







 本文详细介绍了CUDA中的线程通信、内存模型和同步性。线程通过共享内存交流部分结果,利用数据重用提高效率。内存模型包括局部内存、共享内存和全局内存。线程同步通过屏障和原子操作防止冲突。文章还探讨了如何有效地访问内存以最大化计算能力,并给出了使用不同内存类型的示例。
本文详细介绍了CUDA中的线程通信、内存模型和同步性。线程通过共享内存交流部分结果,利用数据重用提高效率。内存模型包括局部内存、共享内存和全局内存。线程同步通过屏障和原子操作防止冲突。文章还探讨了如何有效地访问内存以最大化计算能力,并给出了使用不同内存类型的示例。
文章目录
1.通信
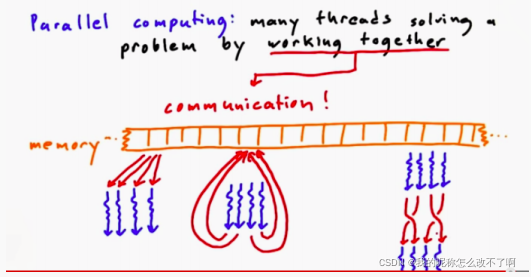
协同工作其实就是与通信有关,在CUDA中,通信发生在内存中。例如,线程可能需要从同一输入位置读取,或者写入到同一个输出位置,有时线程可能需要交换部分结果
通信的不同类型以及并行计算中,不同的通信模型(about how to map tasks(which are threads in cuda) and meory together),通信的模式叫做映射(communication pattern is called map)

在黄格子里的每个元素,你将对每个元素进行同样的函数或者计算任务,这意味着每个任务在内存中特定位置读取和写入,这是一个线程的简单映射
有些不是这么简单的:
比如依次取三个数的平均值或者用一个像素周围像素的平均值来表示此像素的这种模糊计算

除了这种聚集操作,还有分散操作
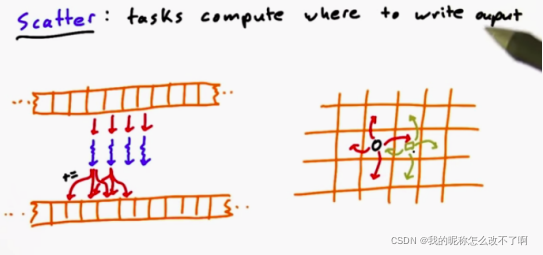
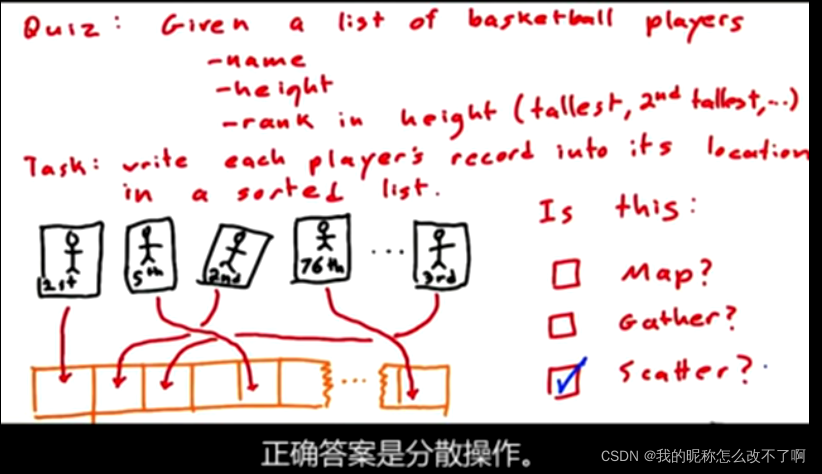
因为,每个线程会计算在哪里写入他的结果
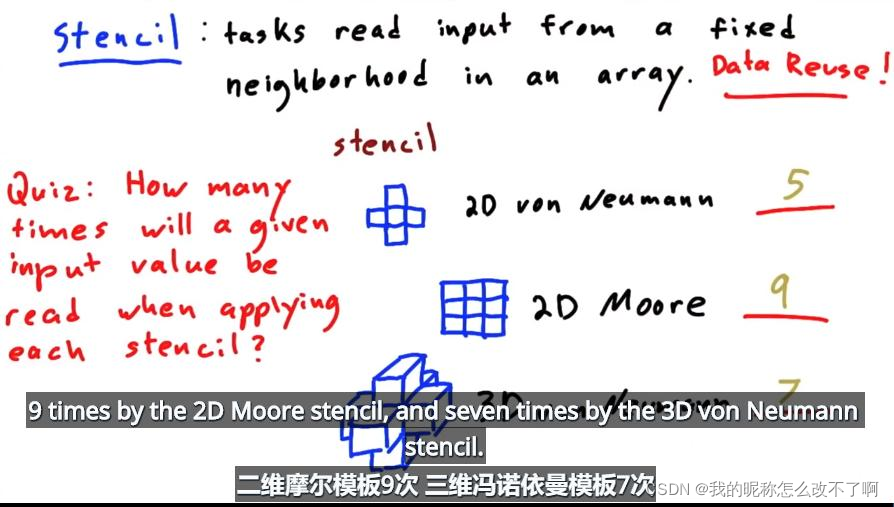
还有模板操作(stencil):用给定的模板更新数组中的每个元素,对周围的像素进行着色
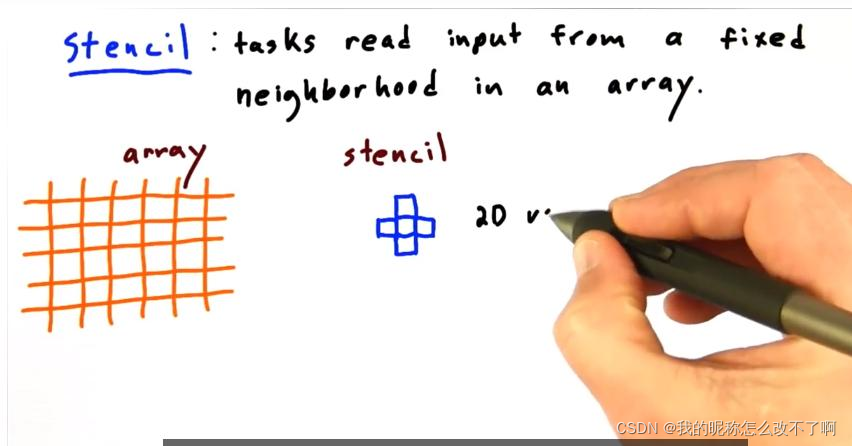

