



 本文展示了Python借助百度飞桨进行深度学习的应用,包括批量抠图、情绪识别、人脸识别和口罩检测。此外,还介绍了OpenCV用于猫脸识别和字符画生成,以及如何快速搭建FTP服务器。通过这些实例,展现了Python在图像处理和自然语言处理领域的强大功能。
本文展示了Python借助百度飞桨进行深度学习的应用,包括批量抠图、情绪识别、人脸识别和口罩检测。此外,还介绍了OpenCV用于猫脸识别和字符画生成,以及如何快速搭建FTP服务器。通过这些实例,展现了Python在图像处理和自然语言处理领域的强大功能。

公众号后台回复“图书“,了解更多号主新书内容作者:周萝卜
来源:萝卜大杂烩
Python 凭借语法的易学性,代码的简洁性以及类库的丰富性,赢得了众多开发者的喜爱。下面我们来看看,用不超过10行代码能实现些什么有趣的功能
百度飞桨
百度飞桨 paddlepaddle 是百度开源的深度学习工具,其功能强大,基于该工具我们可以实现很既有趣又有用的功能
在使用之前,我们肯定要先安装喽
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install paddlehub -i https://mirror.baidu.com/pypi/simple安装完成后,我们来体验几个有趣的项目
批量抠图
批量获取指定目录下的图片,然后通过 paddlehub 训练好的模型进行批量抠图处理
import os
import paddlehub as hub
# 加载模型
humanseg = hub.Module(name='deeplabv3p_xception65_humanseg')
path = './heben/' # 文件目录
# 获取文件列表
files = [path + i for i in os.listdir(path)]
# 抠图
results = humanseg.segmentation(data={'image': files})
for result in results:
print(result)Output:
我们可以看到,经过处理之后的图片自动保存在目录 humanseg_output 下面
我们可以对比下处理前后图片的差异
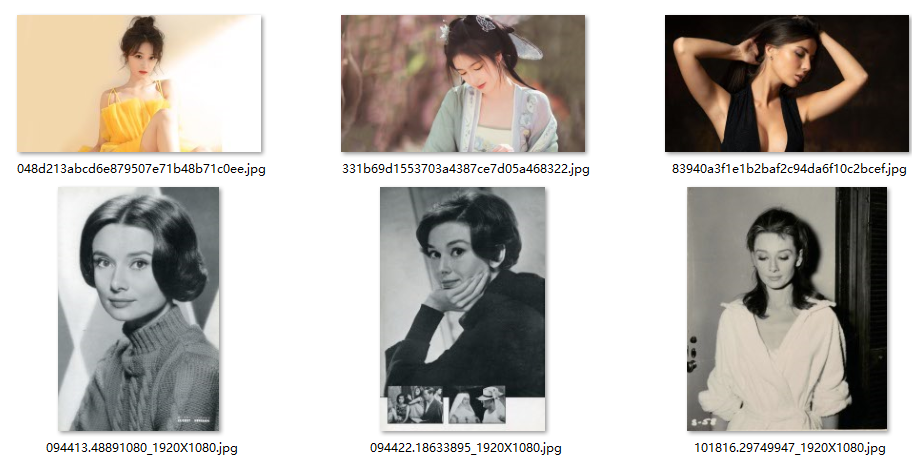
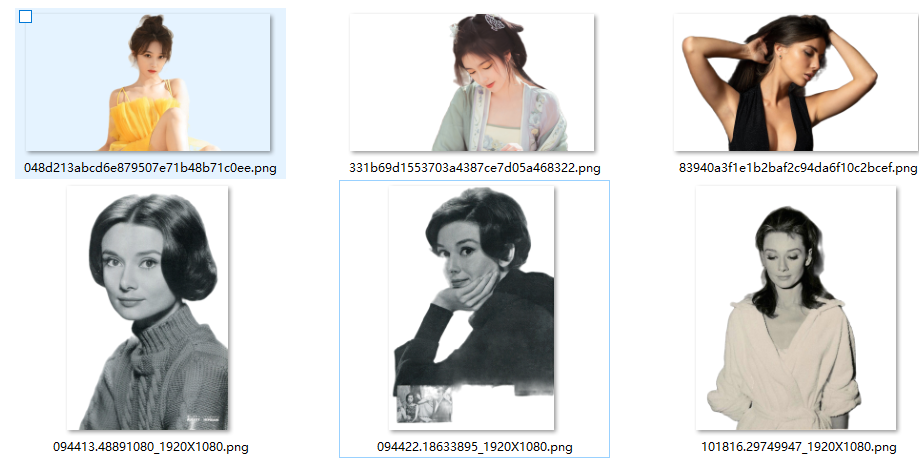
整体来看,抠图效果还是非常棒的!
