







编译原理期末复习
考试范围

考试考完了,依然再来补充一波。
编译原理基础知识总结
第一章 引论
##下面这个我们考简答,考了12分,你觉得重要吗?如果考简答,基本没什么好考,所以背下咯。
词法分析:词法分析阅读构成源程序的记号流,按编程语言的词法规则把他们组成词法记号流。
语法分析:检查词法分析输出的记号流是否符合编程语言的语法规则,依据这些规则所体现出的语言构造的层次性,建成一种树形的中间表示,这种中间表示用抽象语法的方式描绘了该记号流的语法情况。
语义分析:按语法树和语义表中的信息,检查源程序的各部分是否符合语义一致性,保证程序的各部分有意义的结合在一起。
中间代码生成:经过语法分析和语义分析,许多编译器为源程序生成更低级的显示中间表示,可以把这种中间表示成一种抽象的程序。
代码优化:改进中间代码,以生成较好的目标代码。目标代码较短且能耗较低。
目标代码生成:把源程序的中间表示映射成一种目标语言。如果目标语言是机器语言代码,则需要为源程序所用的变量选择寄存器或内存单元,然后把中间指令序列翻译为完成同样任务的机器指令序列。
第二章词法分析
主要掌握的要点:语言->正规式->NFA->DFA->最简DFA
最好通过习题来巩固。
- 什么是正规式?
设∑是有穷字母表,并定义辅助字母表∑’={Φ, ε, | , . , *, (, )}- ε,Φ都是∑上的正规式,它们所表示的正规集为{ε}, Φ ;
- 任何a是一个正规式,若a∈∑,它所表示的正规集为{a};
- 如果R1和R2是正规式,它们表示的正规集分别为L1和L2,则 R1|R2 , R1·R2 , R1* , (R1) 也是正规式,并且它们所表示的正规集分别为L1∪L2 ;L1L2;L1* ; L1
- 仅有有限次使用上述三步骤而定义的表达式才是∑上的正规式,仅有这些正规式表示的字集才是∑上的正规集。
注意:不要混淆Φ和ε,正规表达式ε描述的语言只含一个空字符串ε,而Φ表示的语言不含有任何字符串。程序设计语言的单词都能用正规式来定义。若两个正规式e1,e2表示的正规集相同,则称它们等价。记作:e1=e2
正规式定义一些简单的语言,能表示给定结构的固定次数的重复或者没有指定次数的重复。但正规式不能描述配对或嵌套的结构
第三章 语法分析
- 上下文无关文法的定义:2型文法(上下文无关文法)中,左边必须是非终结符,然而一个终结符一个非终结符的组合不是一个非终结符,如Ab不是一个非终结符,但是两个非终结符的组合就是一个非终结符了,如AB就是行了。
- 上下文无关文法定义一个语言的中心思想是:上下文无关文法定义一个语言的中心思想是:从文法的开始符号出发,反复使用产生式,对非终结符施行替换和展开。
- 正规式不能描述配对或嵌套的结构。
- 最左推导:每一步都替换句型中最左边的非终结符的推导
- 最右推导(规范推导):每一步都替换句型中最右边的非终结符的推导
- 对A的任何两个不同的选择ei 和ej,希望有
FIRST (ei ) 交 FIRST (ej ) = 空
那么当要求A匹配输入串时,A就能根据它所面临的第一个输入符号a,准确的指派某一个候选前去执行任务。这个候选就是那个终结首符集含a的e 。
但有一个前提, FIRST (ei ) 和 FIRST (ej )都不含空字符串。 - FOLLOW(A)是所有句型中出现在紧接A之后的终结符或“$”
- LL(1)文法:
- 文法不含左递归
- 对于文法中每一个非终结符A的各个产生式的候选首符集两两不相交。即,若A→ a1 | a2 | … | a n,则FIRST(a i)∩FIRST(a j)=Φ (i≠j)
- 对文法中的每个非终结符A,若它存在某个候选首符集包含ε,则,FIRST(A)∩FOLLOW(A)=Φ
- 如何让LL(1)文法进行无回溯的分析。
假设要用非终结符A进行匹配,面临的输入符号为a,A的所有产生式为A→ a1 | a 2 | … | a n
- 若a∈FIRST(a i),则指派ai去执行匹配任务。
- 若a不属于任何一个候选首字符集,则:
- 若ε属于某个FIRST(a i),且a∈FOLLOW(A),则让A与ε自动匹配;
- 否则,a的出现是一种语法错误。
根据这四点,就可以解决LL(1)文法的回溯问题。
- First()与Follow()集合的求法:话不多说,直接上例子