这里其实有数据重用,模板有几个小块,每个小块就会被重复读取多少次
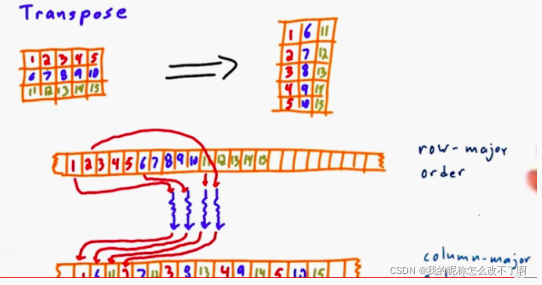
另一种操作:转置(transpose )【数组运算,矩阵,图像操作】按顺序读不按顺序写
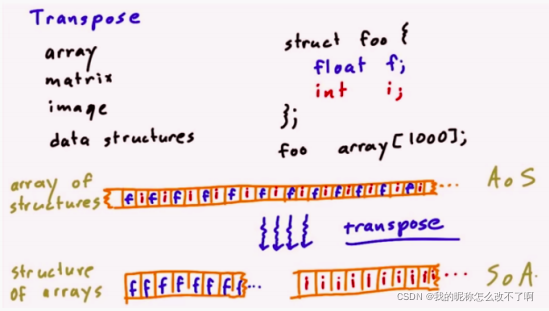
这种操作不仅适用于【数组运算,矩阵,图像操作】,也适用于各种数据结构(本质是任务重新排序内存中的数据元素)
比如

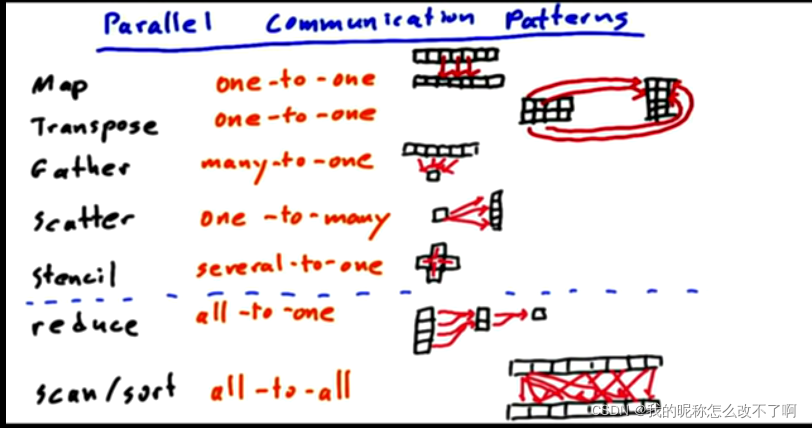
从概念是奖,映射和转置是一对一的:每个输入映射到单个唯一的输出
聚集可以看做是多对一,分散是一对多;模板是特殊的聚集,从给定输出位置的邻居中选择少数输入来得到输出,可以看做是几对1
又引出两种:归约(全对1)和扫描(全对全,所有输入都会影响所生成的输出的目的地,如排序)
2.线程如何一齐有效的访问内存?
先讨论一个子问题:如何利用数据重用(how to exploit the data reuse)——有很多线程经常同时访问相同数据,我们如何利用这一点来减少在内存上花费的总时间?
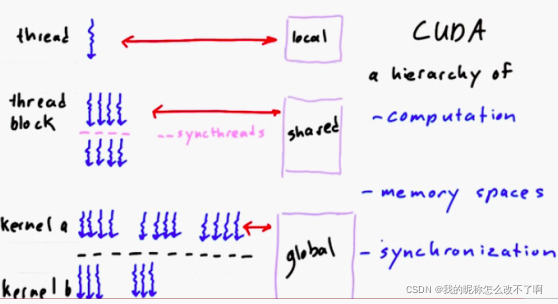
3. 线程如何通过 共享内存 来交流部分结果
一个真实的问题是:线程是共享内存的,在相同的内存上进行读写,如何有效的防止内存访问冲突
为了解决这两个问题,要更深入的了解GPU的硬件
a.总结之前学过的:programmer’s view of the GPU
程序员的工作是吧你的程序分割成更小的计算即kernel,kernel的关键点是它由多个线程执行(线程是执行路径,一条通过程序代码的执行路径)

每个线程走的路径可能都不一样
关键点是它们以线程块的形式出现,一个线程块是一组解决次要问题的线程
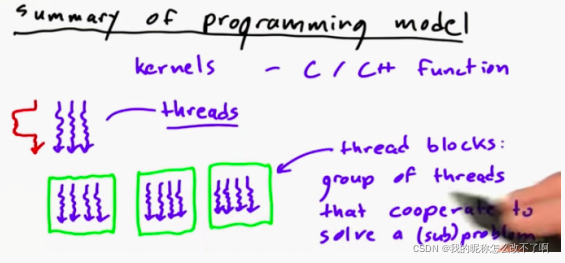
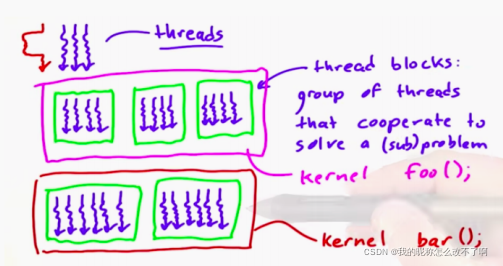
我有不同数量的具有不同数量线程的线程块
关于线程块:

还需要学一些GPU硬件知识


一个SM相应的有许多简单的处理器,处理器可以运行一堆并行线程,还有一些其他的东西比如内存
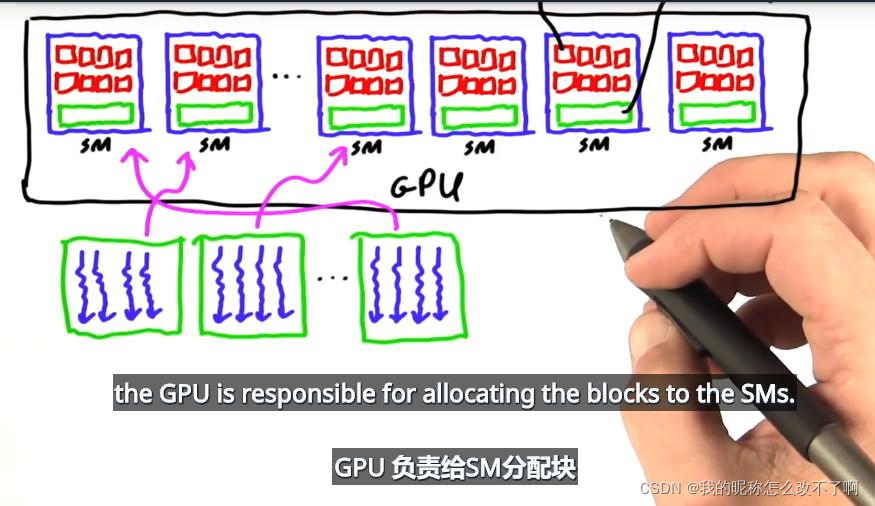
给GPU一大堆线程块,GPU会负责分配他们在硬件SM上运行,所有的SM都以并行方式独立运行

一个SM有可能运行多个线程块,而一个线程块无法在一个以上的SM上运行(根据定义,一个线程块只能在一个SM上运行)

