







LFU算法族相关文章目录汇总:
LFU算法(本文)
1、原理
LFU(Least Frequently Used)算法,即最少访问算法,根据访问缓存的历史频率来淘汰数据,核心思想是“如果数据在过去一段时间被访问的次数很少,那么将来被访问的概率也会很低”。
2、数据结构
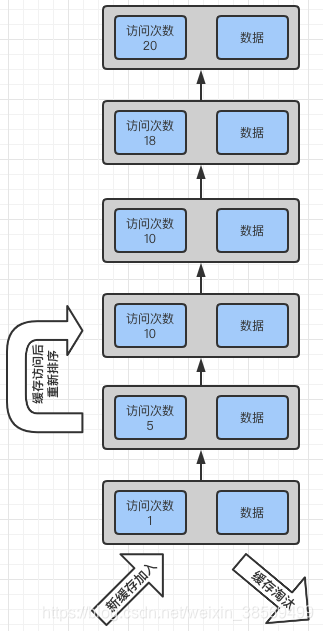
一般会维护两个数据结构:
- 哈希:用来提供对外部的访问,查询效率更高;
- 双向链表或队列:维护了对元素访问次数的排序
缓存操作导致的链表变化:
- 添加新元素:新元素访问次数为1,放到队尾;
- 缓存淘汰:从队尾开始淘汰,因为队尾元素的访问次数最少;
- 访问缓存:访问缓存会增加元素的访问次数,所以元素在队列或双向链表中的位置会重新排序
图示:
3、特点
3.1 优点
- 一般情况下,LFU效率要优于LRU,能够避免周期性或者偶发性的操作导致缓存命中率下降的问题
3.2 缺点
- 复杂度较高:需要额外维护一个队列或双向链表,复杂度较高
- 对新缓存不友好:新加入的缓存容易被清理掉,即使可能会被经常访问
- 缓存污染:一旦缓存的访问模式发生变化,访问记录的历史存量,会导致缓存污染;
- 内存开销:需要对每一项缓存数据维护一个访问次数,内存成本较大;
- 处理器开销:需要对访问次数排序,会增加一定的处理器开销

















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









