






大家好,我是小轩
本文主要介绍了关于Hive常见的优化操作
Join算子
1、cross join优化
例如下面两表需要作笛卡尔积
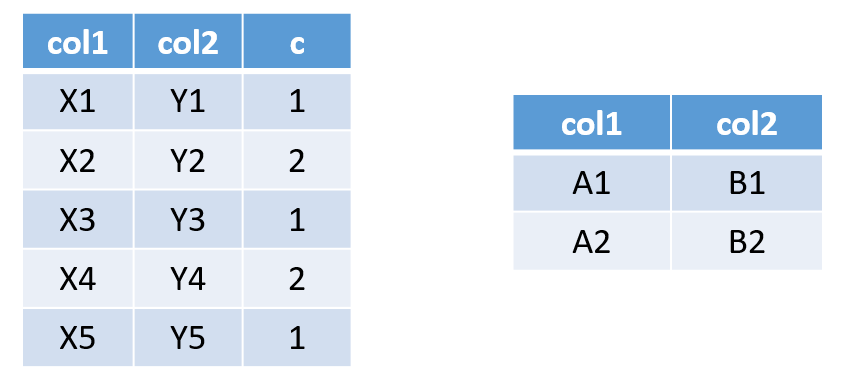
直接使用cross join关联只会分配一个reduce,导致耗时严重,因此我们可以将小表扩充一列,并且复制n倍,然后进行left join操作。这样扩充几倍,就会分配几个reduce。
下图为复制两倍的情形:
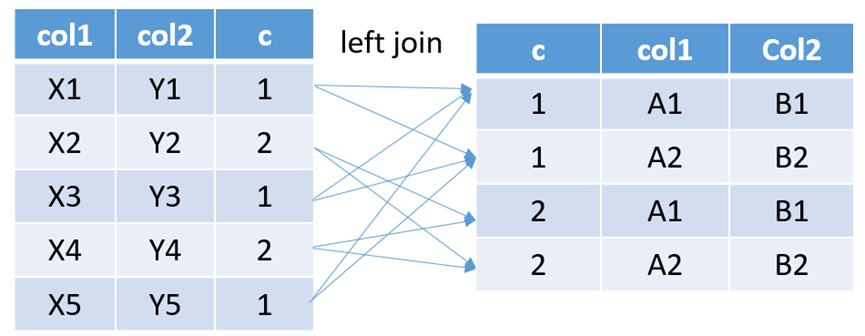
这样就达到了笛卡尔积的效果。
以某张表的计算任务为例,原始计算任务中使用了cross join,因此只有一个reduce,执行耗时30分钟,利用上述方法进行优化,部分代码如下:
-- t1加虚列
select
sig.dtime as dtime
, t1.customerid as customerid
, sum(amount) as amount
from mytable t1
inner join
(
select
customerid
, int((row_number() over (partition by 1)) % 10) as ind
from mytable
) tag
on t1.customerid = tag.customerid
left join
-- t2加虚列
(
select
dtime
, ind
from (
select
tardate AS dtime
from dwd_ob_common.t_date
where
tardate between regexp_replace(add_months(CURRENT_DATE(), - 12), '-', '') and regexp_replace(date_sub(CURRENT_DATE(), 1), '-', '')
) sig
-- 复制10倍
LATERAL VIEW explode(array(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)) virt as ind
) sig
on tag.ind = sig.ind上述代码执行耗时15分钟,缩短了一半的时间。
2、join模型

串联模型
如上图所示,通过base与sub1关联计算得到mid1,然后再通过mid1与sub2关联计算,得到mid2,最后通过mid2关联sub3得到最终表dst,这种计算模型存在明显依赖,计算只能逐步串行进行,因此性能最慢,除非业务上确有必要,否则不建议采用这种写法。
伪代码如下:
select ...
from (
select ...
from (
select ...
from base
left join sub1 on base.key1 = sub1.key1
)mid1
left join sub2 on mid1.key2 = sub2.key2
)mid2
left join sub3 on mid2.key3 = sub3.key3
并联模式
如上图所示,通过base分别与sub1,sub2和sub3关联直接得到最终表dst,各表join可以并行进行,效率明显比串联模型高,但仍存在以下问题:
1、并行计算的公用表base无法针对不同的子表分别作行或者列裁剪,对于base为大宽表的场景,参与中间计算的字段过多,数据量过大;
2、base与各子表的关联key各不相同,可能存在不同的倾斜问题,无法对各子表针对性做倾斜优化;
伪代码如下:
select ...
