







写在前面的话:本篇博客为原创,认真阅读需要比对spark 2.1.1的源码,预计阅读耗时30分钟,如果大家发现有问题或者是不懂的,欢迎讨论
欢迎关注公众号:后来X
spark 2.1.1的源码包(有需要自取):关注公众号【后来X】,回复spark源码
上一篇博文,我们看了在Yarn Cluster模式下,从Spark-submit提交任务开始,到最后启动了ExecutorBackend线程,也就是进行到了图中的第9步。
上一篇博文地址:https://blog.csdn.net/weixin_38586230/article/details/104342440
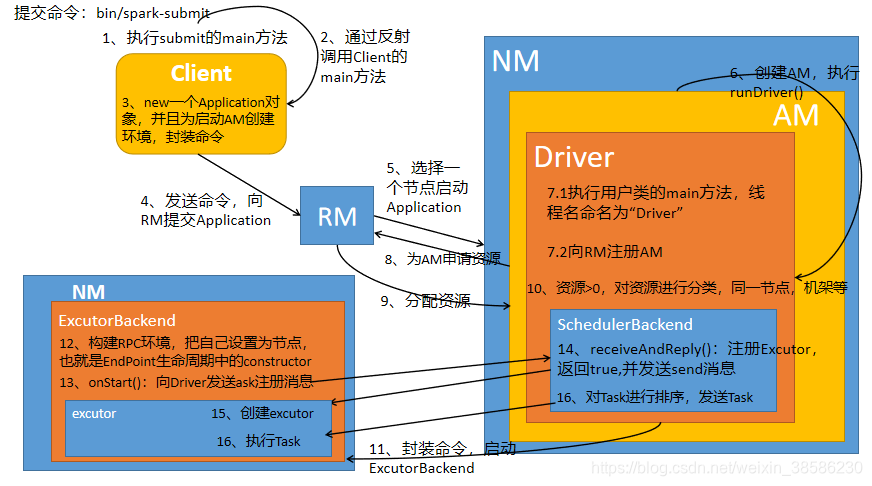
1、接下来先看Excutor端向Driver注册
那么今天接着看ExecutorBackend进程做了什么,上次最后一步为startContainer,但是实际的命令为:
/bin/java org.apache.spark.executor.CoarseGrainedExecutorBackend
所以首先double shift,找到org.apache.spark.executor.CoarseGrainedExecutorBackend,
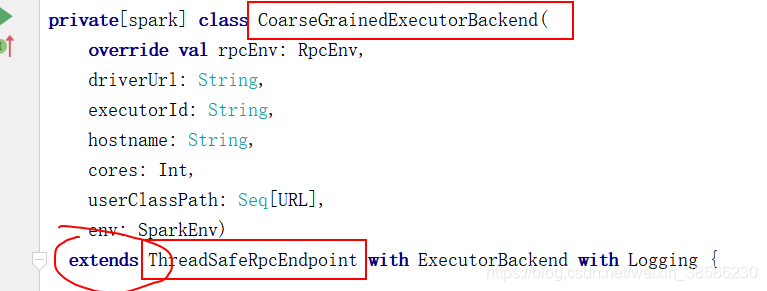
我们发现这个类继承了extends ThreadSafeRpcEndpoint,所以说这个类也是一个Endpoint(RPC通信中的重要成员,不了解RPC通信的请先自行百度,之后我补上后附博客地址)
- 找到该线程的执行入口,main方法,发现主要是对参数的赋值
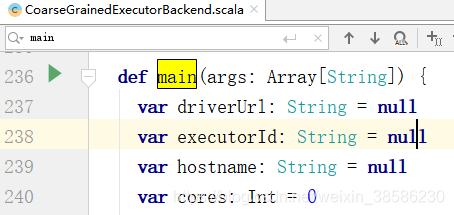
- 往下滑,找到了其中的run方法,点进去,我们看看是怎么执行的

