






lscpu/cat cpuinfo:查看cpu信息
如何看当前Linux系统有几颗物理CPU和每颗CPU的核数?
查看物理cup:
cat /proc/cpuinfo|grep -c ‘physical id’
查看每颗cup核数
cat /proc/cpuinfo|grep -c ‘processor’
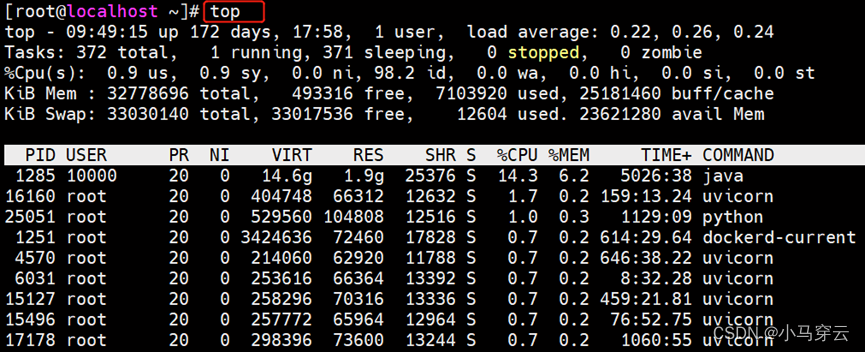
top:查看系统监控
VIRT:虚拟内存用量
RES:物理内存用量
SHR:共享内存用量
%MEM:内存用量
%CPU:cpu用量
根据 top 面板上显示的内容由上往下来看。
系统运行时间和平均负载
top - 14:49:00 up 157 days, 4:00, 2 users, load average: 0.00, 0.02, 0.05
当前时间;(14:49:00)
系统已运行天数和时间;(up 157 days, 4:00,)
当前登录的用户的数量;(2 users)
最近 5、 10 、15 分钟内的平均负载;(load average: 0.00, 0.02, 0.05)
load average 数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。 如果这个数除以逻辑CPU的数量,结果高于 5 的时候就表明系统在超负荷运转了。
任务
Tasks: 150 total, 1 running, 149 sleeping, 0 stopped, 0 zombie
进程总数;(150 total)
处于运行中的进程数;(1 running)
处于休眠中的进程数;(149 sleeping)
处于Stop中的进程数;(0 stopped)
处于Zombie的进程数;(0 zombie)
CPU状态
%Cpu(s): 0.1 us, 0.0 sy, 0.0 ni, 99.7 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 st
不同模式下所占 CPU 时间百分比:
运行(未调整优先级的)用户进程的CPU时间;(us)
运行内核进程的CPU时间;(sy)
运行已调整优先级的用户进程的CPU时间;(ni)
用于等待IO完成的CPU时间;(wa)
处理硬件中断的CPU时间;(hi)
处理软件中断的CPU时间;(si)
hypervisor消耗的CPU时间;(st)
这里 CPU 的使用比率和 Windows 概念不同,需要理解用户空间和内核空间,充充电!
内存使用
KiB Mem : 16265628 total, 942008 free, 7620156 used, 7703464 buff/cache
物理内存使用
全部可用内存;(16265628 total)
空闲内存;(942008 free)
已使用内存;(7620156 used)
缓冲区和缓存之和的内存;(7703464 buff/cache)
KiB Swap: 0 total, 0 free, 0 used. 8306592 avail Mem
虚拟内存使用(交换空间)
交换区总量;(0 total)
空闲交换区总量;(0 free)
使用的交换区总量;(0 used)
可以测量可以分配和使用的内存量,而不会导致更多的交换;(8306592 avail Mem)
不能用 Windows 的内存概念理解这些数据; 例:KiB Mem 中的 used (已使用内存)指的是现在系统内核控制的内存数,free(空闲内存总量)是内核还未纳入其管控的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交换到 free 中去,因此在 liunx 上 free 内存会越来越少,但不用为此担心。 出于习惯去计算可用内存数,有一个近视计算公式:free + buff/cached = 可用内存
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
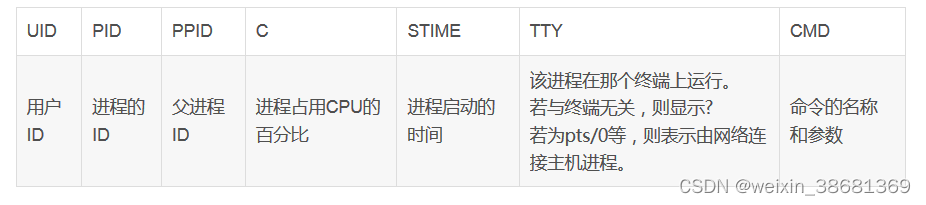
原文链接:https://blog.csdn.net/weixin_39783915/article/details/113325104进程ID;(PID)
进程所有者用户名;(USER)
进程调度优先级,RT 以为进程运行在实时态;(PR)
进程的Nice值,也就是优先级,值越小代表优先级越高;(NI)
进程使用的虚拟内存;(VIRT)
进程使用的、未被换出的物理内存大小;(RES)
进程使用的共享内存;(SHR)
进程的状态;(S) D-不可中断的睡眠态;R-运行态;S-睡眠态;T-被跟踪或已停止;Z-僵尸态;
进程从上次更新到现在所使用的CPU时间百分比;(%CPU)
进程使用的可用物理内存百分比;(%MEM)
进程启动后到现在所使用的全部CPU时间;(TIME+)
进程所使用的命令,进程名称;(COMMAND)
交互命令
‘h’ 帮助
可以用 'h' 或者 '?' 显示交互命令的帮助菜单
'e' 调整数据显示
