







CUDA全称(Compute Unified Device Architecture),是 NVIDIA开发的一款用于驱动GPU的统一计算设备架构,包含了许多底层API函数,通常用于GPU的并行计算开发。
CPU与GPU的的硬件架构区别

两者最大不同在于:
CPU有控制单元Control,和算数逻辑单元ALU,负责逻辑性强的事务处理;GPU具有大量的并行化现成网格单元,专注于执行高度线程化的并行处理任务。
CPU与GPU之间的协同化:
在GPU 计算中,CPU 和GPU 之间是相连的,是一个异构的计算环境。应用程序当中顺序执行这一部分的代码是在CPU 里面进行执行的,而并行的也就是计算密集这一部分是在GPU 里面进行。两者通信方式如下:

CPU称为主机(host),GPU称为设备(device)
通信模式如下:
1.CPU分配空间给GPU;
2.CPU将数据复制到GPU设备中的内存(包括全局内存,常量内存,纹理内存,共享内存等,这里后面具体补充);
3.CPU加载kernels,并在设备上执行核函数(kernel,又是个并行化很关键的概念,可以理解为c语言中的函数,不过在GPU上执行运算而已)
4.将设备内存中核函数的返回数据复制到主机内存
5.释放设备内存空间
GPU网格线程理解:

CUDA 在执行的时候是让device 里面的一个一个的kernel 按照线程网格(Grid)的概念在显卡硬件(GPU)上执行。每一个线程网格又可以包含多个线程块(block),每一个线程块中又可以包含多个线程(thread)。
以军队来打比方,每一个线程,就相当于每一个士兵,当要执行某一个大的军事任务的时候,大将军(Host)发布命令,(device)把这次行动分解成一个一个的子任务(kernel_1,kernel_2……kernel_M),每个子任务由不同的统领(Grid)负责,各统领又把任务分成一部分一部分,划分给手下的小头目(Block),这些任务就由小头目下的士兵(Thread)去执行完成。
GPU内部硬件结构:
SM(stream multiprocessor): 流处理器(包含进程和内存)
GPU:每个GPU有若干个SM,最少有1个,目前16个算大的,每个SM并行而独立运行。
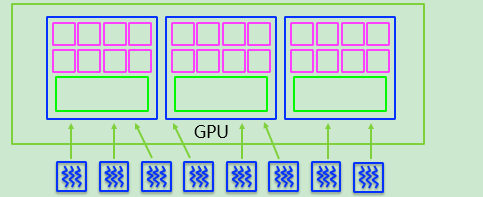
GPU中核函数(kernels)以线程网格(Grid)的形式组织,每个线程网格(Grid)又由很多个线程块(block)组成,线程块(block)里面包含了很多个线程(thread)。【这里就要产生对线程的寻址,包含一维的网格,二维网格,还有以后的三维网格,下节介绍线程】

CUDA 的本质:
CUDA 的本质是,NVIDIA .为自家的GPU 编写了一套编译器NVCC 极其相关的库文件。CUDA 的应用程序扩展名可以选择是cu,而不是.cpp 。
NVCC 是一个预处理器和编译器的混合体。当遇到CUDA 代码的时候,自动编译为GPU 执行的代码,也就是生成调用CUDA Driver 的代码。如果碰到Host C++代码,则调用平台自己的C++编译器进行编译,比如Visual Studio C++自己的Microsoft C++ Compiler。然后调用Linker 把编译好的模块组合在一起,和CUDA 库与标准CC++库链接成为最终的CUDA Application。
NVCC 模仿了类似于GCC 一样的通用编译器的工作原理(GCC 编译CC++代码本质上就是调用cc 和g++)。
















 4622
4622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









