







文章目录
哈希函数和哈希表
1 哈希函数
性质:
- 输入域:无穷大
- 输出域:固定大小
- 相同的输入必定会有相同的hashcode
- 存在不同输入对应相同hashcode的情况
- hashcode具有离散型(而且和输入没有关系,可以打乱输入规律)
- 如果hashcode是均匀分布的,那么对hashcode取余之后,结果也是均匀分布的
- hashcode中每一位和其他位都是相互独立的
默认:哈希表的增删改查是O(1)的
1.1 大数据类型问题
利用hash函数来对大文件进行分流
1.2 设计RandomPool结构

算法:
注意:要求是等概率,而且时间复杂度还要是O(1),等概率考虑到使用随机数生成,但是需要index,所以想到Map结构;在删除操作中可能会在0~size-1之间产生一个洞,所以需要用最后一位来填
- 准备两个Map,一个全局变量size。第一个map用于存放key和index,其中index是我们自己用来构建索引的;第二个map用于存放index和key,其中index是用来通过随机数获取key的
- add操作:map1中,加入<String1, index1>, map2中加入<index1, String1>, size++
- 当需要getRandom的时候,用Math.Random()*size获得 [0, size) 区间内的随机一个数,从map2中查找
- 当进行remove(key)操作的时候,将map1的最后一位覆盖key对应的一位,将map2的最后一位覆盖key对应的一位,然后将最后一条数据删除, size- -
2 布隆过滤器
应用场景:爬虫去重问题,黑名单问题
布隆过滤器存在的问题:宁可错杀3000,也不放过1人(会存在比较低的失误率)
底层为一个bit数组
2.1 在一个32000bit长的数组中,如何将第30000个位置的bit置1?
int[] arr = new int[1000];
int index = 30000;
int intIndex = index/32;
int bitIndex = index%32;
arr[intIndex] = (arr[intIndex] | (1<<bitIndex));