注意:如果执行代码没有生成对应的 out 文件夹,可以重新手动安装模型再尝试
hub install deeplabv3p_xception65_humanseg==1.0.0自然语言处理
飞桨同样有很强的自然语言处理能力,在处理文字情绪识别方面也非常突出
senta = hub.Module(name='senta_lstm') # 加载模型
sentence = [ # 准备要识别的语句
'你好漂亮', '你真难看呀', '他好难过', '我不开心', '这是一款什么游戏,真垃圾', '这个游戏太好玩了',
]
results = senta.sentiment_classify(data={'text':sentence}) # 情绪识别
# 输出识别结果
for result in results:
print(result)Output:
可以看出,文字情绪的识别还是非常准确的,当然我们这里语料比较少,在大语料、更复杂的语言环境下,飞浆的表现如何还有待验证
人脸识别
当今社会人脸识别可以说是随处可见,而在疫情肆虐的今天,口罩似乎也成为我们日常出现必备的条件,飞浆工具也增加了口罩识别功能,我们来看看
# 加载模型
module = hub.Module(name='pyramidbox_lite_mobile_mask')
# 图片列表
image_list = ['face2.jpg']
# 获取图片字典
input_dict = {'image':image_list}
# 检测是否带了口罩
module.face_detection(data=input_dict)face.jpg 如下
Output:
[{'data': [{'label': 'NO MASK',
'confidence': 0.9995137453079224,
'top': 478,
'bottom': 775,
'left': 1894,
'right': 2126},
{'label': 'NO MASK',
'confidence': 0.9903278946876526,
'top': 512,
'bottom': 810,
'left': 1754,
'right': 1998},
{'label': 'NO MASK',
'confidence': 0.9997405409812927,
'top': 697,
'bottom': 985,
'left': 1857,
'right': 2131},
{'label': 'NO MASK',
'confidence': 0.943692147731781,
'top': 575,
'bottom': 888,
'left': 1954,
'right': 2216}],
'path': 'face2.jpg'}]可以看出,已经判断出超过99%的概率,该张图片是没有佩戴口罩的
人脸关键点检测
人脸关键点检测是人脸识别和分析领域中的关键一步,它是诸如自动人脸识别、表情分析、三维人脸重建及三维动画等其它人脸相关问题的前提和突破口
我们以如下这张图片作为待检测图片
代码如下
face_landmark = hub.Module(name="face_landmark_localization")
image = 'face.jpg'
result = face_landmark.keypoint_detection(images=[cv2.imread(image)],visualization=True)
print(result)Output:
可以看到人脸关键点已经标注出来,并且把检测后的图片自动存储在 face_landmark_output 目录下
OpenCV
OpenCV 作为最为著名的计算机视觉工具,基于它我们也可以做很多有趣的事情 首先我们安装好 OpenCV 库
pip install opencv-python猫脸识别
在当今社会,谁还没有一个两个猫主子呢,高冷的猫咪往往会得到人们特殊的爱戴!