- 既然这个类为EndPoint,所以它也要构建环境
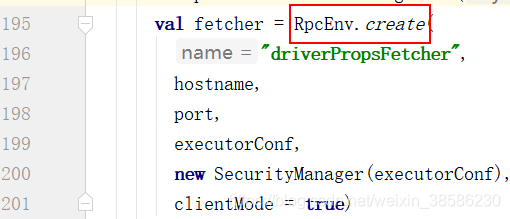
- 同时作为EndPoint,还需要把自己设置为节点,也就是EndPoint生命周期中的constructor

- 按照生命周期,接下来该运行onStart()方法,通过ctrl + F,找到这个方法,同时还向Driver发送注册消息
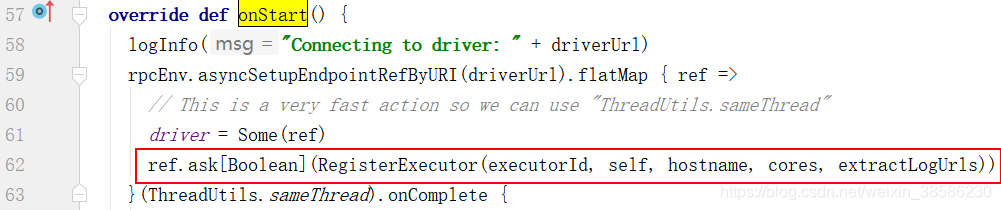
- 因为使用的是ask,所以应该由CoarseGrainedSchedulerBackend类中的receiveAndReply()方法来进行接收
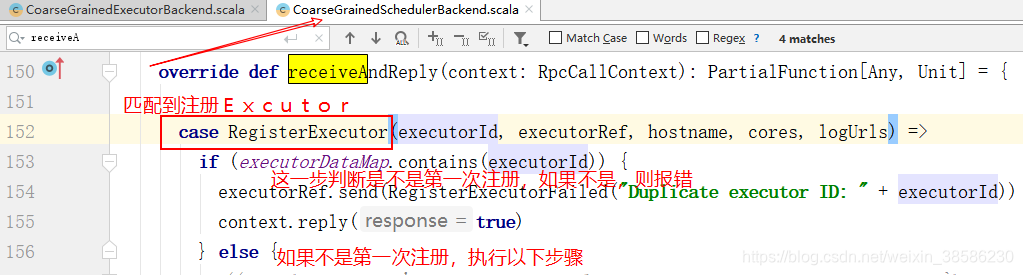
- 如果可以注册,就返回true,并发送消息,由CoarseGrainedExecutorBackend类的receive()方法接收
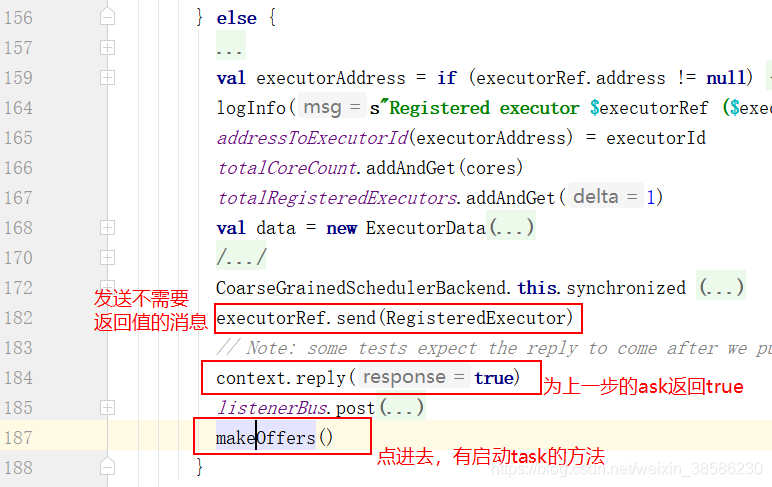
- 收到上一步发送的消息,创建Excutor