默认 top 是以 KB 方式展示,按 'e' 可以调整为 mb 或 gb
'E' 调整数据显示
默认 top 是以 KB 方式展示,按 'E' 可以调整为 mb 或 gb
‘ENTER’ 或 ‘SPACE’ 刷新显示
top命令默认在一个特定间隔(3s)后刷新显示,或者用户手动刷新。
‘X’ 打开/关闭排序列的加亮效果
top 默认的排序列是 %CPU
'shift + >' 或 'shift + <' 向左或向右改变排序列
现在改为 %MEM 来排序
多核CPU监控
在 top 视图中,按数字 1 ,可监控每个逻辑 CPU 的状况。
调节出top命令默认没有显示的字段
在 top 命令页面下,按 f ,出现如下图的字段调节页面,上面有 * 标识的代表为显示的字段。
例如我们现在要将 DATA 标为显示列:
选中 DATA 按下空格,则代表需要显示,可以看到 DATA 也带 * 了;
按下 → 锁定 DATA,此时可以将 DATA 进行移动,我们需要把 DATA 移动到 COMMAND 以上才会显示到 top 面板;
3.此时退出,按下 esc,在面板即可看到 DATA;
top -H -p PID显示进程下线程
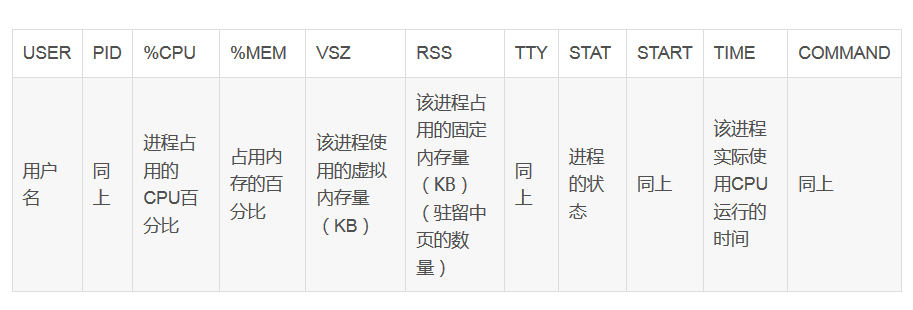
ps:查看进程
ps aux 或者ps –ef命令。ps aux最初用到Unix Style中,而ps -ef被用在System V Style中
- -a: 显示所有用户的进程
- -u: 显示用户名和启动时间
- -x: 显示没有控制终端的进程
- -e: 显示所有进程,包括没有控制终端的进程
- -l: 长格式显示
- -w: 宽行显示,可以使用多个`w`进行加宽显示
- -f: 做一个更完整的输出。
- -T显示线程


其中STAT状态位常见的状态字符有
D //无法中断的休眠状态(通常 IO 的进程);
R //正在运行可中在队列中可过行的;
S //处于休眠状态;
T //停止或被追踪;
W //进入内存交换 (从内核2.6开始无效);
X //死掉的进程 (基本很少见);
Z //僵尸进程;
< //优先级高的进程
N //优先级较低的进程
L //有些页被锁进内存;
s //进程的领导者(在它之下有子进程);
l //多线程,克隆线程(使用 CLONE_THREAD, 类似 NPTL pthreads);
+ //位于后台的进程组;
lsof
lsof可以列出打开了的文件

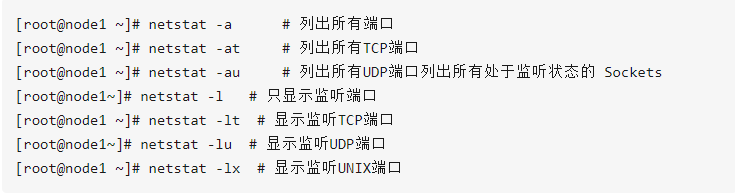
netstat -anp:查看端口占用/网络连接情况
-a all 显示所有连接的socket,默认不显示LISTEN
-t tcp 显示TCP传输协议的连接状况
-u udp 显示UDP传输协议的连接状况
-n numeric 直接使用IP地址,而不是通过域名解析器
-l listen 仅列出正在监听的服务状态
-p programs 显示进程名和进程号
netstat -lnp | grep 3306 :查看3306端口被谁占用
netstat -lnp | grep mysql :查看mysql服务占用了哪个端口

修改网卡信息
使用vi或者vim编辑器编辑网卡配置文件/etc/sysconfig/network-scripts/ifcft-eth0(如果是eth1文件名为ifcft-eth1),内容如下:
DEVICE=eth0
HWADDR=00:0C:29:06:37:BA
TYPE=Ethernet
UUID=0eea1820-1fe8-4a80-a6f0-39b3d314f8da
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.140.130
NETMASK=255.255.255.0
GATEWAY=192.168.140.2
DNS1=192.168.140.2
DNS2=8.8.8.8
修改网卡后,可以使用命令重启网卡:ifdown eth0
ifup eth0
也可以重启网络服务:service network restart
网卡绑定多ip:
cp /etc/sysconfig/network-scripts/ifcfg-eth0 /etc/sysconfig/network-scripts/ifcfg-eth0:1
修改
IPADDR=new ip
然后
service network restart
linux三剑客——grep
常用参数:
-c或–count 计算符合范本样式的列数。
-C<显示列数>或–context=<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-e<范本样式>或–regexp=<范本样式> 指定字符串做为查找文件内容的范本样式。
-A<显示列数>或–after-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之后的内容。
-B<显示列数>或–before-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前的内容。