程序员:软件(线程块) GPU:硬件(SM)
这些,程序员都不能保证

CUDA对线程块将在何处何时运行不做保证:
例如,一个线程块如果快速完成,SM可以立即安排另一个线程块而无需等待其他线程块完成

这种编程模型的后果:
- 你对哪个block在哪个SM上运行无法进行任何假设
- 无法获得block之间任何明确的通信:例如block x在进行下一步之前,它正在等待block y给他一些结果,但是block y已经完成运行并退出。(并行运算的死锁的例子)
CUDA可以保证的:
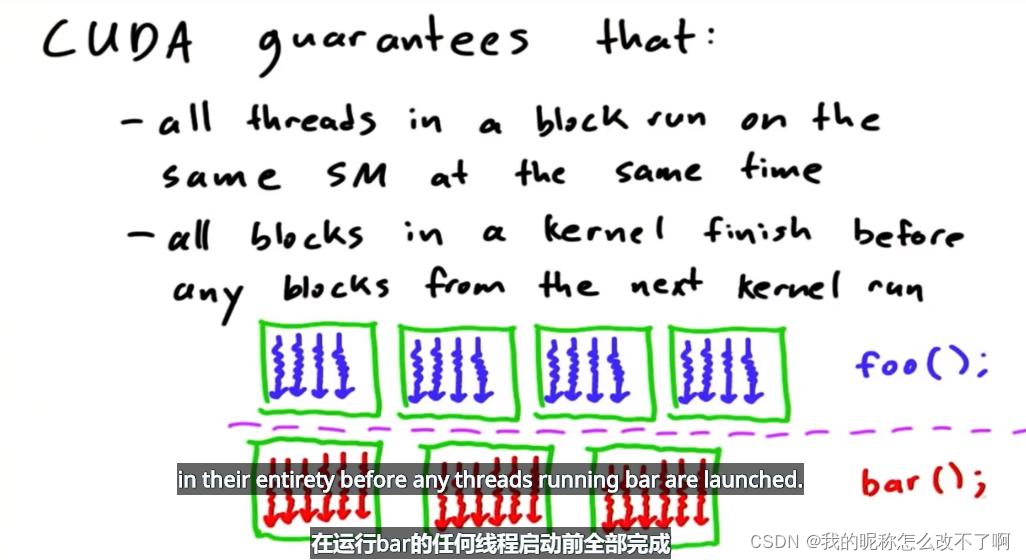
一个CUDA例子说明这些理念:

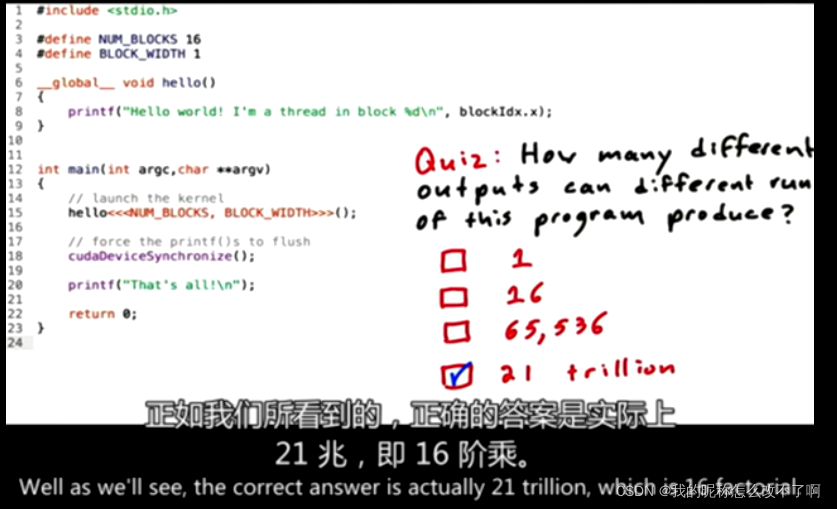
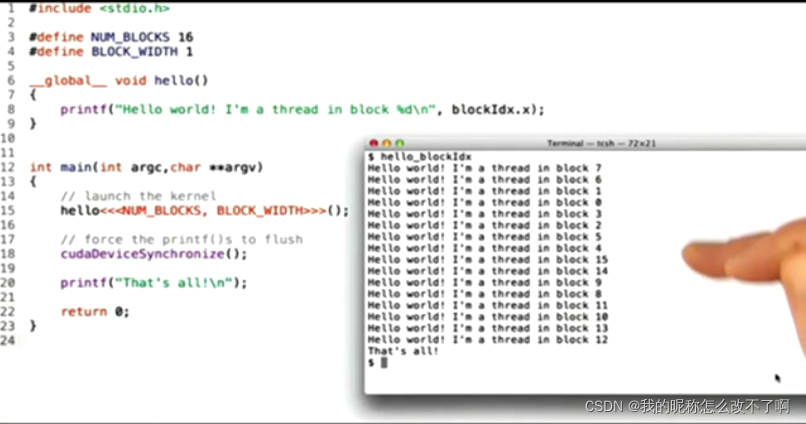
每一次块都按照不同的顺序执行
CUDA可以保证的:
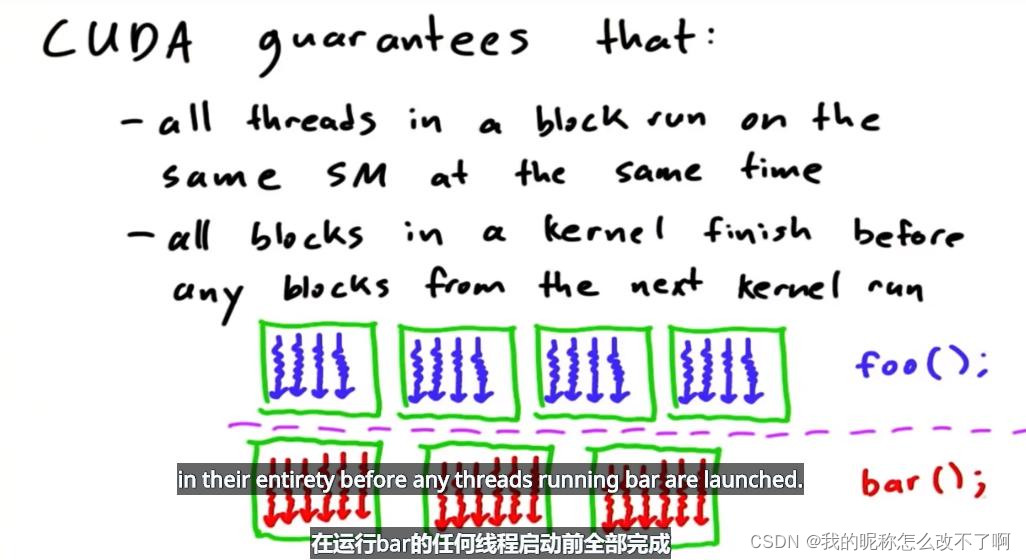
foo在运行bar的任何线程启动前全部完成
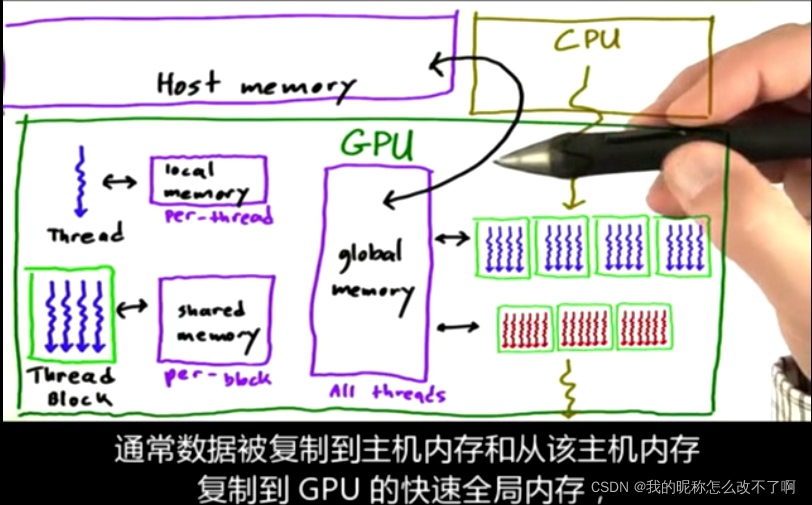
4.内存模型
GPU上:
a.每个线程自己可以访问的——local memory
b.一个线程块中的线程都可以访问的——shared memory
c.一个SM中所有线程都可以访问的——global memory
CPU:有自己的内存(host memory),而且还会启动核函数
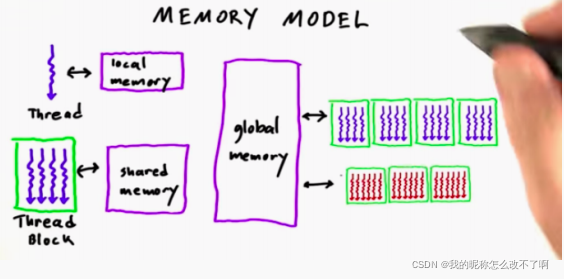
5.同步性
避免在a线程想读时候,b线程还没改完(本应读取到的是b线程改完后的结果),同步操作可以避免这样的问题发生
同步性的最简单形式是屏障(barrier):设置一个屏障,barrier是程序中的一个点,在该点所有线程停止并等待,等待所有线程都到达,再一起跑

