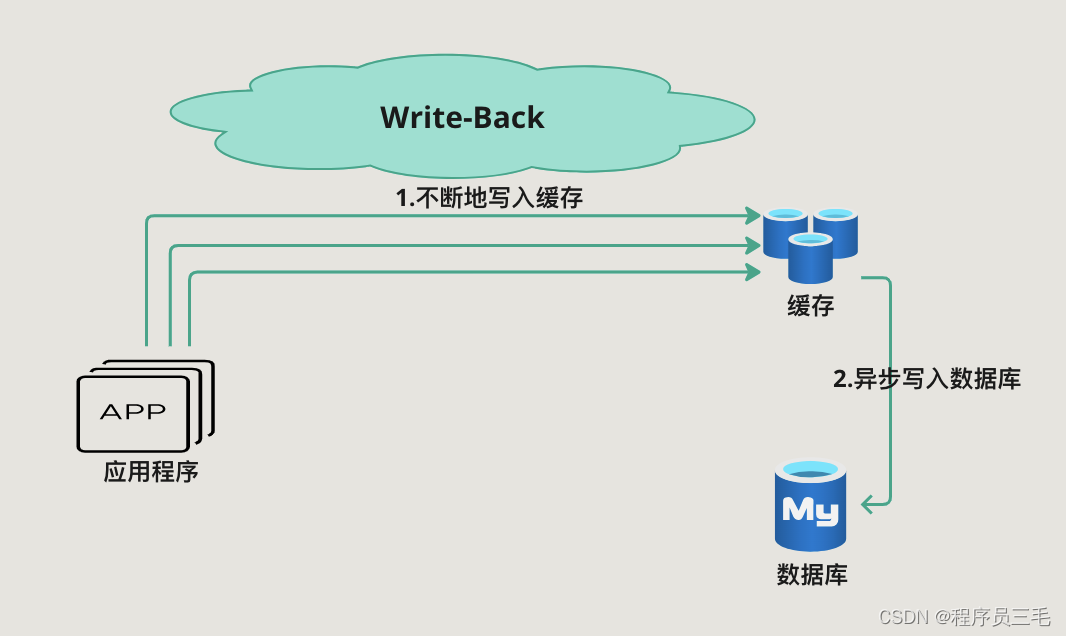
- 更新数据:
- 应用程序首先将数据写入缓存
- 缓存系统异步地将数据更新到数据库
示例代码
public class WriteBehindExample {
// 缓存管理器
private CacheManager cacheManager;
private Database database;
public void updateData(String key, Data newData) {
// 首先更新缓存
cacheManager.putIntoCache(key, newData);
// 异步更新数据源
asyncUpdateDataSource(key, newData);
}
private void asyncUpdateDataSource(String key, Data newData) {
// 更新数据库
updateDatabase(key, newData);
}
}
优缺点
- 优点:
- 提高性能:减少了对数据源的即时写操作,提高了应用程序的响应时间
- 减轻数据源负载:通过批量或异步更新数据源,减轻了对数据源的负载
- 缺点:
- 数据一致性风险:由于数据是异步写入数据源,可能存在数据一致性问题
- 复杂性:需要有效管理缓存和数据源之间的同步
应用场景
- 写操作频繁的应用:适用于写操作频繁,但对即时数据一致性要求不高的应用
- 需要提高写操作性能的应用:通过减少即时写操作的数量,提高了应用程序的整体性能
写在最后
至此,我们已经探讨了四种关键的缓存模式:Cache-Aside, Read-Through, Write-Through, 以及 Write-Back / Write-Behind。每种模式都有其独特的优势和适用场景,能够帮助我们在不同的应用环境中优化性能和数据管理。
由于篇幅过大,当前也比较晚了,要休息了😂😂,在下一篇文章中,我们将继续介绍剩余的Write-Through-Back, Refresh-Ahead, Lazy-Loading, 以及 Write-Around这四种模式
如果你对缓存策略感兴趣,或者正在寻找提升应用性能的方法,不要错过下一篇文章。确保关注我,以便第一时间获取最新的技术见解和实用建议。我是程序员三毛,欢迎大家点赞,收藏,转发。
敬请期待,下篇文章的精彩内容!

















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











