







摘要
本文总结了在Hadoop集群环境下,DataNode无法连接NameNode的问题:2017-02-13 05:43:01,540 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: hadoop-master-vm/10.220.33.37:9000,重点在于问题的排除思路和方法。该问题出现的运行环境为Debian 11-7, Hadoop 3.3.6环境下。
问题描述
按照博文 Hadoop-3.3.6 集群的配置教程 搭建Hadoop集群环境后,在master节点(hadoop01)运行 ./bin/hdfs dfsadmin -report 查看分布式文件系统信息时发现无法显示相关数据:
hadoop@hadoop01:/usr/local/hadoop-3.3.6$ cd /usr/local/hadoop-3.3.6
hadoop@hadoop01:/usr/local/hadoop-3.3.6$ ./bin/hdfs dfsadmin -report
2023-10-05 08:25:22,837 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Configured Capacity: 0 (0 B)
Present Capacity: 0 (0 B)
DFS Remaining: 0 (0 B)
DFS Used: 0 (0 B)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0-------------------------------------------------
登录http://hadoop01:9870后,DataNode列表显示为空。
排查思路
这里我们来总结一下此问题的排查思路
1. 遇到该类问题时,首先需要确认的是相关的服务进程是否已经启动起来,这里可以通过jps命令来查看。如果能够正常启动的话,在Master节点上,可以看到NameNode、ResourceManager、SecondaryNameNode、JobHisotryServer服务; 在Slave节点上可以看到DataNode和NodeManager服务。通过jps命令发现相关的服务都存在。
master节点:

slave01节点:
 2. 接下来看两个主机之间能否ping通
2. 接下来看两个主机之间能否ping通
master ping slave01节点:

slave01节点 ping master:

说明主机映射之间也没有问题。
3. 检查配置文件core-site.xml 和 hdfs-site.xml
