







需要在信创平台(鲲鹏ARM CPU 和 银河麒麟V10操作系统)部署Kafka存储实时采集的日志数据,需要注意的是只需要配置好ARM 版本的JDK即可。
一 、 环境信息
| 名称 | 版本 | 备注 |
|---|---|---|
| 操作系统 | 银河麒麟 V10 SP3 | |
| CPU型号 | 鲲鹏 920 | |
| JDK | bisheng-jdk-17.0.8-linux-aarch64 | 毕昇JDK 17 |
| Apache Kafka | 3.5.1 | 从3.1.0开始支持JDK17 |
二、 JDK环境配置
所有节点都需要
2.1 银河麒麟系统自带JDK卸载
- 系统自带JDK如果存在就卸载,最小化模式安装的系统没有自带JDK
yum -y remove java-1.8.0*
yum -y remove java-11*
2.2 毕昇JDK 17 安装
- 下载并解压安装
sudo mkdir -p /opt/soft/java
cd /opt/soft/java/
wget https://mirrors.huaweicloud.com/kunpeng/archive/compiler/bisheng_jdk/bisheng-jdk-17.0.8-linux-aarch64.tar.gz
tar -zxf bisheng-jdk-17.0.8-linux-aarch64.tar.gz
rm bisheng-jdk-17.0.8-linux-aarch64.tar.gz
ln -snf bisheng-jdk-17.0.8 java
- 配置环境变量
sudo su - -c 'cat >> /etc/profile << EOF
export JAVA_HOME=/opt/soft/java/java
export PATH=\$PATH:\$JAVA_HOME/bin
EOF'
- 使环境变量生效
source /etc/profile
三、Kafka部署
所有节点都需要
3.1 创建Kafka用户
adduser kafka
3.2 创建相关目录
# 创建kafka安装目录
mkdir -p /opt/soft/kafka
chown -R kafka:kafka /opt/soft/kafka
# 创建Kafka数据存储目录
mkdir -p /data/kafka
chown -R kafka:kafka /data/kafka
# 创建kafka 运行日志存储目录
mkdir -p /var/log/kafka
chown -R kafka:kafka /var/log/kafka
3.3 下载安装包并解压安装
sudo su - kafka
wget https://downloads.apache.org/kafka/3.5.1/kafka_2.12-3.5.1.tgz
# 解压安装
tar -zxf kafka_2.12-3.5.1.tgz -C /opt/soft/kafka
# 创建软连接
cd /opt/soft/kafka
ln -snf kafka_2.12-3.5.1 kafka
四、配置Kafka
4.1 修改 server.properties
进入Kafka安装目录,编辑 config/kraft/server.properties 文件,配置以下参数:
process.roles: 保持默认值broker,controller即可,每个节点同时担任 broker 和 controller 两个角色node.id:设置Kafka 节点的唯一标识,每台服务器上的 ID应该不同。controller.quorum.voters: 设置controller节点的IP和端口,格式[nodeId]@[nodeip]:[port], 多个controller 使用,隔开delete.topic.enable: 设置为true,表示允许删除 topiclisteners:设置Kafka Broker 和 Controller 监听的地址和端口,例如PLAINTEXT://:9092,CONTROLLER://:9093。log.dirs:设置Kafka Broker的日志目录,用于存储消息数据
完整 server.properties 内容如下:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# This configuration file is intended for use in KRaft mode, where
# Apache ZooKeeper is not present. See config/kraft/README.md for details.
#
############################# Server Basics #############################
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller
# The node id associated with this instance's roles
# 不通的节点需要设置不通的 ID
node.id=1
# The connect string for the controller quorum
controller.quorum.voters=1@192.168.91.101:9093,2@192.168.91.102:9093,3@192.168.91.103:9093
delete.topic.enable=true
############################# Socket Server Settings #############################
# The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
#advertised.listeners=PLAINTEXT://:9092
# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/data/kafka
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
4.2 ## 配置运行日志目录
Kafka运行时日志默认输出到$KAFKA_HOME/logs目录下,容易撑爆分区,造成操作系统崩溃。需要将日志输出到指定分区,修改 kafka-run-class.sh 脚本增加一行 LOG_DIR=“/var/log/kafka”
LOG_DIR=/var/log/kafka ## 增加这一行
# Log directory to use
if [ "x$LOG_DIR" = "x" ]; then
LOG_DIR="$base_dir/logs"
fi
五、启动kafka,并验证是否正常运行
5.1 在任意节点生成一个唯一的集群ID
/opt/soft/kafka/kafka/bin/kafka-storage.sh random-uuid
- 运行结果如下
G51vd1iCQRWn-43rdcMJUg
5.2 格式化数据存储目录
在每个节点执行以下命令
/opt/soft/kafka/kafka/bin/kafka-storage.sh format \
-t G51vd1iCQRWn-43rdcMJUg \
-c config/kraft/server.properties
5.3 启动Kafka Server
在每个节点执行以下命令
/opt/soft/kafka/kafka/bin/kafka-server-start.sh -daemon \
config/kraft/server.properties
5.4 验证集群状态
1. 创建主题
/opt/soft/kafka/kafka/bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--create --topic test \
--partitions 3 \
--replication-factor 3
2. 查看主题
/opt/soft/kafka/kafka/bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--describe test