什么时候需要用到屏障呢?
比如:把后一个数组元素赋值给前一个(左移)

共需要三次屏障
第一次:保证线程对数组中所有元素都赋值完成,线程块中的所有线程都要到达这个同步线程调用
第二次:保证我把【后值】取出来的时候,别的线程别动,别往我这里写入??
这些线程块都被组织在kernel中,每个kernel拥有一对线程块;内核之间存在隐式屏障(如果触发两个内核)
第三次:保证所有的【后赋前】的操作都完成
CUDA的核心是计算的层次结构,线程,线程块和kernel;以及与其对应的内存层次结构 local,shared,global内存;以及线程同步,屏障和同步kernels的隐形屏障
小测验:

一个临时变量来分开读取和写入

读取——>同步->写入->同步->printf,写入操作必须在printf之前完成

6.writing efficient programs
先谈高层次策略(不谈底层具体实现和优化):这些是在你编写程序时必须要牢记的
a.最大化计算能力
最大化每个线程的工作量或最小化每个线程的内存
1个FLOPS代表每秒浮点运算,TFLOPS是兆FLOPS

GPU算力很强,但是访问内存会浪费时间,导致算力使用率下降;
对应解决办法是:
1)最大化每个线程的计算量(工作量)
2)最小化每个线程访问内存的时间!(因为线程除了在访问内存就是在计算)
下面讨论如何减少访问内存的时间:


7.使用CUDA中不同内存的例子
本地内存(local memory)

a.f就是本地内存(在__global__大括号里面建的),它在本地内存中专用于此线程
b.in也是(__global__的参数):每个线程又有a copy of a parameter called in,每个参数都有自己的参数in的副本,实际的代码会处理这些变量

全局内存
传递给kernel的参数,参数依旧是存在local memory的,但是参数本身是一个指针,这个指针指向了global memory
指针是指向global memory的
一旦kernel得到了这个指针,他就可以操纵指针指向的global memory中存的内容、
也就是说:因为一个函数的所有参数都是本地变量,是专用于该线程的,所以如果你想要操作全局内存,必须给kernel传递这个内存的指针过来

怎么在CPU上分配?

*d_arr是指向我在设备上分配的global memory的
下面开始在global memory上分配内存(本质是把一个指针变量传递给另一个指针变量)

后面那个参数意思是(是个大小——字节数):开辟128个float的空间,并且返回型是指针
前面那个参数:是一个指针
cudaMalloc完成的功能:将后面的指针填充给前面的指针
cudaMalloc就是用来在global memory上分配房间的

接着来初始化(目标地址指针,来源地址指针,字节大小,copy方向)给global 的 房间里填上值

global memory的诀窍是,因为你只可以在kernel中传递local变量,你要在kernel外分配和初始化global memory,然后传入一个指针
共享内存
/**********************
* using shared memory *
**********************/
// (for clarity, hardcoding 128 threads/elements and omitting out-of-bounds checks)
__global__ void use_shared_memory_GPU(float *array)
{
// local variables, private to each thread
int i, index = threadIdx.x;
float average, sum = 0.0f;
// __shared__ variables are visible to all threads in the thread block
// and have the same lifetime as the thread block
__shared__ float sh_arr[128];
// copy data from "array" in global memory to sh_arr in shared memory.
// here, each thread is responsible for copying a single element.
sh_arr[index] = array[index];
__syncthreads(); // ensure all the writes to shared memory have completed
// now, sh_arr is fully populated. Let's find the average of all previous elements
for (i=0; i<index; i++) { sum += sh_arr[i]; }
average = sum / (index + 1.0f);
// if array[index] is greater than the average of array[0..index-1], replace with average.
// since array[] is in global memory, this change will be seen by the host (and potentially
// other thread blocks, if any)
if (array[index] > average) { array[index] = average; }
// the following code has NO EFFECT: it modifies shared memory, but
// the resulting modified data is never copied back to global memory
// and vanishes when the thread block completes
sh_arr[index] = 3.14;
}
怎么声明shared memory中的变量?
shared float sh_arr[128];
最重要的一点,已知




把全局变量中的array放入共享变量中
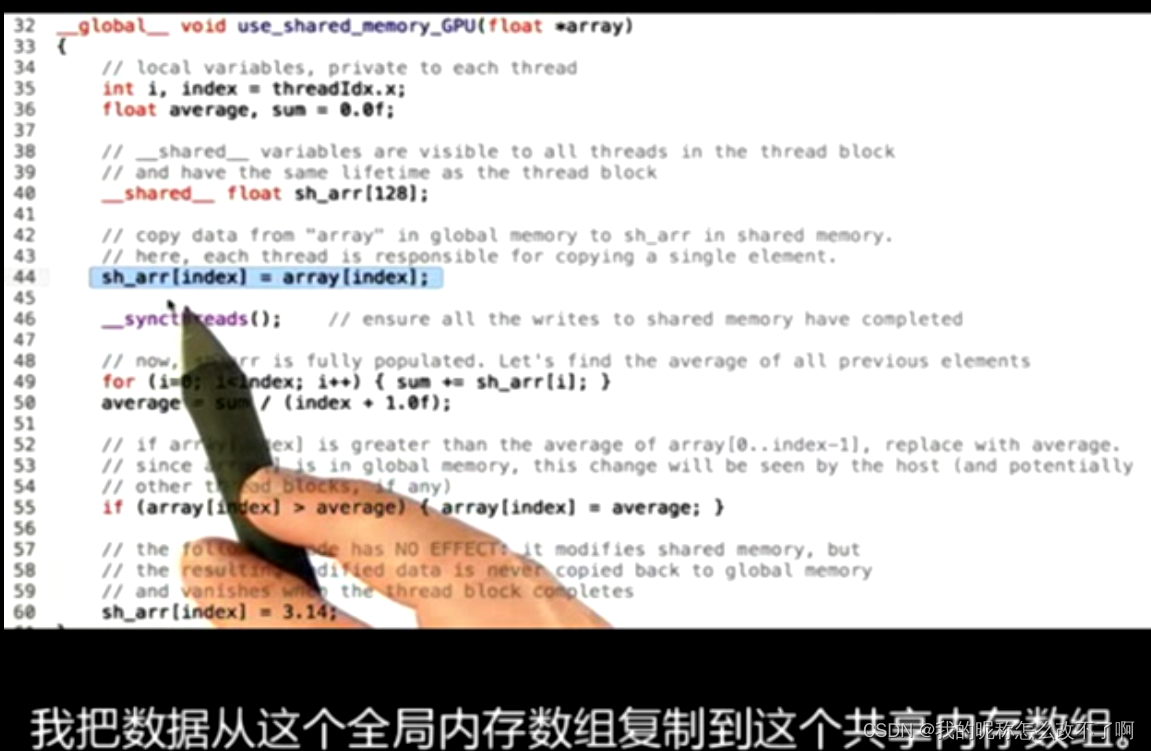
在所有【写】操作之后都要注意是否需要同步
我们得保证对共享内存数组做任何操作之前已经完成写入到共享内存