如果配置文件也没有问题。继续第四步。
4. 接下来需要查看的就是系统日志。系统日志位于Hadoop安装目录的logs子目录下。我们查看其中一个DataNode的日志文件$INSTALL_HADOOP/logs/hadoop-hadoop-datanode-hadoop-.log,发现了下面的异常信息:
hadoop@hadoop02:~$ cd /usr/local/hadoop-3.3.6/
hadoop@hadoop02:/usr/local/hadoop-3.3.6$ cd logs/
hadoop@hadoop02:/usr/local/hadoop-3.3.6/logs$ ls -l
total 444
-rw-r--r-- 1 hadoop hadoop 282054 Oct 5 08:47 hadoop-hadoop-datanode-hadoop02.log
-rw-r--r-- 1 hadoop hadoop 818 Oct 5 08:24 hadoop-hadoop-datanode-hadoop02.out
-rw-r--r-- 1 hadoop hadoop 149507 Oct 5 08:44 hadoop-hadoop-nodemanager-hadoop02.log
-rw-r--r-- 1 hadoop hadoop 2949 Oct 5 08:24 hadoop-hadoop-nodemanager-hadoop02.out
-rw-r--r-- 1 hadoop hadoop 0 Oct 5 08:24 SecurityAuth-hadoop.audit
drwxr-xr-x 2 hadoop hadoop 4096 Oct 5 08:24 userlogs
hadoop@hadoop02:/usr/local/hadoop-3.3.6/logs$ tail -n 30 hadoop-hadoop-datanode-hadoop02.log2023-10-05 08:47:59,552 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: hadoop01/192.168.30.134:9000. Already tried 7 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
从日志上分析,DataNode(hadoop02)无法连接NameNode(hadoop01)。此时可去排查NameNode的问题。
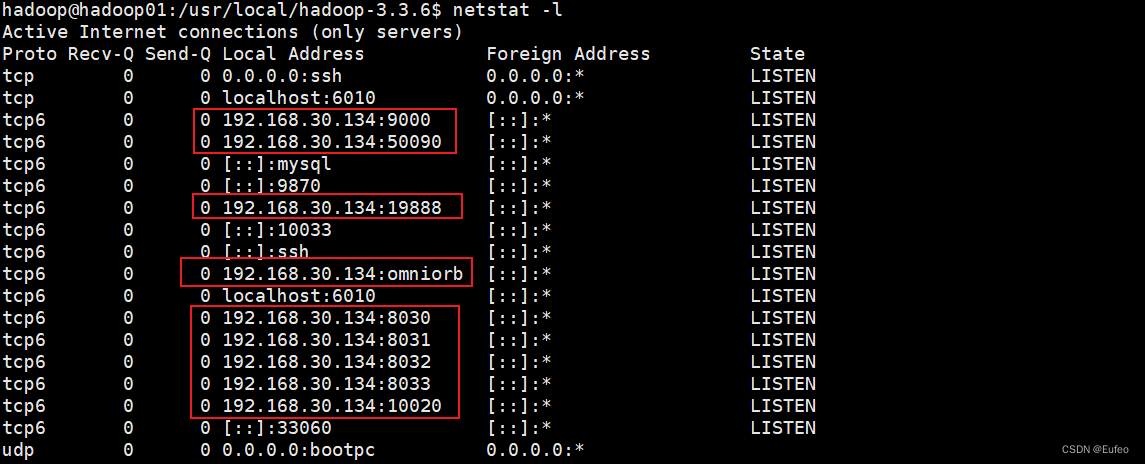
5. 在NameNode(master/hadoop01)上,使用netstat -l来查看端口信息,发现服务端口9000工作正常:
