




 Python是一门高级、动态类型的编程语言,广泛应用于控制台应用程序、音频视频软件、3D CAD、Web应用、企业级软件、图像处理、数据库操作、网络编程和邮件发送等多个领域。本文详细介绍了Python的安装、环境配置、面向对象编程(包括类和对象的创建、实例化、属性访问、类变量、实例变量、继承、销毁对象、运算符重载、数据隐藏和构造函数)以及异常处理、Python正则表达式、Python与MySQL数据库操作、网络编程、邮件发送等内容,旨在帮助读者深入理解和掌握Python的广泛应用和核心概念。
Python是一门高级、动态类型的编程语言,广泛应用于控制台应用程序、音频视频软件、3D CAD、Web应用、企业级软件、图像处理、数据库操作、网络编程和邮件发送等多个领域。本文详细介绍了Python的安装、环境配置、面向对象编程(包括类和对象的创建、实例化、属性访问、类变量、实例变量、继承、销毁对象、运算符重载、数据隐藏和构造函数)以及异常处理、Python正则表达式、Python与MySQL数据库操作、网络编程、邮件发送等内容,旨在帮助读者深入理解和掌握Python的广泛应用和核心概念。
Python是什么?
Python是面向对象,高级语言,解释,动态和多用途编程语言。Python易于学习,而且功能强大,功能多样的脚本语言使其对应用程序开发具有吸引力。
Python的语法和动态类型具有其解释性质,使其成为许多领域的脚本编写和快速应用程序开发的理想语言。
Python支持多种编程模式,包括面向对象编程,命令式和函数式编程或过程式编程。
Python几乎无所不能,一些常用的开发领域,如Web编程。这就是为什么它被称为多用途,因为它可以用于网络,企业,3D CAD等软件和系统开发。
在Python中,不需要使用数据类型来声明变量,因为它是动态类型的,所以可以写一个如 a=10 来声明一个变量a中的值是一个整数类型。
Python使开发和调试快速,因为在python开发中没有包含编译步骤,并且编辑 <-> 测试 <-> 调试循环使用代码开发效率非常高。
Python是一种高级,解释,交互和面向对象的脚本语言。 Python被设计为高度可读性。 它使用英语关键字,而其他语言使用标点符号。它的语法结构比其他语言少。
- Python是解释型语言 Python代码在解释器中运行时处理,执行前不需要编译程序。 这与PERL和PHP类似。
- Python是交动的 在Python提示符下面直接和解释器进行交互来编写程序。
- Python是面向对象的 Python支持面向对象的风格或编程技术,将代码封装在对象内。
- Python是一门初学者的语言 Python是初学者程序员的伟大语言,并支持从简单的文本处理到WWW浏览器到游戏的各种应用程序的开发。
Python可以开发哪些程序?
Python作为一个整体可以用于任何软件开发领域。下面来看看Python可以应用在哪些领域的开发。如下所列 -
1.基于控制台的应用程序
Python可用于开发基于控制台的应用程序。 例如:IPython。
2.基于音频或视频的应用程序
Python在多媒体部分开发,证明是非常方便的。 一些成功的应用是:TimPlayer,cplay等。
3.3D CAD应用程序
Fandango是一个真正使用Python编写的应用程序,提供CAD的全部功能。
4.Web应用程序
Python也可以用于开发基于Web的应用程序。 一些重要的开发案例是:PythonWikiEngines,Pocoo,PythonBlogSoftware等,如国内的成功应用案例有:豆瓣,知乎等。
5.企业级应用
Python可用于创建可在企业或组织中使用的应用程序。一些实时应用程序是:OpenErp,Tryton,Picalo等。
6.图像应用
使用Python可以开发图像应用程序。 开发的应用有:VPython,Gogh,imgSeek等
Python安装和环境配置
Python 3适用于Windows,Mac OS和大多数Linux操作系统。即使Python 2目前可用于许多其他操作系统,有部分系统Python 3还没有提供支持或者支持了但被它们在系统上删除了,只保留旧的Python 2版本。
在本教程中,我们重点讲解如何在 Windows 10 和 Ubuntu 系统上安装 Python 3 的最新版本(当前新版本:Python 3.6.1)。
在Windows 10上安装Python 3
最新版本的Python 3(Python 3.5.1)的二进制文件可从Python官方网站的下载页面: http://www.python.org/downloads/windows/ 下载,可以使用以下不同的安装选项 -

这里选择: 下载Windows x86-64 executable installer 下载。下载完成后,双击 python-3.6.1-amd64.exe 可执行文件。
第一步:双击 python-3.6.1-amd64.exe 可执行文件,如下所示 -

第二步:选择“Cusomize installation“,如下所示 -

第三步:选择“Next>“,这里选择安装在 D:\Program Files\Python36,如下所示 -

第四步:开始安装 “Install“ ,如下 -

第五步:安装完成后选择关闭(Close),如下所示 -

测试安装结果
由于我们在安装的第一步中,已经选择了“Add Python 3.6 to PATH”了,所以这里不需要单独去设置环境变量了。如果没有选择此项,则应该需要将Python 3.6添加到环境变量。
假设您已经按照上面的步骤来安装完成,现在打开命令提示符,并在其中输入 python,然后回车 -

