







目录
1. ArrayList
类图
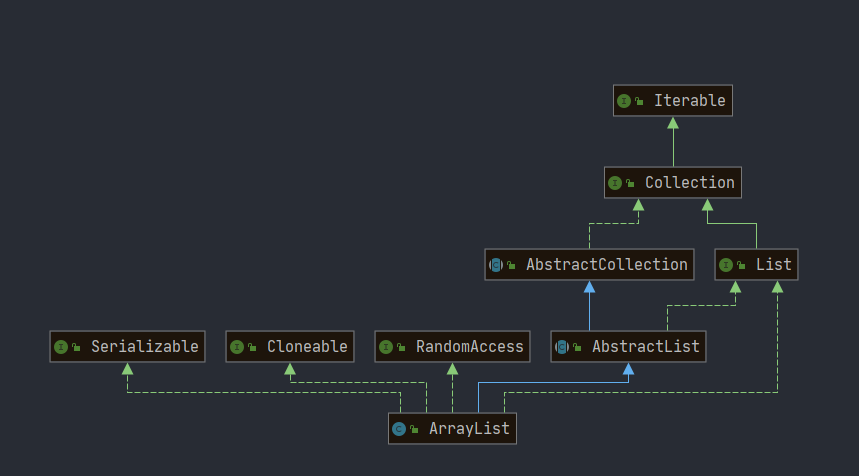
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
}RandomAccess是一个标志接口,表明实现这个这个接口的 List 集合是支持快速随机访问的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。ArrayList实现了Cloneable接口 ,即覆盖了函数clone(),能被克隆。ArrayList实现了java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
源码分析:
1.默认初始容量大小
private static final int DEFAULT_CAPACITY = 10;2.修改这个ArrayList实例的容量是列表的当前大小。 应用程序可以使用此操作来最小化ArrayList实例的存储。
public void trimToSize() {
++this.modCount;
if (this.size < this.elementData.length) {
this.elementData = this.size == 0 ? EMPTY_ELEMENTDATA : Arrays.copyOf(this.elementData, this.size);
}
}
3.每次扩容到原来的1.5倍
Q:MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8
A: 数组有点特殊性,数组对象要额外存储数组元素长度在头部,少了这8个长度可能与此有关。
尝试分配大于 MAX_ARRAY_SIZE 长度的数组会导致 OOM (换句话说,超过了该虚拟机的数组长度限制)
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//再检查新容量是否超出了ArrayList所定义的最大容量,
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}hugeCapacity函数:
- min capacity 这次扩容最小需要的容量
- old capacity 扩容前原始数组容量
- newCapacity = oldCapacity + (oldCapacity >> 1) 是预计要扩容到的容量
newCapacity 尽量不扩容到超过MAX_ARRAY_SIZE,如果MAX_ARRAY_SIZE都不够用那没办法了,就得Integer.MAX_VALUE了