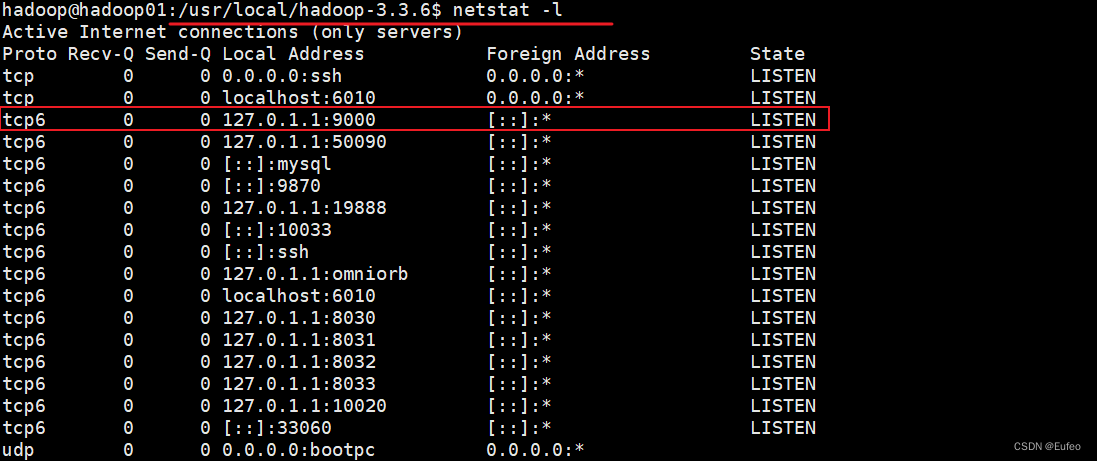
此时怀疑是否因为系统防火墙配置导致过滤了9000端口报文,尝试用sudo ufw allow 9000命令运行防火墙通过相关端口的报文,未果。重新审视了netstat -l的输出,发现10020和19888端口侦听地址比较奇怪,为127.0.1.1。但在mapred-site.xml配置文件中,我们是以hostname来配置的:
cd /usr/local/hadoop-3.3.6/etc/hadoop
cat mapred-site.xml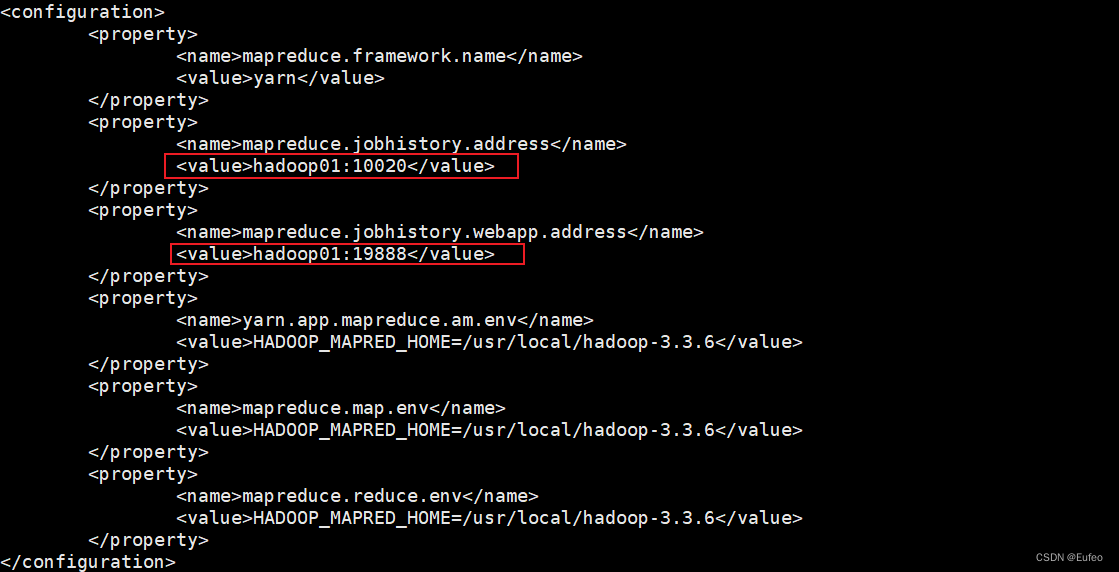
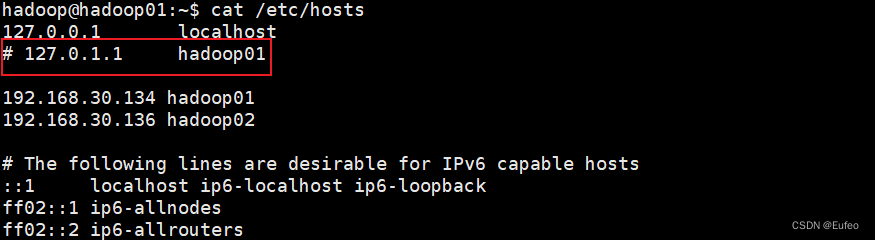
netstat -l显示的信息与mapred-site.xml配置冲突,我们实际上希望它应该监听hadoop01(即master)上来的数据,而非127.0.1.1。查看hadoop01的/etc/hosts文件,发现有127.0.1.1对应的域名:
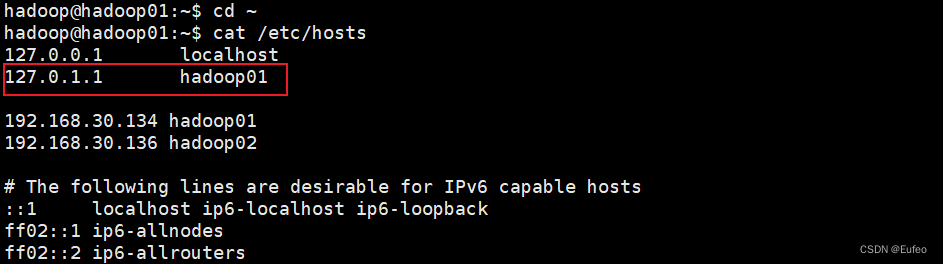
尝试注释掉127.0.1.1的域名,重新启动相关的服务后,重新查看端口侦听信息:
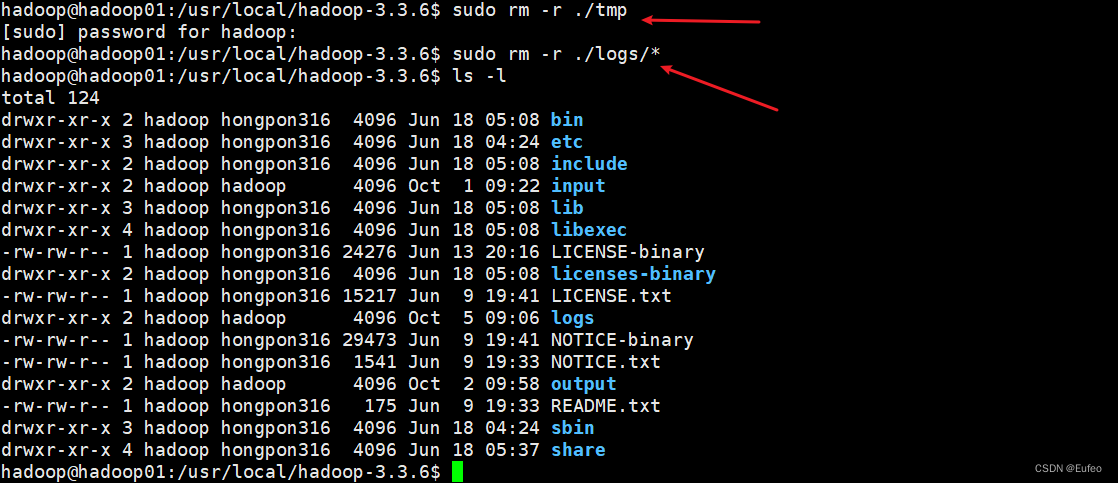
因为之前遇到的是无法正常启动的情况,可以删除所涉及节点的临时文件夹,这样虽然之前的数据会被删掉,但能保证集群正确启动。不妨试着删除所有节点(包括Slave节点)上的“/usr/local/hadoop-3.3.6/tmp”和“/usr/local/hadoop-3.3.6/logs/*” 文件夹,再重新执行一次“hdfs namenode -format”,再次启动即可。
在master节点上执行以下命令:
①先停止服务
cd /usr/local/hadoop-3.3.6/
./sbin/stop-dfs.sh
./sbin/stop-yarn.sh
./sbin/mr-jobhistory-daemon.sh stop historyserver
jps
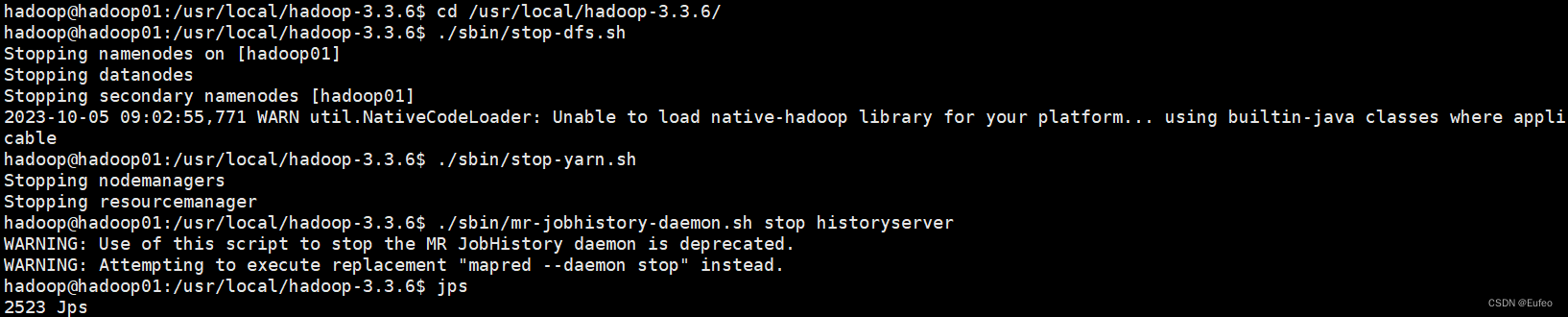
②删除相关的文件夹
sudo rm -r ./tmp
sudo rm -r ./logs/*
③ 注释掉hosts文件中的域名
cd ~
vim /etc/hosts
sudo vim /etc/hosts
在slave01节点执行以下命令:
①确认所有服务已关闭
jps
②删除相关文件
cd /usr/local/hadoop-3.3.6
sudo rm -r ./tmp