我们也习惯了人脸识别,今天就通过几行代码来看看猫脸识别是怎么的呢
首先我们到安装目录下提取锚链识别 XML 分类器,具体目录如下
C:\Python3\Lib\site-packages\cv2\data
可以看到有如下很多分类器
我们复制 haarcascade_frontalcatface.xml 到自己的项目下即可
# 待检测的图片路径
ImagePath = './cat/cat.jpg'
# 读取图片
image = cv2.imread(ImagePath)
# 把图片转换为灰度模式
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 探测图片中的猫脸
# 获取训练好的猫脸的参数数据,进行猫脸检测
face_cascade = cv2.CascadeClassifier(r'./haarcascade_frontalcatface.xml')
faces = face_cascade.detectMultiScale(gray,scaleFactor=1.15,minNeighbors=5,minSize=(3, 3))
search_info = "Find %d face."%len(faces) if len(faces) <= 1 else "Find %d faces."%len(faces)
# 绘制猫脸的矩形区域(红色边框)
for (x, y, w, h) in faces:
cv2.rectangle(image, (x,y), (x+w,y+h), (0,0,255), 2)
# 显示图片
# cv2.imshow('Find faces!', image)
# cv2.waitKey(0)
cv2.imwrite("./cat/cat2.jpg", image)Output:
获取摄像头人脸
我们编写一个获取实时动态视频流的代码,实时获取当中的人脸信息
detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
cap = cv2.VideoCapture(0)
while True:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.imshow('frame', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()注意这里使用的分类器是 haarcascade_frontalface_default.xml,可不要用错哦
Output:
自行在自己的电脑上尝试下哦~
快速生成动图
在很多时候,尤其是在线聊天时,输了什么也不能输掉斗图啊,下面的代码可以快速生成动图,在和朋友的斗图当中,得胜的把握又增加了
import imageio
image_list = ['image/1.jpg','image/2.jpg', 'image/3.jpg', 'image/4.jpg']
gif_name = "dongtu.gif"
duration = 1
frames = []
for image_name in image_list:
frames.append(imageio.imread(image_name))
imageio.mimsave(gif_name, frames, "GIF", duration=duration)Output:
扫一下有惊喜~
ftp 服务器
可能很多人不知道,通过 Python 几行简单代码,我们可以快速实现一个简易的 ftp 服务器,这样在局域网内进行文件传输不再发愁啦!
代码非常简单,直接运行 Python 自带的 http 服务器即可
python -m http.server 8090Output:
接下来我们访问本地 IP + 端口8090
很强大,很简单,很好用!
字符画
字符画是一系列字符的组合,我们可以把字符看作是比较大块的像素,一个字符能表现一种颜色,字符的种类越多,可以表现的颜色也越多,图片也会更有层次感
我们只需要短短几行代码,就可以完成字符画的制作
我们使用的图片如下
代码如下
IMG = "3.jpg"
WIDTH = 80
HEIGHT = 40
OUTPUT = "./ascii/ascii.txt"
ascii_char = list("$@B%8&WM#*oahkbdpqwmZO0QLCJUYXzcvunxrjft/\|()1{}[]?-_+~<>i!lI;:,\"^`'. ")
# 将256灰度映射到70个字符上
def get_char(r,g,b,alpha = 256):
if alpha == 0:
return ' '
length = len(ascii_char)
gray = int(0.2126 * r + 0.7152 * g + 0.0722 * b)
unit = (256.0 + 1)/length
return ascii_char[int(gray/unit)]
im = Image.open(IMG)
im = im.resize((WIDTH,HEIGHT), Image.NEAREST)
txt = ""
for i in range(HEIGHT):
for j in range(WIDTH):
txt += get_char(*im.getpixel((j,i)))
txt += '\n'
print(txt)
#字符画输出到文件
with open(OUTPUT,'w') as f:
f.write(txt)Output:
◆ ◆ ◆ ◆ ◆
麟哥新书已经在当当上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前当当正在举行活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