-i或–ignore-case 忽略字符大小写的差别。
-v或–revert-match 反转查找。
-q或–quiet或–silent 不显示任何信息。
-n或–line-number 在显示符合范本样式的那一列之前,标示出该列的列数编号。
linux三剑客——sed
sed 命令是利用脚本来处理文本文件。sed 可依照脚本的指令来处理、编辑文本文件。sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。当然我个人用的最多的是增删改。
参数:
-n 使用安静模式,在一般情况所有的 STDIN 都会输出到屏幕上,加入-n 后只打印被 sed 特殊处理的行
-e 多重编辑,且命令顺序会影响结果
-f 指定一个 sed 脚本文件到命令行执行,
-r Sed 使用扩展正则
-i 直接修改文档读取的内容,不在屏幕上输出
操作:
sed 操作命令告诉 sed 如何处理由地址指定的各输入行。如果没有指定地址,sed 就会处理输入的所有的行
x:指定行号。
x,y:指定从x到y的行号范围
/ pattern/:查询包含模式的行 # # % %
/ pattern/ pattern/:查询包含两个模式的行
/ pattern/,x:从与 pattern的匹配行到x号行之间的行
x,/ pattern/:从x号行到与 pattern的匹配行之间的行
x,y!:查询不包括x和y行号的行
r:从另一个文件中读文件
w:将文本写入到一个文件
y:变换字符
q:第一个模式匹配完成后退出
l:显示与八进制ASCⅡ码等价的控制字符
{}:在定位行执行的命令组
p:打印匹配行
=:打印文件行号。
a:在定位行号之后追加文本信息
i:在定位行号之前插入文本信息。
d:删除定位行
c:用新文本替换定位文本
s:使用替换模式替换相应模式
n:读取下一个输入行,用下一个命令处理新的行
N:将当前读入行的下一行读取到当前的模式空间。
h:将模式缓冲区的文本复制到保持缓冲区
H:将模式缓冲区的文本追加到保持缓冲区
x:互换模式缓冲区和保持缓冲区的内容
g:将保持缓冲区的内容复制到模式缓冲区
G:将保持缓冲区的内容追加到模式缓冲区。
1、打印出文件第二行
2、打印出2-5行的内容
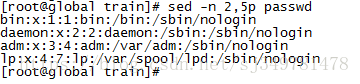
3、将文件中的root全部替换为abc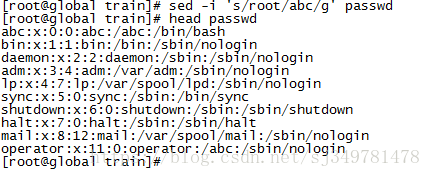
删除文件file.txt的第5行可以使用命令:sed '5d' file.txt
删除包含"abc"的行可以使用命令:sed '/abc/d' file.txt
在第5行之后插入一行内容为"Hello, World":sed '5a\Hello, World' file.txt
在以"abc"开头的行之前插入一行内容为"Insert":sed '/^abc/i\Insert' file.txt
在以"abc"开头的行之后插入一行内容为"Insert":sed '/^abc/a\Insert' file.txt
linux三剑客——awk(老大)
awk 是一种处理文本文件的语言,是一个强大的文本分析工具。之所以叫 awk是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
参数
-F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
-v var=value or --asign var=value
赋值一个用户定义变量。
-f scripfile or --file scriptfile
从脚本文件中读取awk命令。
-mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
-W compact or --compat, -W traditional or --traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
-W copyleft or --copyleft, -W copyright or --copyright
打印简短的版权信息。
-W help or --help, -W usage or --usage
打印全部awk选项和每个选项的简短说明。
-W lint or --lint
打印不能向传统unix平台移植的结构的警告。
-W lint-old or --lint-old
打印关于不能向传统unix平台移植的结构的警告。
-W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符和=不能代替和=;fflush无效。
-W re-interval or --re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
-W source program-text or --source program-text
使用program-text作为源代码,可与-f命令混用。