from base
left join sub1 on base.key1 = sub1.key1
left join sub2 on base.key2 = sub1.key2
left join sub3 on base.key3 = sub3.key3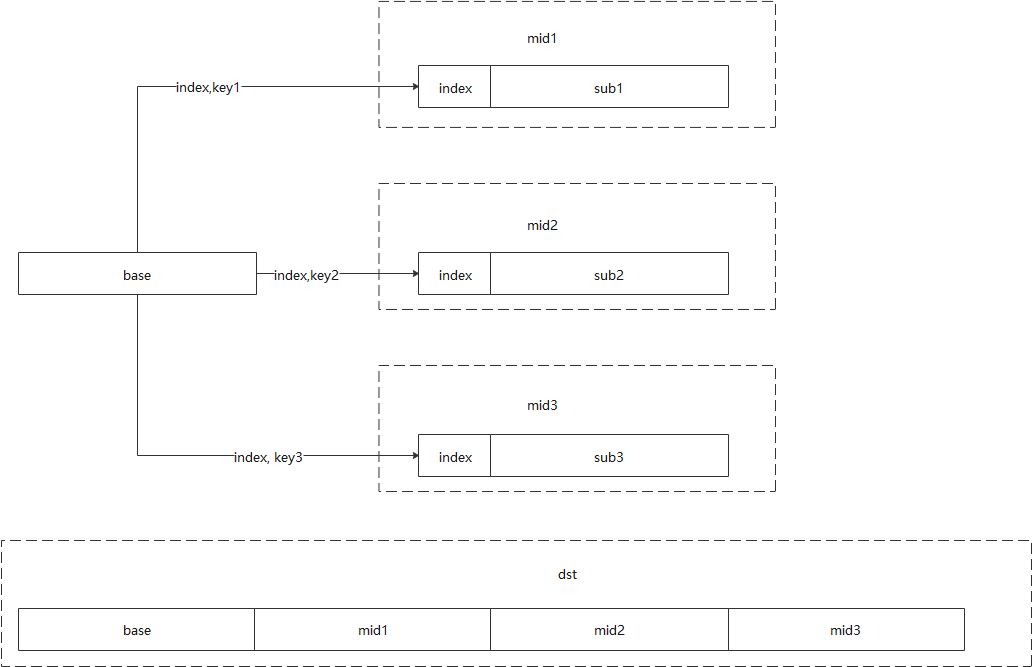
分治模式
如上图所示,为了解决并联模型存在的问题,为base表增加一个主键index,在base与各子样子join时,以index代表base表的行记录,以with...as...的语法分别处理base和子表的join计算,分别得到中间表mid1,mid2和mid3,最后通过index将各中间表join在一起,由于index的唯一性,因此最后一步join必然没有倾斜问题。
此模型的优势:
1、分治后,降低了代码理解难度,提升可维护性;
2、由于对各子表采取了分而治之的策略,因此各中间表处理过程中,无论是base,还是子表本身都可以方便地进行行或者列的裁剪;
3、由于只考虑base与具体子表的join,可以对key值倾斜场景进行针对性优化。
但是,对于原本没有主键的base表,需要人为增加一个字段来做为主键,比如以uuid作为主键,增加了表处理逻辑和存储空间。因此对于不是特别复杂或者没有性能瓶颈的join计算,还是建议直接使用并联模型。
模型伪代码如下:
with
mid1 as (
select ...
from (
select index, key1 from base
) base
left join sub1 on base.key1 = sub1.key1
),
mid2 as (
select ...
from (
select index, key2 from base
) base
left join sub2 on base.key2 = sub2.key2
),
mid3 as (
select ...
from (
select index, key3 from base
) base
left join sub3 on base.key3 = sub3.key3
)
select ...