- 从第7步中的主线makeOffsets()方法进入,启动任务

- 先执行括号内的scheduler.resourceOffers(workOffers),主要是对task进行了排序

- 第10步执行完括号内部的再返回来执行launchTasks,在里面发送消息
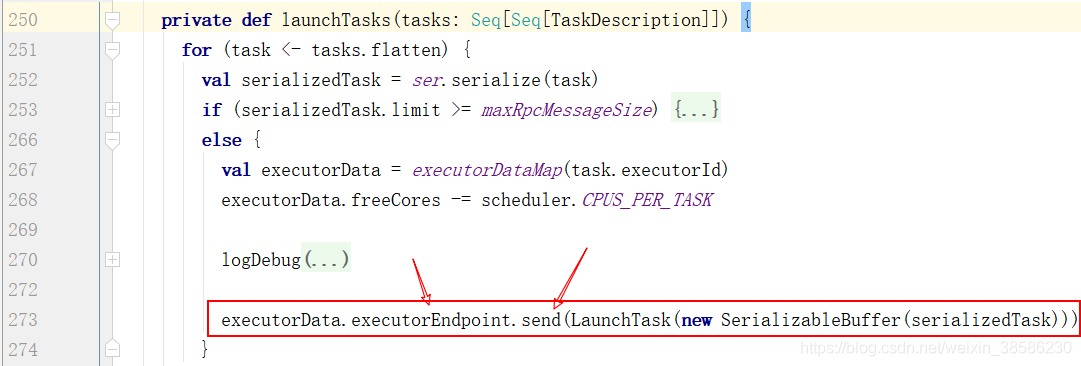
- 这个消息肯定是由CoarseGrainedSchedulerBackend类中的receive方法进行接收,匹配到任务的执行。
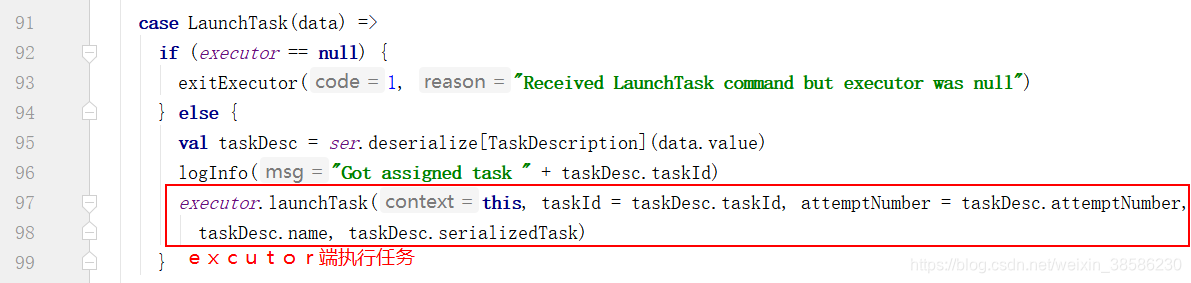
上面这段过程进行了excutor端向Driver端进行注册,注册成功后,Driver端向excutord端发送任务,excutor端进行执行,
那么Driver端既然要向excutor端发送任务,就得先进行任务的切分,下面我们来分析Task任务的划分的源码分析
2、Task 任务的切分
