






最近工作需要研究用户成长体系,于是在读了网上数十篇相关的文章后,决定梳理一份自己的理解和笔记。
▍What is 用户成长体系?产品经理对于有关积分、成长值、等级等一整套的系统,有人叫用户成长体系,有人叫用户激励系统。笔者的理解是,他们都是一样的,不用纠结于字眼,关键还在于内涵的研究。
关于用户激励(或成长,下文统一用成长),其实说白了就是让用户“自愿”做产品想要他们做的事情,对产品的关键词是「促活」和「留存」。好的用户成长体系不论对于用户还是平台来说,都是双赢的结果。而没有价值的用户成长体系对于用户来说就是一个累赘,往往适得其反。
这里简单介绍一下HOOKED模型,他的理论是来源于对游戏机制的研究。
HOOKED模型这张图中间有八个关键词,分别代表了八个不同的核心驱动力。
核心驱动力 1: 史诗意义&使命感:做比自己更重要的事情!
核心驱动力 2: 发展&成就:取得进步、获得成就
核心驱动力 3: 创造力的发挥&反馈:创造、即时反馈!
核心驱动力 4: 拥有感&占有感:集换式游戏、养成类游戏
核心驱动力 5: 社交影响&联系:炫耀、竞争、合作……
核心驱动力 6: 稀有&无耐性:得不到的永远在骚动!
核心驱动力 7: 未知&好奇:好奇心害死猫和老鼠!
核心驱动力 8: 失去&避免:恐惧、害怕失去、一切负面情绪
所以说,用户成长体系是一个产品游戏化的体现,动机(M)对应我们的出口,触发器(T)可对应我们的入口。游戏化其实是Human-Focused Design,在设计的过程中最大化考虑情感、动机等人类心理因素。无论什么产品,再厉害的功能,如果用户压根不想用,那么就是失败的。勋章、小红花、奖状、奖杯、腰带这些玩意,实际上是“成就象征”,它本身并没有任何意义,但是它代表的是人们历经千辛万苦、突破重重挑战后的成就感!所以说游戏是什么实质功能都没有的(所谓的“浪费时间”),但却拥有让人们投入大量时间和精力的魔力。
在HOOKED模型中包含了另外一个模型,即B.J Fogg的行为模型(BJ Fogg's Behavior Model):B= MAT——行为=动机*能力*诱因(或者叫触发器)。任何行为的发生都要依靠于上述公式的三个变量。
这一套理论的核心在于“A”(Ability)和“T”(Trigger),通过简化完成某一行为的流程、适时的提醒用户,让用户顺利地做出期望行动(Desired Action)。最终使这一行为固化为「习惯」 ,也就是让用户不需要怎么思考就自然地使用你的产品或者服务(期望发生的行为)。
总结,用户成长体系是对产品的一整套「系统」 的「循环」 的「运营手段」 和「产品机制」 的结合。
▍用户成长体系的设计原则
并不是所有产品都适合,或者都需要设计用户成长体系的。面对需求非常强烈,你不需要激励用户,他们都会投欢送抱的产品,就不需要画蛇添足。譬如微信的即时通讯(聊天)功能,它的功能就十分简单,8亿用户依然没有犹豫地选择用它。
还有一种不适合做用户成长体系的产品,就是低频产品,譬如婚庆、丧礼、毕业典礼相关的服务和商品,一生只有一次或几年才有一次使用场景的东西,你非要鼓励用户去多用,就不太懂人情了吧。