有点模糊,深感抱歉。不过,基本方法就是这样。 - 这是一个大佬对一些编译原理四种文法(1型,2型…_)的总结,值得观看:原来编译原理可以这么学.50000多的阅读量噢!
- 四元组(VT , VN , S, P)
- 短语、句柄、素短语、最左素短语
例题:

- 短语:一个句型的语法树中任一子树叶结点所组成的符号串都是该句型的短语,
- 简单短语:当子树中不包含其他更小的子树时,该子数叶结点所组成的字符串就是该句型的直接(简单)短语。
- 因此本题的直接短语的为 S 、(T)、b,短语有S、(T)、b、Sd(T)、Sd(T)db 、(Sd(T)db)。
d不是直接短语,因为d所在的树还有子树所以它不是 !
其实这种的求法,最好是照一个不是子节点节点,当根节点,下面的最外层直接拉出来,就是它的短语。比如,从上到下把T分为T1,T2,T3.
T1做根节点,拉出来是Sd(T)db
T2做根节点,拉出来是Sd(T)
T3做根节点,拉出来是S
所以,d不可能是短语。 - 句柄:一个句型的最左直接短语称为该句型的句柄。句型的句柄是和某产生式右部匹配的子串,并且,把它归约成该产生式左部的非终结符代表了最右推导过程的逆过程的一步。
- 前缀:字的前缀是指该字的任意首部。字abc的前缀有ε、a、ab、abc。
- 活前缀:指规范句型的一个前缀,这种前缀不含句柄之后任何符号。之所以称为活前缀,是因为在右边添加一些符号之首,就可以使它称为一个规范句型。
- 规范句型:用
最右推导导出的句型。
规范前缀:若有规范句型AB,且B是终极符串或空串,则称A为规范前缀。
规范活前缀:若规范前缀A不含句柄或含一个句柄并且句柄在A的最右端(右句型的前缀,该前缀不超过最右句柄的右端),则具有形式A=aN(N为句柄),则称规范 前缀A 为规范活前缀(简称活前缀)。
规约规范活前缀:若活前缀A是含有句柄的活前缀,并且句柄在A的最右端,即具有形式A=aN(N为句柄),则称活 前缀A为规约规范活前缀(简称规约活前缀或者可归活前缀)。
规范归约:最左归约。
相关解释:https://blog.csdn.net/fbp1040791153_/article/details/16105765 - 构造SLR分析表:


19.LALR:
- 同心集的合并不会引起新的移进-归约冲突
- 同心集的合并有可能产生新的归约-归约冲突
- 采用自上而下分析,必须消除
回溯。 - 一个
项目指明了在分析过程中的某时刻所能看到的产生式多大部分。 - 对四种文法讲述的一个大佬:编译原理之LL(1) 、LR(0)、SLR、LR(1)、LALR文法的对比
- 终结符具有综合属性。
- 非终结符既可以有综合属性也可以有继承属性。
语法制导的翻译
- 每个文法产生式A 有一组形式为b = f(c1, c2, …, ck )的语义规则,其中f 是函数,b和c1, c2, …, ck 是该产生式文法符号的属性
综合属性:如果b是A的属性,c1 , c2 , …, ck 是产生式右部文法符号的属性或A的其它属性。
继承属性:如果b是产生式右部某个文法符号X的属性
问题详解
1.如何转为最简DFA?
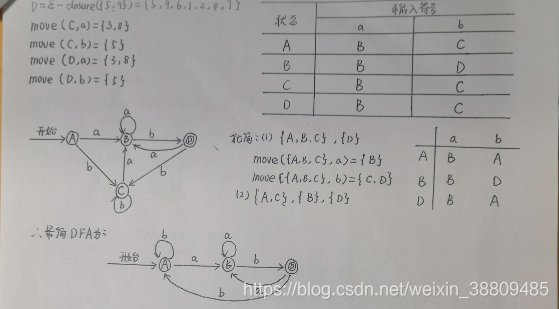
这里的最简化已懂:
就是在第一步分开的依据是:
- 把结束符(D)与其他符号区分开。
- 接下来,判断(A,B,C)这组,哪一个的输出对象与另外两个不一样。分开。即上面写的move操作。
- 分到最后,只要判断说,同一组的输出的对象无论是a,还是b都是一样的对象。就化简成功了,那两个一起的后面 就统一化简为其中的一个。
- 关键字、保留字和标准标识符的区别?
- 所谓标识符,就是指变量、函数、属性的名字,或者是函数的参数。
- 第一个字符必须是一个字母、下划线(_)或者是一个美元符号($),不能是数字。
第一个字符之后的其他字符可以是字母、下划线、美元符号或数字。
虽没有强制要求,但是我们习惯使用驼峰式来写标识符,如firstNumber。
- 第一个字符必须是一个字母、下划线(_)或者是一个美元符号($),不能是数字。
- 所谓关键字,就是在控制语句的开始或结束以及执行特定操作时具有关键作用、特定作用的符号。break do instanceof typeof case else new var catch finally return void continue for switch while debugger(第五版新增) function this with default if throw delete in try
- 所谓保留字,从字面意思上即可得知它是被保留的,将来可能被用作关键字,也就是说,现在它还没有特定的用途。虽然现在它们没有特定的用途,但是为了和未来的ECMAScript版本兼容,所以我门不建议将之作为标识符。implements package public interface private static let protected yield。
- 什么是正规式?
正规式 :
设∑是有穷字母表,并定义辅助字母表∑’={Φ, ε, | , . , , (, )}ε,Φ都是∑上的正规式,它们所表示的正规集为{ε}, Φ ;
任何a是一个正规式,若a∈∑,它所表示的正规集为{a};
如果R1和R2是正规式,它们表示的正规集分别为L1和L2,则 R1|R2 , R1·R2 , R1 , (R1) 也是正规式,并且它们所表示的正规集分别为L1∪L2 ;L1L2;L1* ; L1
仅有有限次使用上述三步骤而定义的表达式才是∑上的正规式,仅有这些正规式表示的字集才是∑上的正规集。
注意:不要混淆Φ和ε,正规表达式ε描述的语言只含一个空字符串ε,而Φ表示的语言不含有任何字符串。
其实,正规式应该也不用理解的太深,一般考试总不会去考正规式的概念吧! 因为书本是上的解释也很模糊其词,并且,书本上一般的式子都是正规式的。这功夫花在其他方面把!

这里的加号是什么意思?
*表示0到多个字符
+表示1->多个字符
闭包的概念:{a,b}的闭包:{空串,ab,aabb,aabb。。。。。}
4. LR(1)文法的搜索符该如何确定P83
例如:其实很简单




对这题主要还是翻译方案的构造不太清楚。


对上面这个参数在栈中的情况有问题。


这题主要对那个树感到有疑问。
10.** 如何判断是不是SLR?只能通过构造出整个项目集,判断有没有出现任何冲突,进而判断吗?**
11. ** 移进归约冲突 的含义?**
12. 下推自动机识别的语言是:2型文法
13. 在规范规约中,用句柄来刻画可规约串。
14. 左结合意味着:打断联系实行规约。右结合意味着:打断联系实行移进。
15. 在通常的语法分析方法中,算符优先分析法特别适合于表达式的分析。
16. NFA的终止状态是如何判断的。
17. 
习题

解析:原因是,编译器把这个fi当做一个函数名了,或者说一个标识符了,把(p%q==0)当做参数了,所以,直到编译器遇到return才了解到自己错了。
感觉没什么好讲的,至少上面那些截图的题目,是一定要掌握的。我把我的一些资料分享下吧。
https://www.lanzous.com/b555720















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