说到任务的划分,就不得不提到RDD,我们知道在spark中,算子只有在遇到行动算子才会执行(如collect()),转换算子都是懒加载,所以要想知道Task任务怎么划分的,得先从行动算子看起,我们下面以WordCount项目为例:
word Count的Jar包的代码如下:
dataRDD.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).collect()
- 先double shift到RDD中,在ctrl + F 拿到collect(),执行其中的runJob方法
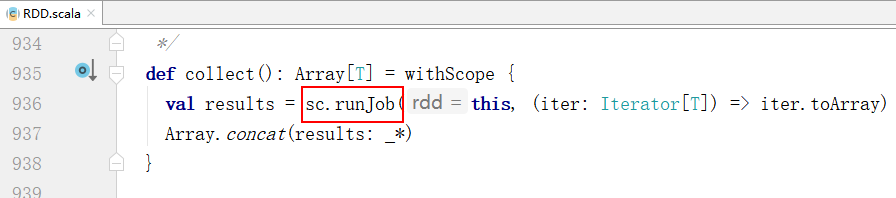
- 经过3次runJob的调用后(中间省略了3次点击runJob),终于到了dagScheduler的调用上(DAG为有向无环图)
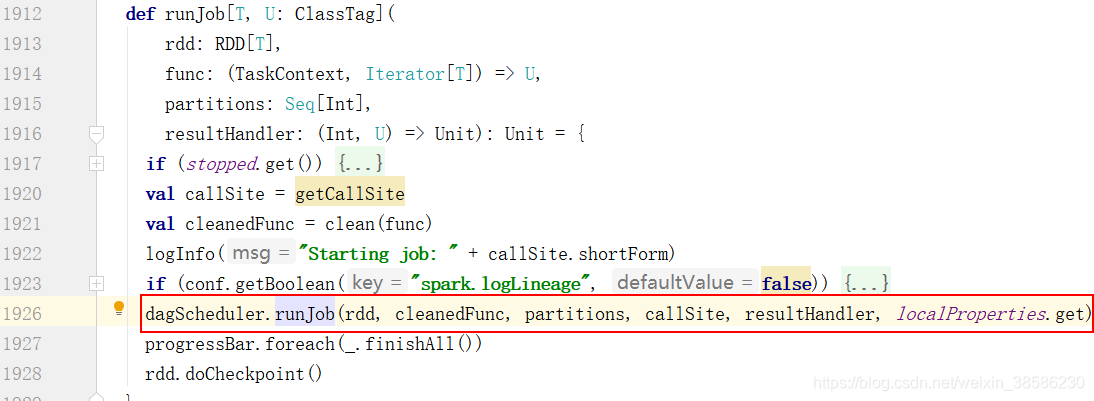
- 在这个runJob中,终于找到了提交Job的函数
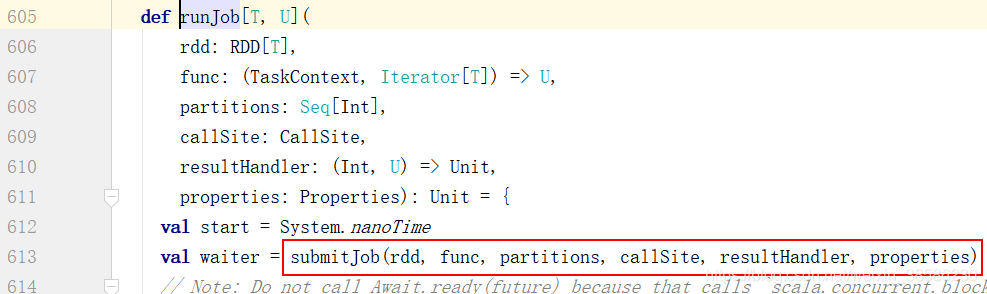
- 在这个方法中,给自己发送一个提交任务的作业