__syncthreads(); // ensure all the writes to shared memory have completed

注意到,计算所有值的平均是在共享内存上进行的,因为:共享内存上计算快!每个线程要访问数组中的一堆元素,
而判断数组中元素的值是否大于平均值是在全局内存上进行的,因为:当kernel完成这个改动时,host是看得见的!也会被其他线程块中的线程看到

最后一个语句完全没有用,因为随着线程块消失,共享内存也消失了,通常会被编译器过滤掉
合并全局内存访问


每当GPU上的一个线程读取或写入全局内存,他总是一次访问一大块内存
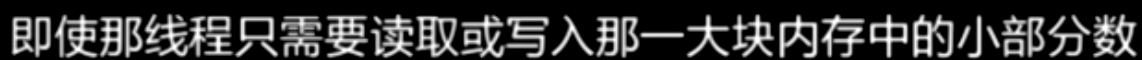



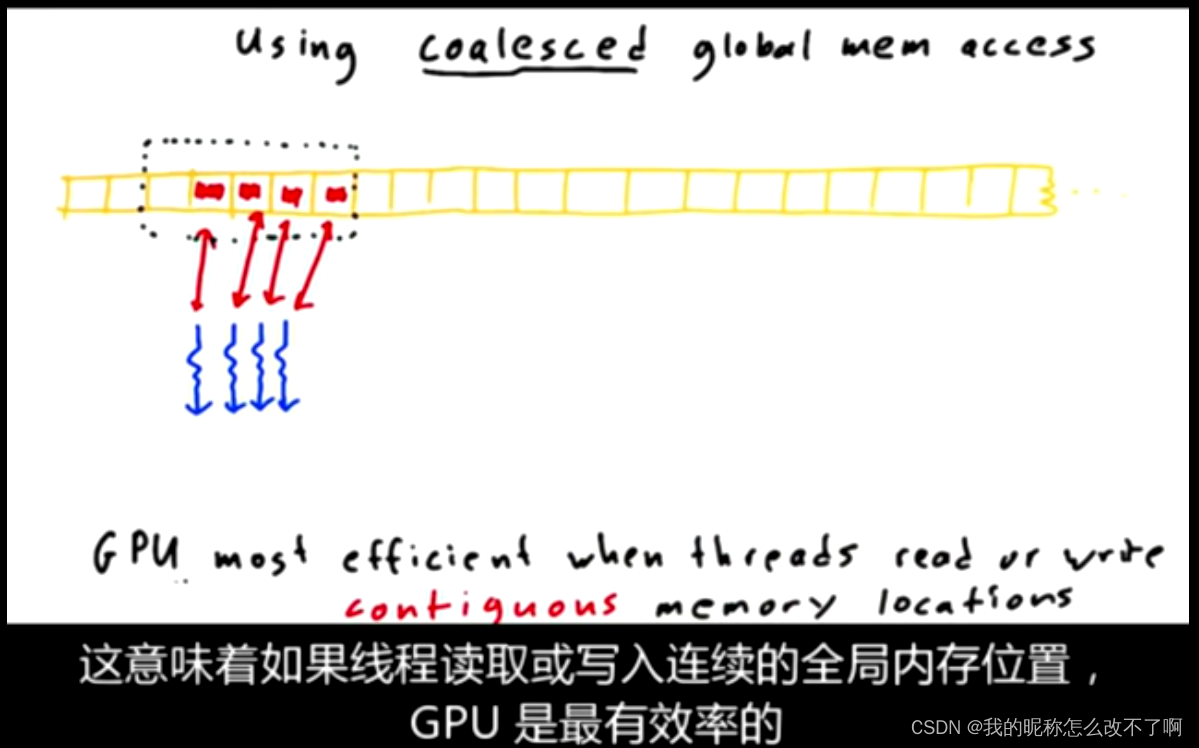

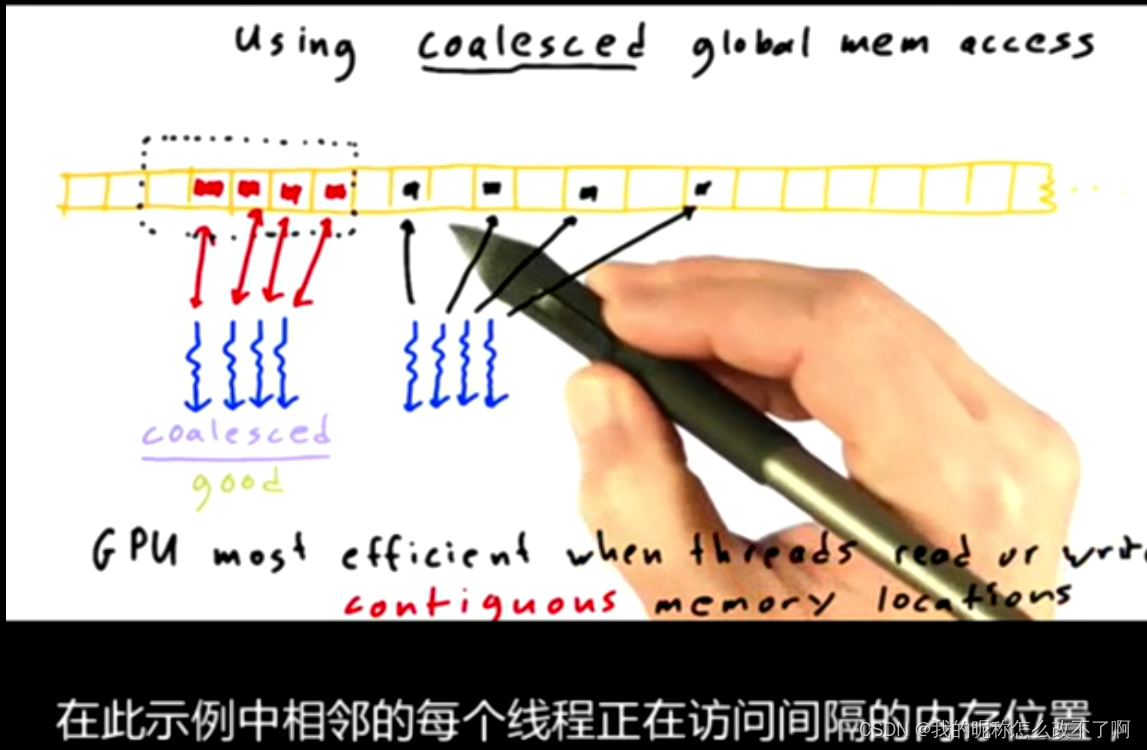
所以这个没有合并,我们把它叫做跨步

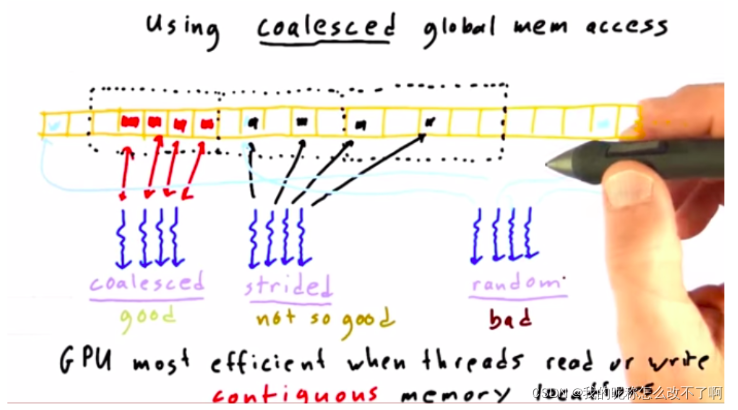
quiz:




内存访问冲突
讨论一个相关问题:
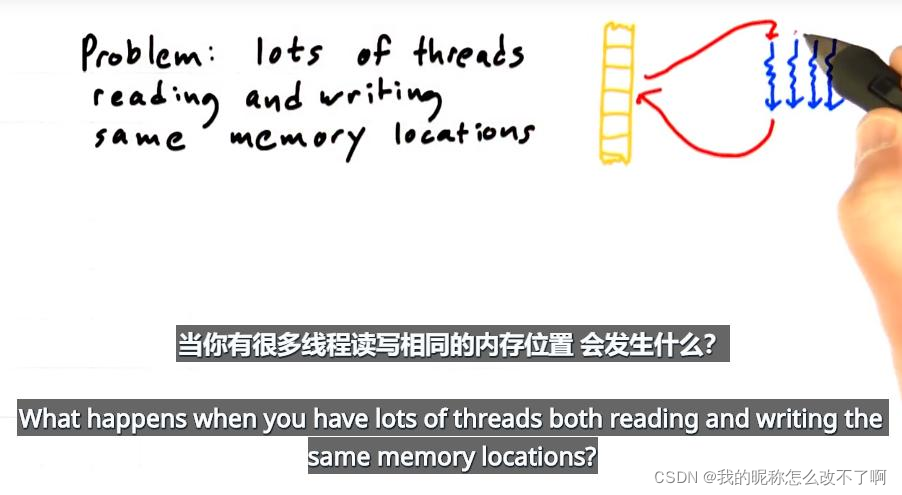



解决方案
a.设置屏障:麻烦

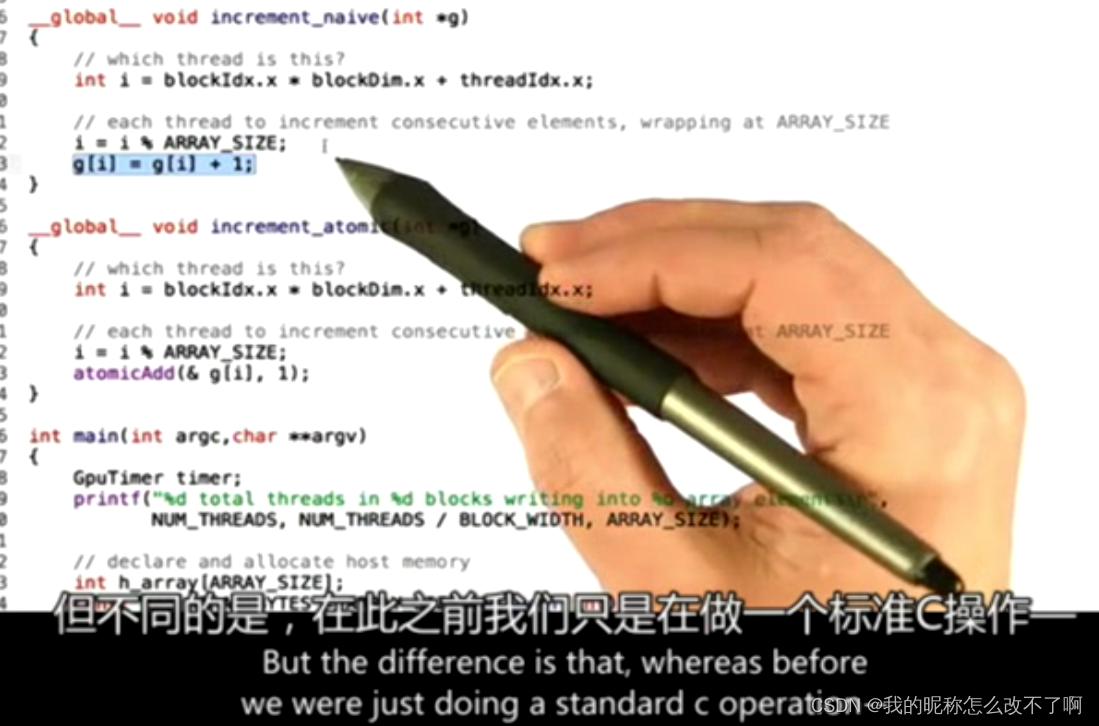
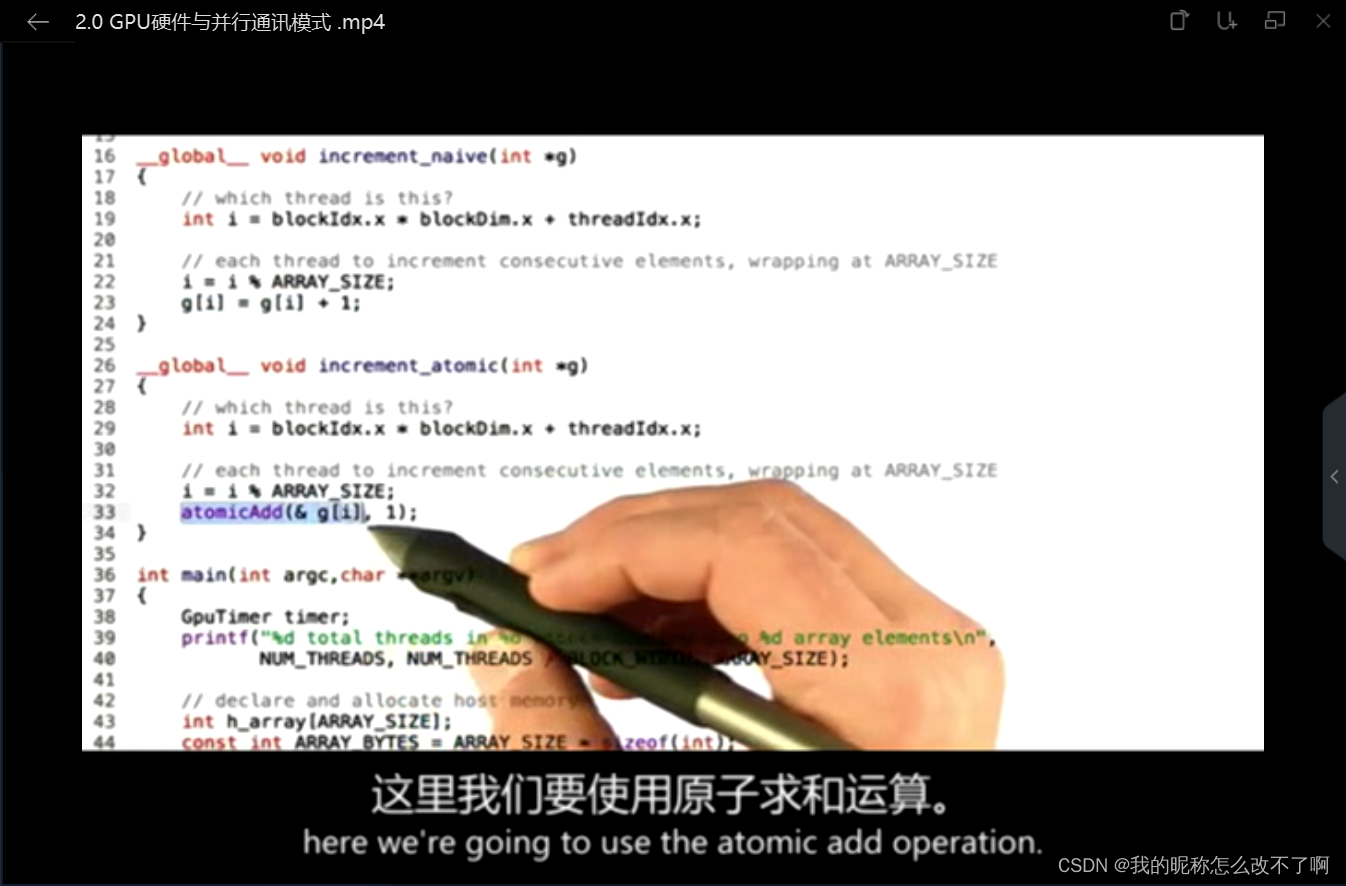
b.原子操作