2.2 实际的布隆过滤器(判断Url是否在黑名单里)
详细了解:布隆过滤器(Bloom Filter)详解 - 李玉龙 - 博客园 (cnblogs.com)
- 准备一个足够大的数组
- 准备黑名单:将url经过hash函数之后,生成一个code,对数组长度取模(类似上面的方法),将相应桶中相应位置描黑
- 用k个hash函数做同样的操作,数组中最多将有k个位置被描黑(置1)
- 当要检查一个url是否在黑名单中时,对这个url取k次hashcode,看对应的k位置是否被描黑
- 如果k个位置全部被描黑,那么这个url可能就属于这个黑名单中
- 只要有一个位置不是被描黑的,就能够判断这个url没有在黑名单中
如何决定n的大小(bit数组的大小):
n = − m × ln ( p ) ( ln 2 ) 2 n = -\frac{m\times\ln(p)}{(\ln2)^2} n=−(ln2)2m×ln(p)
n是数组的长度,m是样本量,p预期失误率
如何确定hash函数的个数:
k = ln 2 × n m k = \ln2\times\frac{n}{m} k=ln2×mn 向上取整
真实失误率:
( 1 − e − m × k n ) k (1-e^-\frac{m\times k}{n})^k (1−e−nm×k)k
3 一致性哈希
降低数据迁移的代价,仍能保证负载均衡
在负载均衡的时候,面对服务器设备增加的情况,需要进行全部的数据迁移,重新进行哈希。
而在一致性哈希的结构下,可以避免对hashcode取模,高效的应对设备数量变化的情况
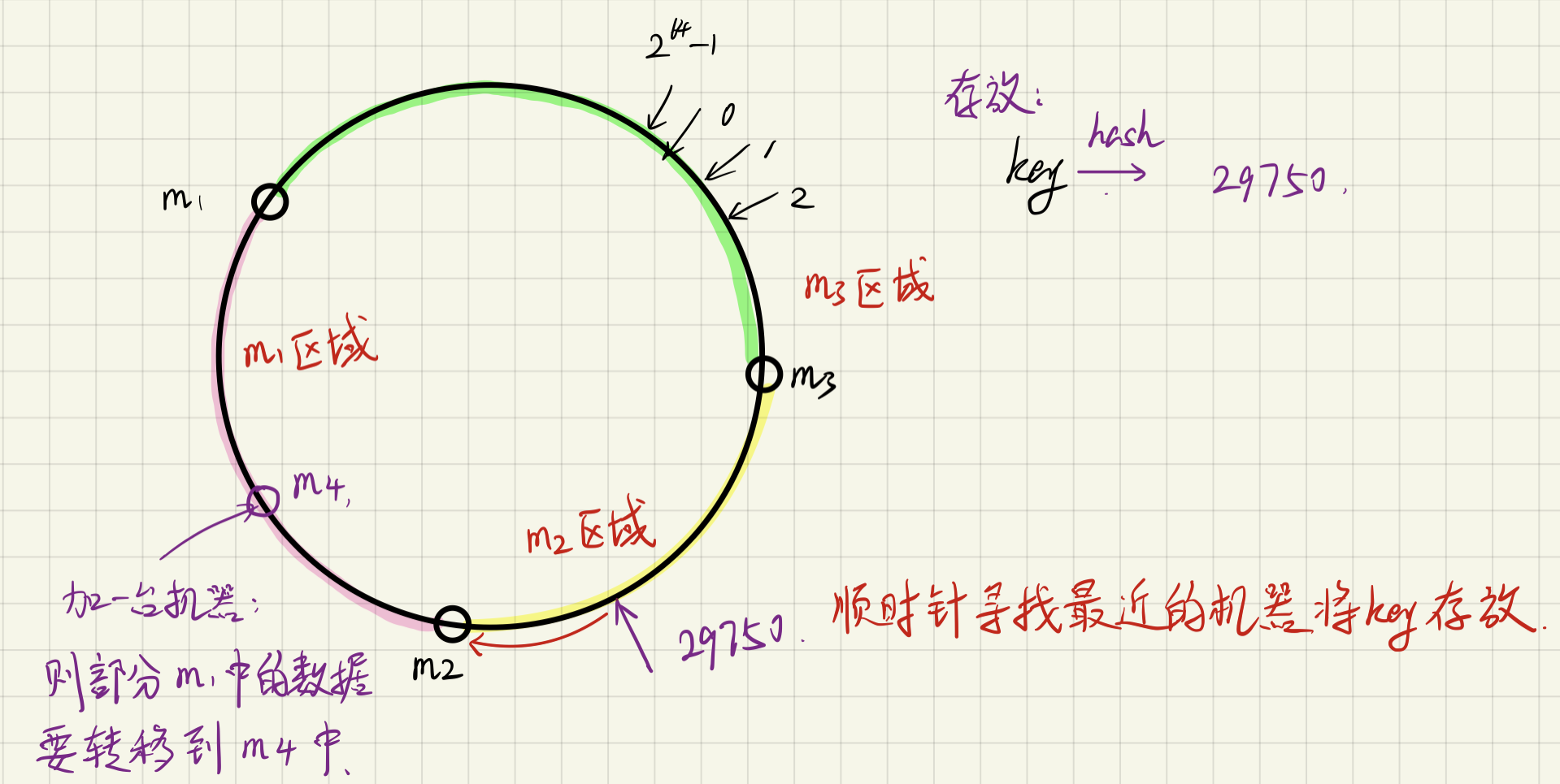
如何实现在环形结构中找到顺时针最近的服务器?
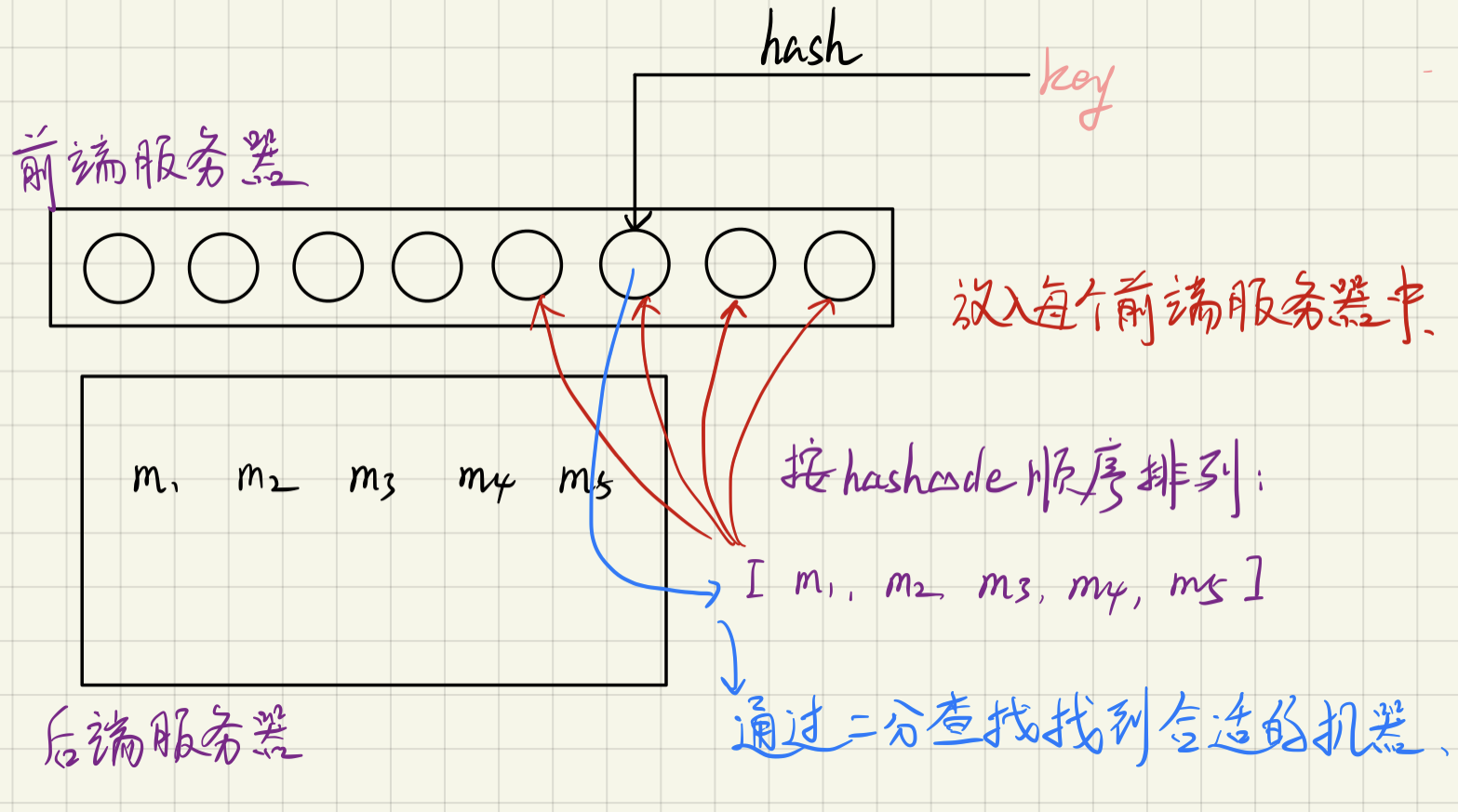
面临的问题:
- 当服务器数量很少的时候很难做到均匀负载,即便做到了均匀负载,加入新的服务器的时候,负载又会被破坏
解决方案:虚拟节点技术
一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布















 7058
7058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