- 那么有post给自己发送,就有receive自己接收,所以我们ctrl + F 搜索receive()方法,果然有一个方法来专门处理收到的event
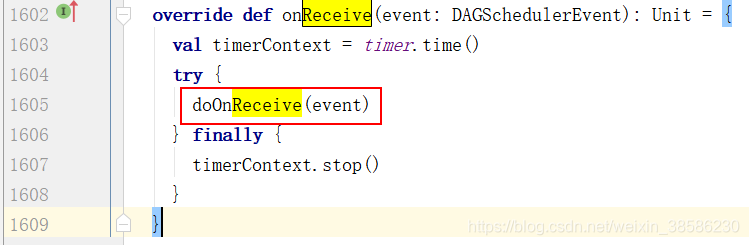
- 进去这个方法,匹配到了Job提交,所以执行dagScheduler.handleJobSubmitted

- 怎么处理呢?先创建最终阶段

- 让我们看下创建的过程,在这里面获取到了最终的父阶段,还拿到了所有的shuffle依赖
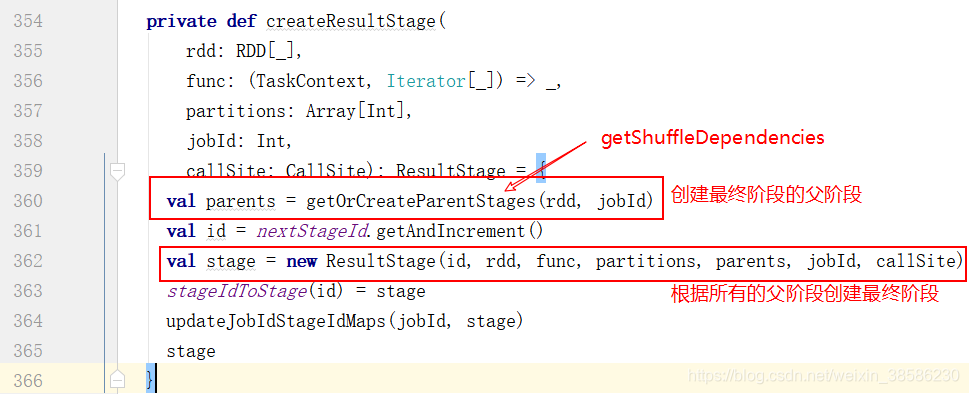
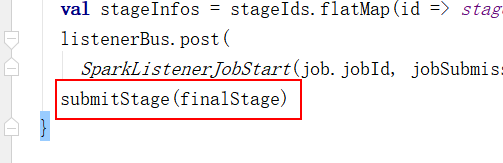
- 现在已经获取到了最终阶段的stage,我们返回到第7步这个位置,滑倒这个handle方法的最下面,找到了提交任务的最终阶段
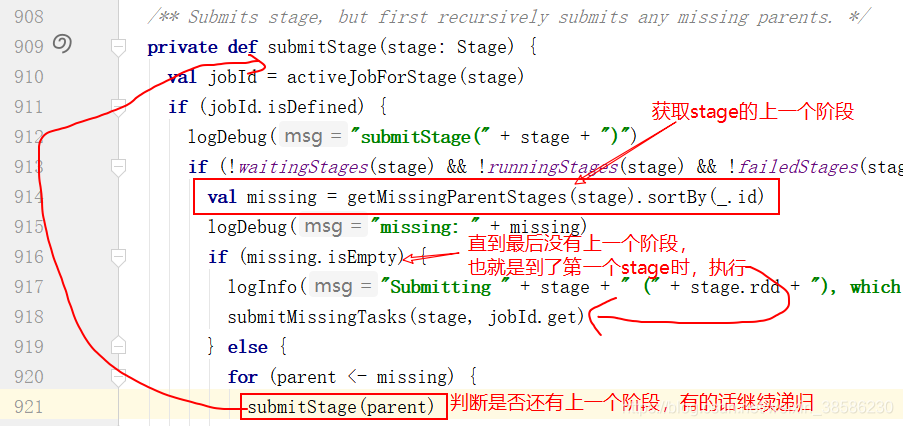
- 那我们来看一下它怎么提交最终阶段,但是却实际上时先提交的第一阶段呢?获取最后一个stage的上一个stage,然后判断上一个stage是否为空,如果不为空,就继续递归调用该方法,直到没有上一个stage,也就是到达第一个stage时,开始执行submitMissingTasks(stage, jobId.get)
- 接下来我们进入submitMissingTasks,匹配stage,获取到最优先的资源位置来运行job