所以,高频的需求、强度没那么大的需求,更适合使用用户成长体系。
而设计一个用户成长体系也需要注意很多地方,做不好,同样容易让用户反感,甚至把自己的产品逼到悬崖。整理归纳为以下4个“需要”和5个“可被”:
1、体系应需要体现平台核心业务特色:其中的元素和机制应该尽量体现独特性,而不是套哪都能用的东西。
2、体系投入产出需要平衡:预防投入过大的成本,只获取微薄的收益,或没有经过精细计算的成长机制,是不把企业逼向死亡的重要一环。
3、经验体系需要分离:一个公司内不同的业务体系之间的成长体系和货币体系要分离开来,不同业务体系拥有不同的成长体系,可以更加灵活不受限制,运营起来更加方便。
4、用户需要分类:不同用户使用不同方式激励,可把用户分为新用户、普通用户、活跃用户、核心用户等。
5、体系可被拓展:假如等级较少,用户容易满级,这个体系就是去原有的价值和作用了。用适当的方式,实现体系的可持续发展,是一个决定体系优劣的重要因素。
6、门槛可被进入:入门门槛太高,难度太大,容易失去激励用户的意义,开始的第一步尤其要注意不要让用户望而生畏。
7、激励可被感知:不能骚扰用户,但是也不能一点都不通知用户,适时地强调用户成长体系的存在感,体现不同的差异化和可展现性,用户才有动力去玩。
8、等级可被期待:用机制和玩法保持稀缺感,同时可考虑增加降级或下限机制:如连续12个月不发言将销号、未完成任务降级等。
9、“刷假”可被预防:包括每日任务只能做多少次,特定行为只计算第一次有效,重复同样内容不计数等,也是有效保证体系稀缺感的做法。
▍简述设计用户成长体系的步骤
一个完整的用户成长体系的模块包括「入口」 、「成长形式」 、「计算方法」 和「出口」 。下面快速说说整体的设计过程是怎样的,然后在下文中再单独讲述其中的细节。
1、定义产品的业务指标;
2、按照产品业务特点,把用户分类/建模;
3、规划用户最佳路径,确定我们期望用户做什么行为,从什么类型的用户变成什么类型的用户,过程中用户的理想操作和路径是怎样的;
4、根据运营目标定义每一个行为的权重,选择适合的成长形式;
5、根据上一步计算行为获得的成长值(或其他形式),计算每日获得成长值的上限;
6、设定每个等级的升级时长和整体的升级计算方法,指数函数、幂函数或斐波拉契数列等,划分每个等级所需要的成长值;
8、制定成长体系每个入口的出口,使用户行为形成闭环,包括设计等级或其他所需要的勋章和称号等,规划展示位置。
▍如何选择入口(目标确立)
定义:这里说的入口是指可以获得成长值/积分/虚拟货币等的方式。一个APP里的用户行为有很多,我们又可以按什么方法来选择可以作为入口的用户行为呢?
1、目的划分:
这是最基本最简单的划分和选择方法,对应运营的四个基础目标,不作详细解释。
1)拉新
2)留存
3)活跃
4)流失用户挽回
2、用户分级(建模):
为不同的用户设计不同的入口和出口,有针对性地设计才能更有效果。且用户行为应该是能形成「闭环」 的,用户成长体系应根据不用用户的使用习惯和目的,围绕他们的行为提供更多激励点,促进它们形成闭环。
我们常用的划分维度:
行为特征:用户进行的某种行为,如活跃度、使用时间、时长、某种特定的操作之类的
身份特征:基于用户本身自带的属性,如性别、地区、学历、城市维度、婚育情况等等
渠道属性:基于用户来源来判定的属性,常见的渠道有;百度、地推、移动广告等等
敏感度属性:基于用户心理的一种属性判断,如价格敏感型,服务敏感型等等
以一个在线多人K歌软件为例,加强大家的理解。
1)大牛用户:唱歌为主,寻求自我实现
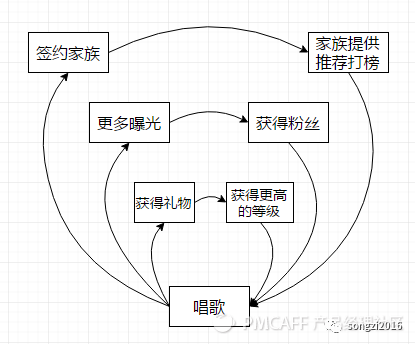
2)抱团用户:组建家族,希望获得小团体里的认可
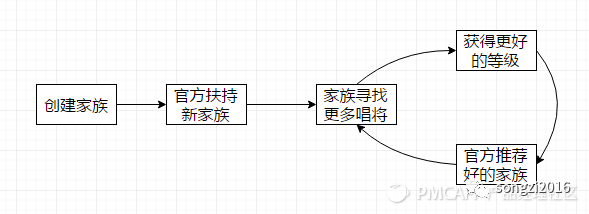
3)朋友团用户:线下用户的朋友群打破地域限制,共同娱乐
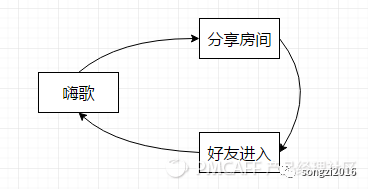
4)自娱自乐型用户:唱歌练歌为主,顺便拓宽陌生人人脉
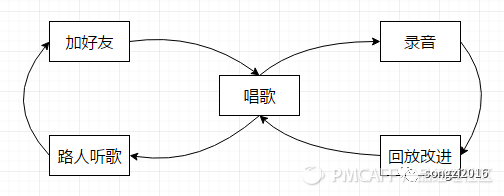
3、按照行为划分:
1)主动行为:指用户主动对产品进行的行为,如分享个人主页、发帖等,以提高用户活跃为主,量的维度
2)被动行为:指用户做出主动行为后,其他人对其的认可行为,如点赞、转发等,以保证用户活跃的质量,而非滥竽充数,质的维度
▍规整选择好的入口和权重
确定了需要哪些入口后,我们通常还会给它们分类,为不同的入口确定不同的使用频率。目的是为了制造多样的玩法和机制,保证用户成长体系不会太容易被玩腻,同时引导不同的用户能尽量围绕适合他们的核心行为来玩。
1、新手任务
针对新用户使用,门槛低, 具有教育和引导意义。常见的入口有注册、完善个人信息、首次完成某个用户行为。
2、日常任务
主要作用于提高DAU,鼓励用户打开你的APP,是让他使用产品的第一步。常见的形式有签到、某些主线任务的第一次完成。日常任务和主线任务可能会有重复,它关注的点在于当天第一次完成,奖励方式会有些不同。
3、主线任务
就是为了让用户做出你最想他做的行为的那些任务咯,每个产品的核心功能和价值点都不一样,因产品而异。而主线任务应该是奖励最多,可执行限制最少,权重最大的任务。常见的主线任务有直播(直播平台)、上传作品(K歌软件)、阅读(读书工具)、运动(健身平台),等等。
4、非固定收益
顾名思义,不是固定周期出现的任务收益,多数是一些带给用户惊喜和额外鼓励的东西。其中包括获取粉丝额外奖励、运营活动奖励、其他用户的打赏,还有游戏中常见的捡宝箱。
▍常见的成长形式
成长形式,是指通过入口获得奖励或用户成长的呈现方式和规则。不同的产品,适用的成长形式不一样,花样也多。平时日常中常见的,笔者整理了一下,就已经有13种了。下面简单罗列一下各自的特点,都很好理解,不配图了,免得增加长文负担。
1、关系量/粉丝量:体现用户的影响力和话语权/地位
2、身份认证:相对理性和严肃的产品所需要的认证,包括实名认证、企业认证、资产水平
3、特征认证:多为官方审核提供的,包括V认证、达人认证等
4、勋章/头衔:可通过一些特定用户行为、站内运营活动、外部广告推广等自主获得的称号