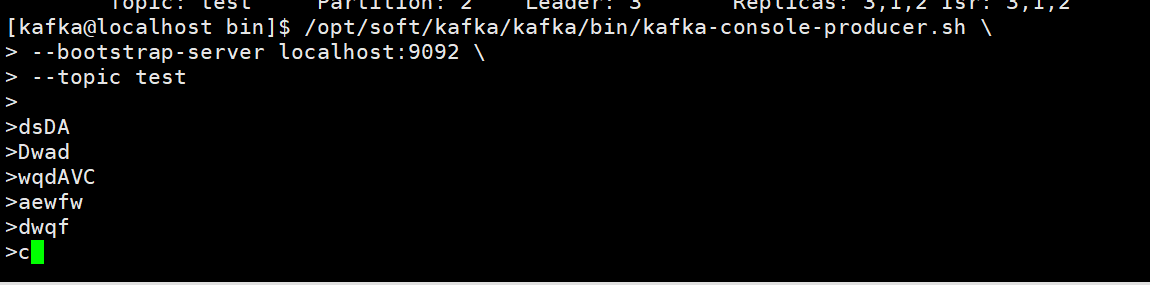
3. 控制台生产者测试
/opt/soft/kafka/kafka/bin/kafka-console-producer.sh \
--bootstrap-server localhost:9092 \
--topic test
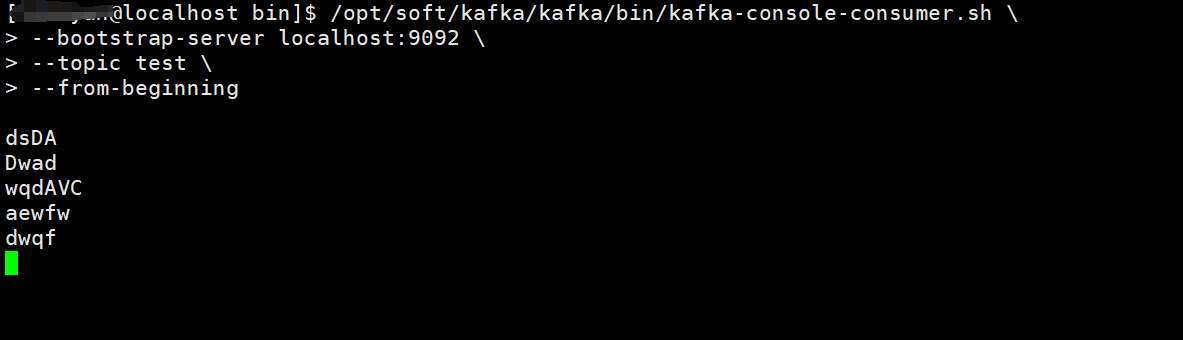
4. 控制台消费者测试
/opt/soft/kafka/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic test \
--from-beginning
5. 查看 kafka 运行日志
tail -f /var/log/kafka/server.log
















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