- 再往下滑,定义了这个tasks,并且根据stage的依赖情况赋值
val tasks = partitionsToCompute.map{new ShuffleMapTask}
val tasks = partitionsToCompute.map{new ResultTask}
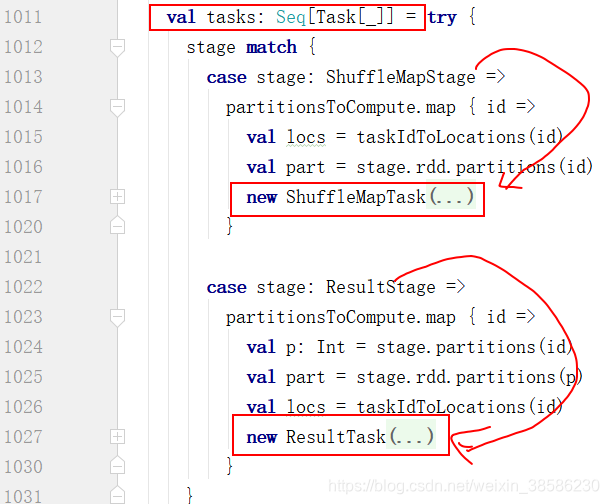
- 再往下滑,把任务由DAGScheduler交由TaskScheduler处理

以下就是在TaskScheduler类中处理了
- 从一步的方法进来,发现这个方法是抽象的,我们找实现类

ctrl + h,找到实现类TaskSchedulerImpl - 把tasks封装成TaskSetManager,并且放入调度池中
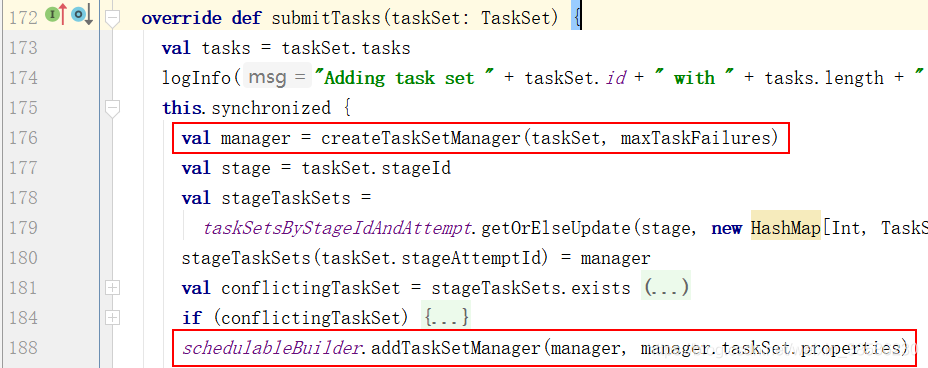
- 然后往下滑一下,执行:backend.reviveOffers(),从这个方法进入,ctrl + h 获取实现类CoarseGrainedSchedulerBackend,找到reviveOffers
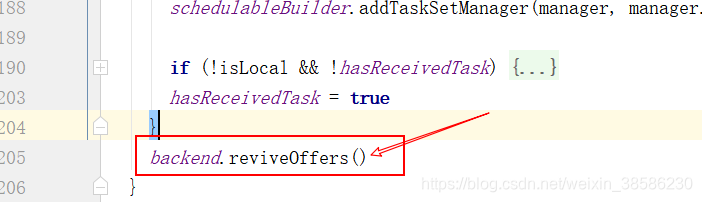

在该方法中,执行launchTasks(scheduler.resourceOffers(workOffers))

好了,到此任务切分的源码也分析完了,再返回来这张流程图,所有的步骤都已经分析完了,合起来也就是 Excutor端向Driver端注册后,Driver端把切分好的任务按照位置最优策略分配给Excutor。
下一次我们继续给大家详细分析上面的第15步,TaskSetManager如何放入调度池中,并且了解调度池的区别,以及在调度池中如何进行排序。
最后,我知道自己表达的知识点还很欠缺,欢迎大家指正与讨论,欢迎关注我的公众号:后来X,回复:spark源码,获取spark2.1.1源码包
持续更新,未完待续!














 942
942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









