






实施前提:学习scrapy用法、Xpath用法、数据库连接方法(选用数据库:pymysql、pymongo、redis其中之一或几个)。观察网易云各排行榜之间的id关系。
具体实施:
踩点:图片如下
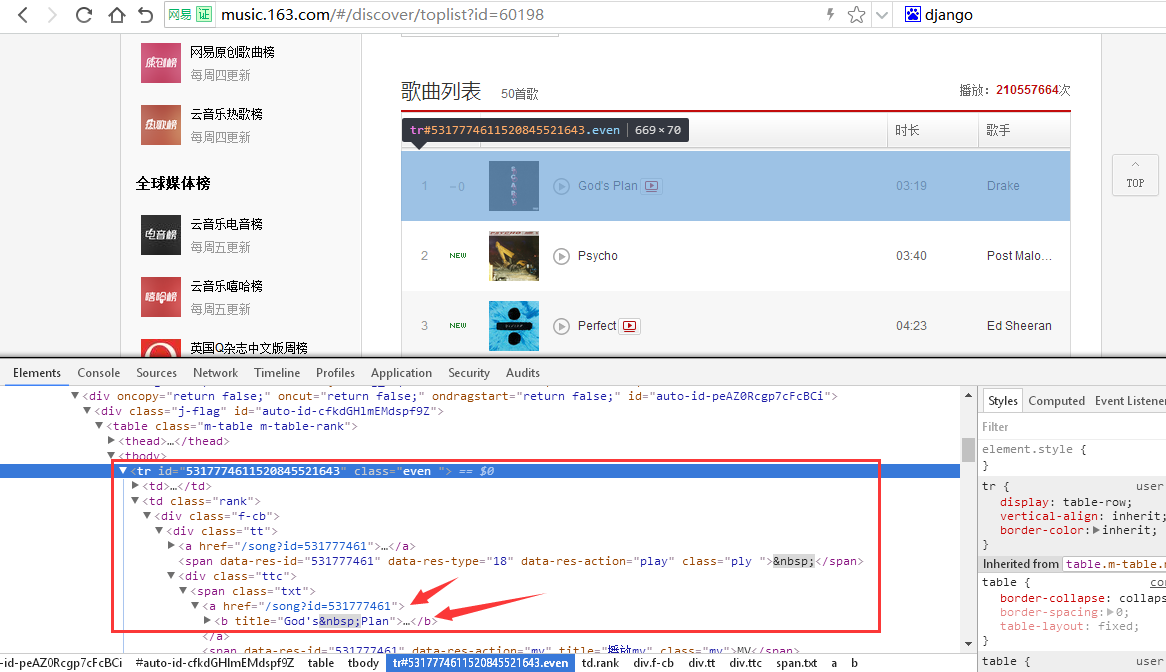
分析:页面嵌套真的是好多,比较头疼,总体思路就是,在tr标签且class = even下寻找<td class = 'rank'> 到 <div class = "f-cb">到<div class = "tt"> 到 <div class = "ttc">到<span class = "txt">中查找歌曲id,其中href="......"就是歌的链接地址的一部分,<b title=...>即为歌曲名字















 5033
5033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