-W version or --version
打印bug报告信息的版本。
使用:
awk [-F分隔符] [-v 变量=值] ‘BEGIN { 初始化 } { 循环执行部分 } END { 结束处理 }’ file1 file2 ···
awk [-F|-f|-v] 大参数,-F指定分隔符,-f调用脚本,-v定义变量 var=value
’ ’ 引用代码块
BEGIN 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以是字符串或正则表达式
{} 命令代码块,包含一条或多条命令
; 多条命令使用分号分隔
$0 表示整个当前行
$1 每行第一个字段
NF 字段数量变量
NR 每行的记录号,多文件记录递增
F 指定分隔符
END 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
面试题:
shell脚本中awk应用,数组的定义使用_shell awk 数组-CSDN博客
一个文本有2列,从文本中找出所有请求IP,并统计每个IP的个数

扩展:
awk ‘{print $1}’ test.txt| sort | uniq -c |sort -rn | head -n 5
每个IP后面都有一个数字,将IP相同的第二列数字求和
cat test.txt |awk ‘{a[$1] += $2} END {for (i in a) print i, a[i]}’ >> sum.txt
对第1列:
- 求和:cat data|awk ‘{sum+=$1} END {print "Sum = ", sum}’
- 求平均:cat data|awk ‘{sum+=$1} END {print "Ave = ", sum/NR}’
- 求最大值:cat data|awk ‘BEGIN {max = 0} {if ($1>max) max=$1 fi} END {print “Max=”, max}’
- 求最小值:cat data|awk ‘BEGIN {min = 1999999} {if ($1<min) min=$1 fi} END {print “Min=”, min}’
求第M个字段前N:awk ‘{print $M}’ web_access.log|sort|uniq -c |sort -rn|head -N
假设:awk.log:
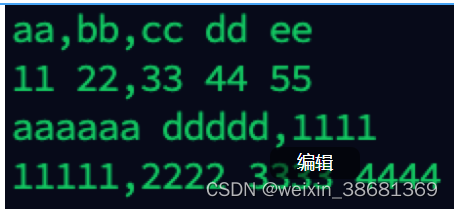
cat awk.log |awk 'BEGIN{size=0} {if($1==11) size++ } END{print size}',查找符合条件的数量。
返回1
netstat -an|awk '/^ TCP/ {++S[$NF]} END {for(a in S) print a,S[a]}',统计出tcp连接不同状态的数量。
free
显示内存状态
nslookup
- 查询DNS的记录,查看域名解析是否正常,在网络故障的时候用来诊断网络问题
系统信息
uname -m:显示机器的处理器架构
uname -r:显示正在使用的内核版本
dmidecode -q:显示硬件系统部件
cat /proc/cpuinfo:显示CPU info的信息
cat /proc/interrupts:显示中断
cat /proc/meminfo:显示内存使用情况
cat /proc/swaps:显示哪些swap被使用
cat /proc/version:显示内核的版本
cat /proc/net/dev:显示网络适配器及统计
cat /proc/mounts:显示已加载的文件系统
date:显示系统日期
用户和群组
groupadd group_name:创建一个新用户组
groupdel group_name:删除一个用户组
groupmod -n new_group_name old_group_name:重命名一个用户组
useradd -c "Name Surname " -g admin -d /home/user1 -s /bin/bash user1:创建一个属于 "admin" 用户组的用户
useradd user1:创建一个新用户
userdel -r user1:删除一个用户 ( "-r" 排除主目录)
usermod -c "User FTP" -g system -d /ftp/user1 -s /bin/nologin user1:修改用户属性
passwd:修改口令
passwd user1:修改一个用户的口令 (只允许root执行)
pwck:检查 "/etc/passwd" 的文件格式和语法修正以及存在的用户
grpck:检查 "/etc/passwd" 的文件格式和语法修正以及存在的群组
jps, stat, jstack,jmap:
https://www.cnblogs.com/chenpi/p/5377445.html
















 3036
3036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









