







1、索引简介
- MySQL官方对索引的定义为:索引(
Index)是帮助MySQL高效获取数据的数据结构。 - 数据库除了数据本身之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据。
- 索引的本质:索引是
数据结构。
优势
- 类似大学图书馆建书目索引,提高数据检索效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序成本,降低了CPU的消耗
劣势
- 实际上索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引列也是要占用空间的。
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如果对表INSERT,UPDATE和DELETE。因为更新表时,MySQL不仅要不存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
- 索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立优秀的索引,或优化查询语句
索引的分类
| 类型 | 描述 |
|---|---|
| 唯一索引 | 索引列的值必须唯一,但允许有空值 |
| 复合索引 | 即一个索引包含多个列 |
| 单值索引 | 即一个索引只包含单个列,一个表可以有多个单列索引 |
| 聚集索引 | 主键索引,一个表只能有一个聚集索引 |
| 非聚集索引 | 非主键索引的叶子节点内容是主键的值 |
| 覆盖索引 | 查询列在索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。 |
2、索引的数据结构
B+树
B+树是为了磁盘或其它存储设备而设计的一种平衡多路查找树,主要性质如下:
- 1、非叶子节点的子树指针与关键字个数相同;
- 2、非叶子节点的子树指针p[i],指向关键字值属于[k[i],k[i+1]]的子树.(B树是开区间,也就是说B树不允许关键字重复,B+树允许重复);
- 3、为所有叶子节点增加一个链指针;
- 4、所有关键字都在叶子节点出现(稠密索引). (且链表中的关键字恰好是有序的);
- 5、非叶子节点相当于是叶子节点的索引(稀疏索引),叶子节点相当于是存储(关键字)数据的数据层;
- 6、更适合于文件系统;

hash桶
- 对索引的
key进行一次hash计算就可以定位出数据存储的位置 - 很多时候
Hash索引要比B+树索引更高效 - 仅能满足
=,IN,不支持范围查询 hash冲突问题

注意:Mysql表必须存在一个唯一的主键索引,如果不存在会默认生成一个隐藏列rowId主键
3、Mysql不同引擎的索引存储区别
MyISAM索引文件和数据文件是分离的(非聚集)

InnoDB索引实现(聚集),表数据文件本身就是按B+Tree组织的一个索引结构文件

4、索引的使用场景
| 合适的场合 | 不合适的场合 |
|---|---|
| 主键自动建立唯一索引 | Where条件里用不到的字段不创建索引 |
| 频繁作为查询的条件的字段应该创建索引 | 表记录太少 |
| 查询中与其他表关联的字段,外键关系建立索引 | 经常增删改的表 |
| 频繁更新的字段不适合创建索引 | 数据重复且分布平均的表字段 |
| 查询中排序的字段,排序字段若通过索引去访问将大大提高排序的速度 | |
| 查询中统计或者分组字段 |
常见问题
1、为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
- 整型的主键,在查询排序的操作中,对比的效率会高
- 自增有序的话,索引在创建的时候都是往后插入或者新增页,但是如果是无序的话,页数满了会分裂在平衡,效率会慢很多,索引主键最好是自增的。
假如有下面一个B+树,每一页只能存3个主键的话,如果插入9的话,直接在最后一个页最后插入就可以的
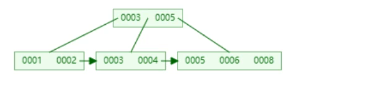
但是如果是插入7的话则需要会分裂在平衡,效率就变低了
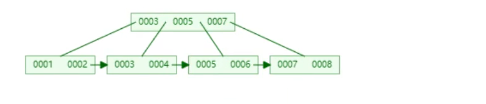
2、为什么mysql页文件默认16K?
- 查看
mysql文件页大小(16K):SHOW GLOBAL STATUS like 'Innodb_page_size’; - 假设我们一行数据大小为
1K,那么一页就能存16条数据,也就是一个叶子节点能存16条数据;再看非叶子节点,假设主键ID为bigint类型,那么长度为8B,指针大小在Innodb源码中为6B,一共就是14B,那么一页里就可以存储16K/14=1170个(主键+指针) - 那么一颗高度为
2的B+树能存储的数据为:1170*16=18720条,一颗高度为3的B+树能存储的数据为:1170*1170*16=21902400(千万级条)
3、为什么非主键索引结构叶子节点存储的是主键值?
数据的一致性和节省存储空间















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