private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素);
*返回的数组的运行时类型是指定数组的运行时类型。 如果列表适合指定的数组,则返回其中。
*否则,将为指定数组的运行时类型和此列表的大小分配一个新数组。
*如果列表适用于指定的数组,其余空间(即数组的列表数量多于此元素),则紧跟在集合结束后的数组中的元素设置为null 。
*(这仅在调用者知道列表不包含任何空元素的情况下才能确定列表的长度。)
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size)
// 新建一个运行时类型的数组,但是ArrayList数组的内容
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
//调用System提供的arraycopy()方法实现数组之间的复制
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}/** * 在此列表中的指定位置插入指定的元素。 *先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大; *再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。 */
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//arraycopy()这个实现数组之间复制的方法一定要看一下,下面就用到了arraycopy()方法实现数组自己复制自己
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
} public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//arraycopy()这个实现数组之间复制的方法一定要看一下,下面就用到了arraycopy()方法实现数组自己复制自己
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}/**
* 从列表中删除所有元素。
*/
public void clear() {
modCount++;
// 把数组中所有的元素的值设为null
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}removeAll和rettainAll(batchRemove(Collection<?> c, boolean bool)表示list中包含(bool==true)、不包含(boolbool==false)c中的元素回被保留)
/**
* 从此列表中删除指定集合中包含的所有元素。
*/
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
//如果此列表被修改则返回true
return batchRemove(c, false);
}
/**
* 仅保留此列表中包含在指定集合中的元素。
*换句话说,从此列表中删除其中不包含在指定集合中的所有元素。
*/
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}2.LinkedList
类图
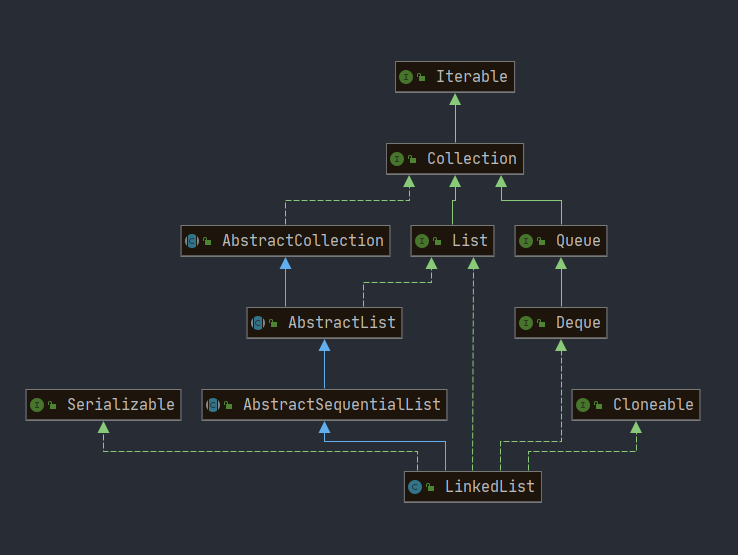
LinkedList 是基于节点实现的双向链表的 List ,每个节点都指向前一个和后一个节点从而形成链表。
实现接口:相比ArrayList 少了RandomAcess 多了Deque
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable数据结构
private static class Node<E> {
E item;//节点值
Node<E> next;//后继节点
Node<E> prev;//前驱节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}源码分析
获取头结点数据
getFirst(),element(),peek(),peekFirst() 这四个获取头结点方法的区别在于对链表为空时的处理,是抛出异常还是返回null,其中getFirst() 和element() 方法将会在链表为空时,抛出异常
获取尾节点数据
两者区别: getLast() 方法在链表为空时,会抛出NoSuchElementException,而peekLast() 则不会,只是会返回 null。
获取数据索引
int indexOf(Object o): 从头遍历找
int lastIndexOf(Object o): 从尾遍历找
删除头节点
remove() ,removeFirst(),pop(): 删除头节点(三种方法最终都调用
public E pop() {
return removeFirst();
}
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}若为空抛出异常)
删除尾节点
区别: removeLast()在链表为空时将抛出NoSuchElementException,而pollLast()方法返回null。
删除指定对象
remove(Object o): 删除指定元素:当删除指定对象时,只需调用remove(Object o)即可,不过该方法一次只会删除一个匹配的对象,如果删除了匹配对象,返回true,否则false。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;//得到后继节点
final Node<E> prev = x.prev;//得到前驱节点
//删除前驱指针
if (prev == null) {
first = next;//如果删除的节点是头节点,令头节点指向该节点的后继节点
} else {
prev.next = next;//将前驱节点的后继节点指向后继节点
x.prev = null;
}
//删除后继指针
if (next == null) {
last = prev;//如果删除的节点是尾节点,令尾节点指向该节点的前驱节点
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}删除指定位置元素
public E remove(int index) {
//检查index范围
checkElementIndex(index);
//将节点删除
return unlink(node(index));
}Arraylist 和 Vector 的区别?
ArrayList是List的主要实现类,底层使用Object[]存储,适用于频繁的查找工作,线程不安全 ;Vector是List的古老实现类,底层使用Object[]存储,线程安全的。
Arraylist 与 LinkedList 区别?
- 是否保证线程安全:
ArrayList和LinkedList都是不同步的,也就是不保证线程安全; - 底层数据结构:
Arraylist底层使用的是Object数组;LinkedList底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。) - 插入和删除是否受元素位置的影响: ①
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ②LinkedList采用链表存储,所以对于add(E e)方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置i插入和删除元素的话((add(int index, E element)) 时间复杂度近似为o(n))因为需要先移动到指定位置再插入。 - 是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 - 内存空间占用:
ArrayList的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
Q&A
问:为什么elementData为什么是transient
答:
transient用来表示一个域不是该对象序行化的一部分,当一个对象被序行化的时候,transient修饰的变量不会被序列化
ArrayList在序列化的时候会调用writeObject,直接将size和element写入ObjectOutputStream;反序列化时调用readObject,从ObjectInputStream获取size和element,再恢复到elementData。
为什么不直接用elementData来序列化,而采用上诉的方式来实现序列化呢?原因在于elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。















 1273
1273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