sudo rm -r ./logs/* 在hadoop01中(master节点)重新启动各项服务 。
现在已经与实际配置一致了,使用 ./bin/hdfs dfsadmin -report 命令查看,已经可以显示DataNode信息了。
hadoop@hadoop01:/usr/local/hadoop-3.3.6$ ./bin/hdfs dfsadmin -report
2023-10-05 09:16:24,818 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Configured Capacity: 19947929600 (18.58 GB)
Present Capacity: 13853442048 (12.90 GB)
DFS Remaining: 13853417472 (12.90 GB)
DFS Used: 24576 (24 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0-------------------------------------------------
Live datanodes (1):Name: 192.168.30.136:9866 (hadoop02)
Hostname: hadoop02
Decommission Status : Normal
Configured Capacity: 19947929600 (18.58 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 5055246336 (4.71 GB)
DFS Remaining: 13853417472 (12.90 GB)
DFS Used%: 0.00%
DFS Remaining%: 69.45%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Thu Oct 05 09:16:22 EDT 2023
Last Block Report: Thu Oct 05 09:15:01 EDT 2023
Num of Blocks: 0
问题总结
/etc/hosts文件配置错误导致了服务侦听地址错误,引起了NameNode和DataNode工作的异常。类似的问题,均可参考本文的排查思路来解决。
参考资料
如何解决Hadoop集群环境下DataNode无法连接NameNode问题_此 datanode 未连接到其一个或多个 namenode-CSDN博客

















 4153
4153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









