







 本文介绍了如何使用Python的pandas库读取Excel文件,详细解析了pd.read_excel()的常用参数,如io、sheet_name、header、names、index_col、usecols、squeeze、converters、skiprows、nrows和skipfooter,帮助提升数据处理效率。
本文介绍了如何使用Python的pandas库读取Excel文件,详细解析了pd.read_excel()的常用参数,如io、sheet_name、header、names、index_col、usecols、squeeze、converters、skiprows、nrows和skipfooter,帮助提升数据处理效率。
本文为作者原创,未经允许不得擅自转载。
Excel是微软的经典之作,在日常工作中的数据整理、分析和可视化方面,有其独到的优势,尤其在你熟练应用了函数和数据透视等高级功能之后,Excel可以大幅度提高你的工作效率。但如果数据量超大,Excel的劣势也就随之而来,甚至因为内存溢出无法打开文件,后续的分析更是难上加难。那么,有什么更好的解决办法吗?工欲善其事,必先利其器,在这里我们介绍使用Python的pandas数据分析包来解决此问题。
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None,
usecols=None, squeeze=False,dtype=None, engine=None,
converters=None, true_values=None, false_values=None,
skiprows=None, nrows=None, na_values=None, parse_dates=False,
date_parser=None, thousands=None, comment=None, skipfooter=0,
convert_float=True, **kwds)
pandas读取Excel后返回DataFrame,接下来我们就pd.read_excel()的常用参数进行详细解析。
目录
【文中使用英超、西甲的排名积分榜及射手榜作为原始数据~~~】
1、io,Excel的存储路径
- 建议使用英文路径以及英文命名方式。
import pandas as pd
io = r'C:\Users\Administrator\Desktop\data.xlsx'2、sheet_name,要读取的工作表名称
- 可以是整型数字、列表名或SheetN,也可以是上述三种组成的列表。
-
整型数字:目标sheet所在的位置,以0为起始,比如sheet_name = 1代表第2个工作表。
data = pd.read_excel(io, sheet_name = 1)
data.head()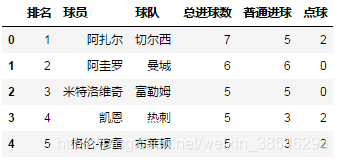
- 列表名:目标sheet的名称,中英文皆可。
data = pd.read_excel(io, sheet_name = '英超射手榜')
data.head()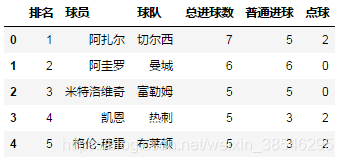
- SheetN:代表第N个sheet,S要大写,注意与整型数字的区别。
data = pd.read_excel(io, sheet_name = 'Sheet5')
data.head()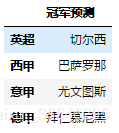
- 组合列表: sheet_nam
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