#include <stdio.h>
#include "gputimer.h"
#define NUM_THREADS 1000000
#define ARRAY_SIZE 100
#define BLOCK_WIDTH 1000
void print_array(int *array, int size)
{
printf("{ ");
for (int i = 0; i < size; i++) { printf("%d ", array[i]); }
printf("}\n");
}
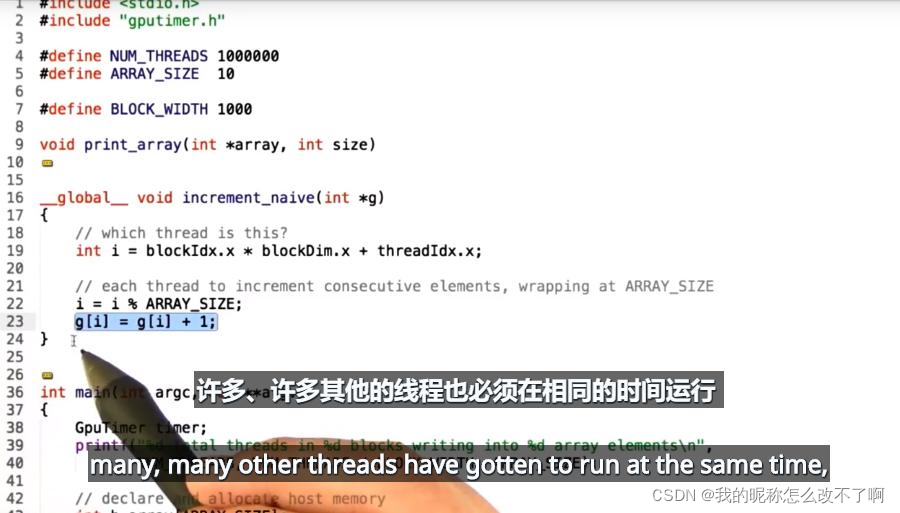
__global__ void increment_naive(int *g)
{
// which thread is this?
int i = blockIdx.x * blockDim.x + threadIdx.x;
// each thread to increment consecutive elements, wrapping at ARRAY_SIZE
i = i % ARRAY_SIZE;
g[i] = g[i] + 1;
}
__global__ void increment_atomic(int *g)
{
// which thread is this?
int i = blockIdx.x * blockDim.x + threadIdx.x;
// each thread to increment consecutive elements, wrapping at ARRAY_SIZE
i = i % ARRAY_SIZE;
atomicAdd(& g[i], 1);
}
int main(int argc,char **argv)
{
GpuTimer timer;
printf("%d total threads in %d blocks writing into %d array elements\n",
NUM_THREADS, NUM_THREADS / BLOCK_WIDTH, ARRAY_SIZE);
// declare and allocate host memory
int h_array[ARRAY_SIZE];
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(int);
// declare, allocate, and zero out GPU memory
int * d_array;
cudaMalloc((void **) &d_array, ARRAY_BYTES);
cudaMemset((void *) d_array, 0, ARRAY_BYTES);
// launch the kernel - comment out one of these
timer.Start();
// increment_naive<<<NUM_THREADS/BLOCK_WIDTH, BLOCK_WIDTH>>>(d_array);
increment_atomic<<<NUM_THREADS/BLOCK_WIDTH, BLOCK_WIDTH>>>(d_array);
timer.Stop();
// copy back the array of sums from GPU and print
cudaMemcpy(h_array, d_array, ARRAY_BYTES, cudaMemcpyDeviceToHost);
print_array(h_array, ARRAY_SIZE);
printf("Time elapsed = %g ms\n", timer.Elapsed());
// free GPU memory allocation and exit
cudaFree(d_array);
return 0;
}









原子内存运算限制:

a.






b.



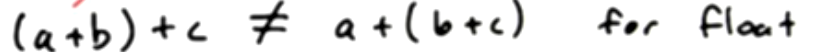
c.



quiz:

总结第一个策略,引出第二个:



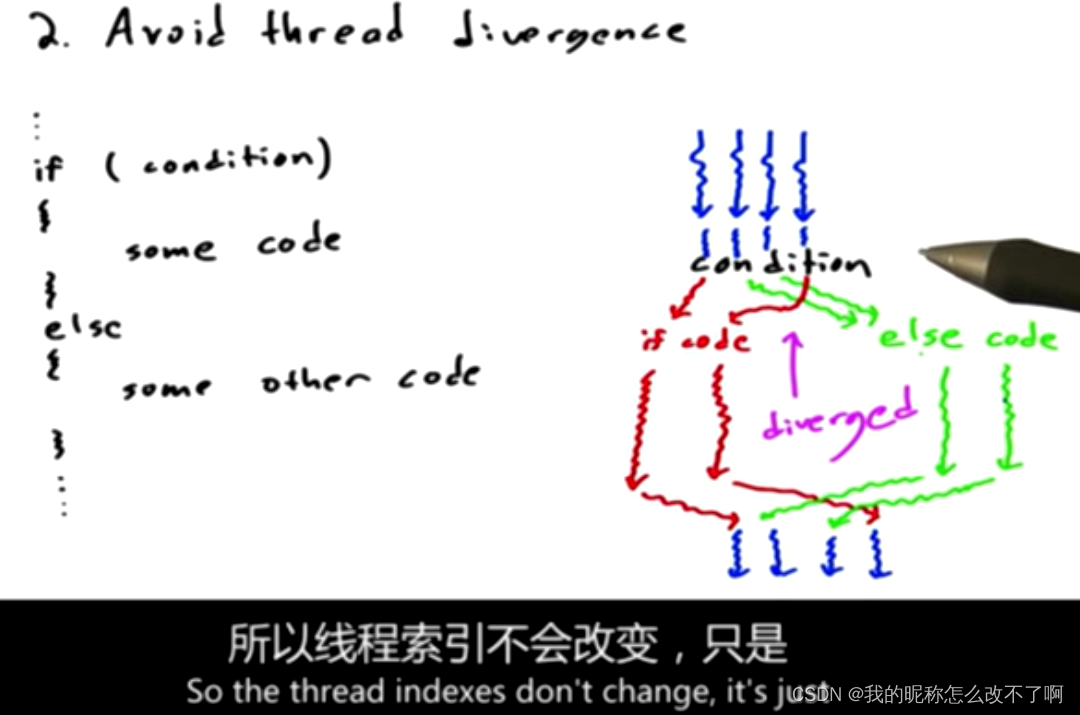



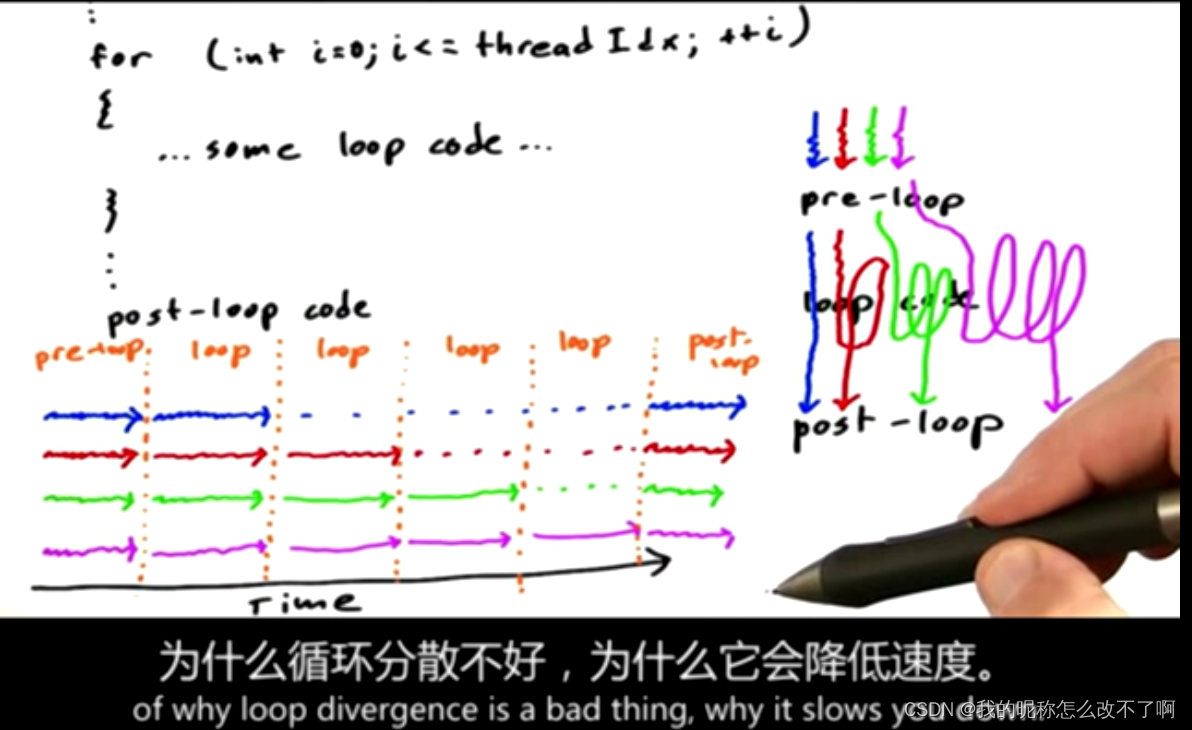


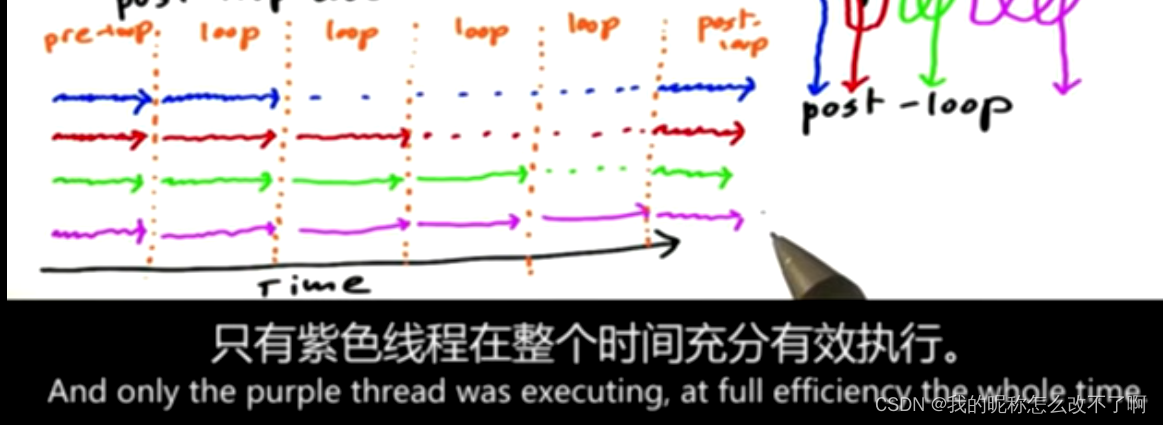
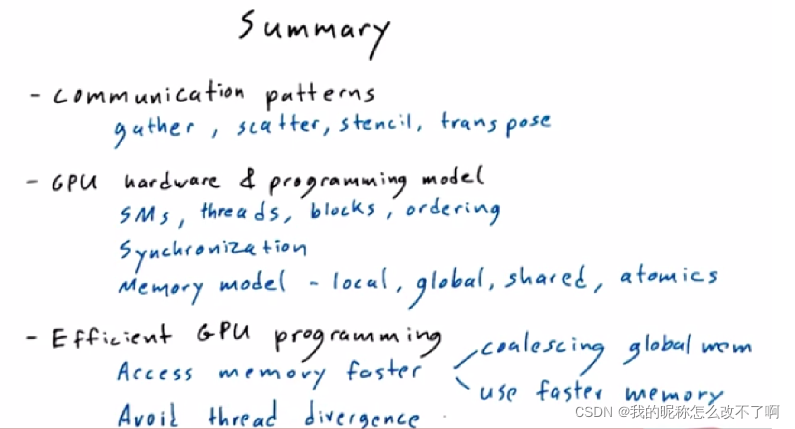
8.作业2



























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