5、VIP会员:可试用的,具有有效期,有多种时长套餐,本质是一种增值服务(IVAS),目的是鼓励用户付费
6、魅力值/经验值:各种业务相关的有针对性的分值
7、成长值:综合性的分值,不具消耗性,可和等级一起定期回收,电商中的RFM模型就是常见的这类型成长体系
8、积分:可被消费,可设置有效时间,可被看作是一种特殊的支付货币
9、虚拟货币:可被消费,没有时效性
10、虚拟道具:类似于一种特权的作用,也作为送礼用,具有交换二次售卖的属性
11、排行榜:上榜可设置奖励
12、等级:由积分等数值划分,可具有有效期
13、系列任务:把多个简单任务打包成一个大任务,可获得勋章、称号、纪念卡等
▍用户成长的计算依据
设置一套合理的计算方式是为了使等级之间划分出差距和界限。好的计算依据可以让一套成长等级拥有良好的差异性和稀缺性。因为笔者非科班出身,避免班门弄斧,所以引用了Jinkey原文中的这一部分,欢迎大家看原文《史上最全用户成长体系分析,附6大案例》。
1、幂函数
幂函数一般用于等级较多的平台,如马蜂窝和Pokemon Go。
有较大的互动空间、成长值获取的口径非常宽泛、容易成长的平台,适宜配置较多的等级。所以网游一般等级都非常多,因为里面打怪、日常任务、活动、副本、升级加成、装备锻造、生活技能、生育系统、竞技等超多玩法都可以获得成长值。成长体系主要为了DAU 而非 GMV,可以考虑设置更多的等级和配置更大的互动空间。
例子:Pokemon Go 的成长体系,对其总经验值进行回归后得到下图的公式
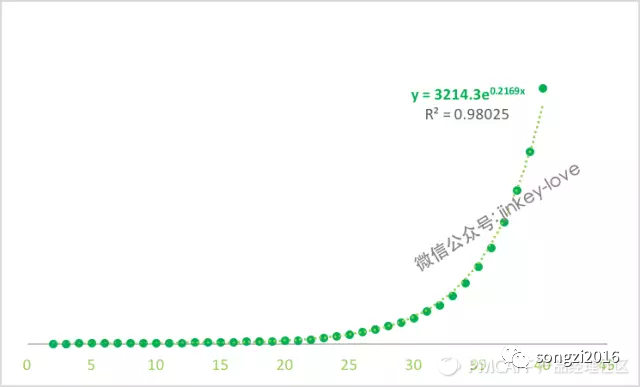
2、指数函数
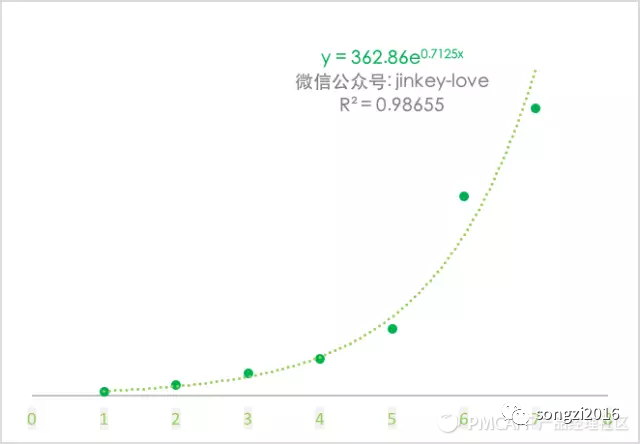
斐波拉奇数列指数函数一般用于等级较少的平台,如京东会员、天猫会员等电商平台和垂直类的平台如网易云音乐。电商平台和某些平台除了购买、评论、点赞、登录之外,没有太多的互动空间,相应获得成长值的途径就少(也不排除产品经理太懒了..233333….)。所以如果你的平台互动少,成长体系主要为了 GMV 而非 DAU,可以考虑设置较少等级。
例子:QQ 会员的成长体系,对其总经验值进行回归后得到下图的公式。
3、其他分段函数
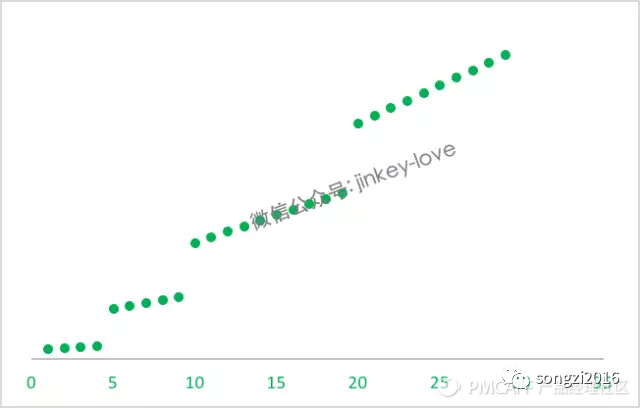
分段线性函数的成长比较缓和,升级难度较低。一般可用于等级对于平台不是太重要的情况。下图是LOL的等级分布情况,英雄联盟的召唤师等级其实并没什么用,主要还是看玩家的操作水平,因为LOL 有非常好的队伍匹配系统,很少说你一个1级的召唤师给你匹配一个最强王者的对手。
4、计算方式
依据用户历史数据,加权平均得到用户每天可以得到的经验上限 A,设定的等级数量 B,该体系可持续时长 C。按照指数函数或者幂函数(自定义系数项)计算每个等级的比例,将可持续时长C 按比例分配到每个等级,算出来看看数值会不会太离谱,比如升级需要10000天。腾讯发展到现在也才差不多19年,你一个等级需要花费用户27年谁玩……
确定每个等级所需要的天数 Dn 大概合理之后,用 A * Dn 得到第 n 个等级所需要的升级经验,如果希望得到每个等级需要的总经验,可以将前 n-1 个等级的经验求和。