from base
left join mid1 on base.index = mid1.index
left join mid2 on base.index = mid2.index
left join mid3 on base.index = mid3.index数据倾斜
1.1 什么是数据倾斜
在mapreduce中,同一个key的value会分给同一个reduce来处理,如果个别key的数据过多,其他的key相对较少,那么就会出现数据倾斜,经常表现为进度长时间保持在99%,查看日志会发现只有少量几个reduce任务未完成。
1.2 数据倾斜的类型
① group by:某些值的数量过多,处理该值的reduce耗时严重
② join有以下几个情形:大表关联小表,大表的key倾斜;大表关联大表,空值的
key倾斜;
1.3 解决方法
① group by造成的数据倾斜:
set hive.map.aggr=true; --在map中会做部分聚集操作,效率更高但需要更多
的内存
set hive.groupby.skewindata=true; --默认false,数据倾斜时负载均衡第二个参数设置成true之后,会使计算变成两个mapreduce,在第一个shuffle过程
的partition时随机给key值打标签,使得每个key都能均匀分不到各个reduce上,但
是这样相同的key不能保证分到一个reduce上,所以需要第二次mapreduce,此步
的shuffle是正常执行的,这样数据不均匀的问题就得到了改善。
② 大表关联小表,大表的key倾斜
利用map join,在map完成join,而不是在reduce端完成,避免了shuffle阶段,从
而避免了数据倾斜,此操作会将所有的小表全量复制到每个map节点上,然后再将
小表缓存在每个map节点的内存里与大表进行join。因此小表的大小的不能太大,
一般也就几百兆,所以在设置参数时要注意,因为小表的大小默认是25M,用如下
参数调整
set hive.mapjoin.smalltable.filesize = 100000000;
-- 将值改成100M③ 大表关联大表,空值的key倾斜
一般采取对空值随机赋值,例如两张表用customerid关联
select t1.feeid, t2.dtime
from t1
left join t2
on coalesce(t1.customerid, concat('hive',rand())) = t2.customerid1.4 设置skewjoin参数解决Hive由于join产生的数据倾斜问题
在Hive的数据处理过程中,由于join造成的倾斜,常见情况是不能做map join的两
个表(能做map join的话基本上可以避免倾斜),其中一个是行为表,另一个应该是
属性表。比如我们有三个表,一个用户属性表users,一个商品属性表items,还有
一个用户对商品的操作行为表日志表logs。
假设现在需要将行为表关联用户表:
select * from logs l join users u on l.user_id = u.user_id;
其中logs表里面会有一个特殊用户user_id = 0,代表未登录用户,假如这种用户占
了相当的比例,那么个别reduce会收到比其他reduce多得多的数据,因为它要接收
所有user_id = 0的记录进行处理,使得其处理效果会非常差,其他reduce都跑完很
久了它还在运行。
hive给出的解决方案叫skew join,其原理把这种user_id = 0的特殊值先不在reduce
端计算掉,而是先写入hdfs,然后启动一轮map join专门做这个特殊值的计算,期
望能提高计算这部分值的处理速度。当然你要告诉hive这个join是个skew join,即:
set hive.optimize.skewjoin = true;
还有要告诉hive如何判断特殊值,根据hive.skewjoin.key设置的数量hive可以知
道,比如默认值是100000,那么超过100000条记录的值就是特殊值。
当前只有内连接和crossjoin才生效,外连接(left join 、right join、full join)不生效。
map join导致大量GC或超时
计算任务涉及到外表关联时,要根据外表的数据量调整hive参数。如果计算任务对应的FI日志中显示大量的GC或超时时,考虑将mapjoin关掉:
set hive.auto.convert.join=false;
当前hive默认的参数设置了“hive.auto.convert.join”值为true,由于hive无法对外表进行准确的表分析,导致生成的执行计划可能存在问题。hbase表的数据量较大,若进行map join会导致节点频繁GC,从而导致失败,将参数调整为“false”后不再出现计算任务失败的问题。
宏的使用
在编写HQL的过程中,很多逻辑需要反复使用。这时我们可以使用宏对这段逻辑进行提炼,起到优化开发效率、提升程序可读性(尤其是括号嵌套很多层、case-when嵌套很多层的时候),一般在ADS层有大量代码使用case when嵌套很多层。
举个栗子:
create temporary macro sayhello (x string) concat('hello,',x,'!');
select sayhello('程序员'); --输出:hello,程序员!在上面的的代码中,首先我们定义了一个名为sayhello的宏,输入参数为一个字符串x,输出为对x的拼接。如果之后还需要向HR问好,只要输入sayhello('HR')即可。
显而易见,我们可以把宏当做一个自定义“函数”,其开发过程与UDF相比更加简捷。
工作中经常使用到的宏就不在这里详细列出,可以自行上网查

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