以 QQ 会员为例,由于不知道 QQ 不同付费方式的用户比例,这里举例就暂且用最高和最低取平均值计算:

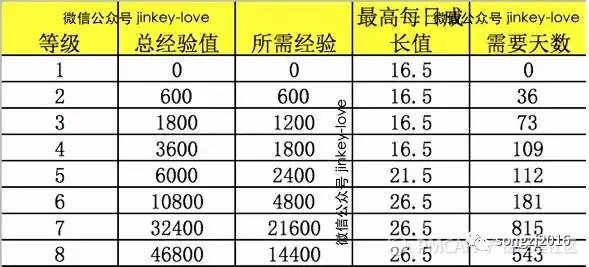
测算证明,你用的是什么函数计算,算出的所需天数、总经验、每个等级经验都基本符合所用的函数。
▍等级划分注意事项
任何成长形式的分、值,都会设定自己的等级,等级无处不在。于是等级的划分和设定尤其重要,用户成长体系中的多个原则其实也都是围绕等级来的。因此,这里着重把等级划分的注意事项再次列出来,提高大家的重视。
1、等级之间的概念最好是有关联系的,容易理解的;
2、等级的概念应该是易懂的;
3、等级的设计应该有较好的扩容性,当用户大量爆发时,等级可以很好地增加更多等级和玩法。当最高等级的用户数接近第二高等级的用户数时就要推出新等级,因为这意味着最高等级的用户开始丧失尊贵感;
4、此外,设计等级要同时从用户和运营角度考虑,实现等级的合理分布。不能让很多用户很快就能达到下一个等级,否则该等级的运营空间就会很小;
5、等级划分应该具有标杆性和稀缺性。越高的等级,应该越难获得,表示该等级的尊贵性;
6、设计降级制度,保证每个等级的质量,提高稀缺性;
7、等级之间的出口应该具有较强的差异性。
▍重新整理出口的5种分类
定义:这里说的出口是指通过获得的成长值/积分/虚拟货币等,用户可以兑换给自己的实物奖励或服务。在探索多种不同产品中的出口时,同样发现了和成长形式一样的问题,即多样性和不可同一性。所以,在列出了所见到过的所有出口后,笔者试图为他们归出类别,也方便以后在设计出口的时候可以按照这几个方向去思考。
1、功能特权:
礼物兑现
去广告
产品相关的实用功能扩展
获取生日礼包
单次操作获得更多经验值(加速)
达到活动参与门槛
2、资源优先:
官方热门推荐
添加标签,官方标签分类推荐
优先推荐参与官方活动
提高活动中奖率
优先客服处理
按情况优先上麦
3、限制放宽:
照片批量上传数量和空间容量
商城可买商品的品类增加
功能操作次数限制放宽(如头像更改次数)
4、视觉差异显示:
头像、昵称
皮肤
主页装饰元素
出现形式:上麦效果,入场效果
5、兑换抵现:
(限时/抢先)兑换礼物
参与抽奖
商城消费抵现
免运费,提供退货保障
*在比较了各种不同的框架后,文章整体的知识框架和概念选择采用Jinkey的文章《史上最全用户成长体系分析,附6大案例》里的框架,比较合理全面,而且容易理解。在此非常感谢Jinkey的分享。
* HOOKED模型内容采集自@杨国庆Larus的文章,详细请参考
《如何设计一个比较完备的、有用户黏性的用户激励体系?》
本文 转自 产品经理社区
URL:https://coffee.pmcaff.com/article/849219193623680?newwindow=1
关注成都CDA数据分析师公众号,获取更多精彩内容


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