到此,在 Windows 10 系统上安装 Python 3.6 已经完成了。
在Ubuntu上安装Python 3
首先来看看当 Ubuntu 系统上安装的是什么版本的 Python,在终端上输入 python,如下所示 -
yiibai@ubuntu:~$ python -version
The program 'python' can be found in the following packages:
* python-minimal
* python3
Try: sudo apt install <selected package>
yiibai@ubuntu:~$在上面显示结果中,还没有安装 Python 。
第一种情况:
如果使用的是Ubuntu 14.04或16.04,则可以使用J Fernyhough的PPA: http://launchpad.net/~jonathonf/+archive/ubuntu/python-3.6 来安装Python 3.6:
sudo add-apt-repository ppa:jonathonf/python-3.6
sudo apt-get update
sudo apt-get install python3.6第二种情况:
如果使用的是Ubuntu 16.10或17.04,则Python 3.6位于Universe存储库中,直接升级 apt-get,然后再安装即可 -
sudo apt-get update
sudo apt-get install python3.6现在,查看 Ubuntu 的当前版本 -
yiibai@ubuntu:~$ sudo lsb_release -a
[sudo] password for yiibai:
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 16.04.1 LTS
Release: 16.04
Codename: xenial
yiibai@ubuntu:~$提示:Ubuntu无法找到add-apt-repository问题的解决方法,执行安装命令:apt-get install python-software-properties,除此之外还要安装 apt-get install software-properties-common,然后就能用add-apt-repository了。
根据上面显示的系统信息,系统版本是:Ubuntu 16.04.1 LTS,所以属于第一种情况安装 Python 3.6,所以完整的安装步骤如下 -
sudo apt-get install python-software-properties
sudo apt-get install software-properties-common
sudo add-apt-repository ppa:jonathonf/python-3.6
sudo apt-get update
sudo apt-get install python3.6注意,上面命令执行可能会出现中断或错误的情况,可尝试多执行几次。
当上面命令成功执行完成后,默认情况下,它也会安装了一个 Python 2.7,在命令行提示符下输入:python,那么它使用的是 Python 2.7,如果要使用 Python 3.6,那么可以直接输入:python3.6,验证安装结果如下所示 -

从源代码编译安装 Python 3.6
或者,如果您有时间和精力,也可以尝试从源代码编译来安装 Python 3.6 。源代码下载地址:http://www.python.org/ftp/python/3.6.1/
首先,需要使用以下命令安装一些构建依赖项。
sudo apt install build-essential checkinstall
sudo apt install libreadline-gplv2-dev libncursesw5-dev libssl-dev libsqlite3-dev tk-dev libgdbm-dev libc6-dev libbz2-dev然后,从python.org下载Python 3.6源代码。
wget http://www.python.org/ftp/python/3.6.0/Python-3.6.0.tar.xz接下来,解压缩tarball。
tar xvf Python-3.6.0.tar.xz现在cd进入源目录,配置构建环境并进行安装。
cd Python-3.6.0/
./configure
sudo make altinstall使altinstall命令跳过创建符号链接,所以/usr/bin/python仍然指向旧版本的Python,保证Ubuntu系统将不会中断。
完成完成后,可以通过键入以下命令来使用Python 3.6:
$ python3.6以下是所有可用命令行选项的列表 -
| 编号 | 选项 | 说明 |
|---|---|---|
| 1 | -d | 提供调试输出 |
| 2 | -O | 生成优化的字节码(结果为.pyo文件) |
| 3 | -S | 启动时不要运行导入站点来寻找Python路径 |
| 4 | -v | 详细输出(import语句的详细跟踪) |
| 5 | -X | 禁用基于类的内置异常(仅使用字符串); 从版本1.6开始已经过时了 |
| 6 | -c cmd | 运行Python脚本作为cmd字符串发送 |
| 7 | file | 从给定运行的Python脚本文件 |
命令行脚本
通过在应用程序中调用解释器,可以在命令行中执行Python脚本,如以下示例所示。
$python script.py # Unix/Linux
or
python% script.py # Unix/Linux
or
C:>python script.py # Windows/DOS注意 - 确保文件权限模式允许执行。
集成开发环境
如果您的系统上支持Python的GUI应用程序,也可以从图形用户界面(GUI)环境运行Python。
Unix - IDLE是第一个用于Python的Unix IDE。
Windows - PythonWin是Python的第一个Windows图形用户界面,是具有GUI的IDE。
Macintosh - Macintosh版本的Python以及IDLE IDE可从主网站获取,可作为MacBinary或BinHex’d文件下载。
如果您无法正确设置环境,则可以通过向系统管理员寻求帮助。确保Python环境设置正确,以正常工作。
注 - 后续章节中给出的所有示例都是使用Windows 7和Ubuntu Linux上提供的Python 3.6.1版本来执行。
Python面向对象(类和对象)
自从存在以来,Python一直是面向对象的语言。 因此,创建和使用类和对象是非常容易的。 本章将学习如何使用Python面向对象编程。
如果您以前没有面向对象(OO)编程的经验,可能需要查阅介绍面向对象(OO)编程课程或至少学习一些有关教程,以便掌握基本概念。
下面是面向对象编程(OOP)的一个小介绍,以帮助您快速入门学习 -
OOP术语概述
类 -
用于定义表示用户定义对象的一组属性的原型。属性是通过点符号访问的数据成员(类变量和实例变量)和方法。类变量
由类的所有实例共享的变量。 类变量在类中定义,但在类的任何方法之外。 类变量不像实例变量那样频繁使用。数据成员 -
保存与类及其对象相关联的数据的类变量或实例变量。函数重载 -
将多个行为分配给特定函数。 执行的操作因涉及的对象或参数的类型而异。实例变量 -
在方法中定义并仅属于类的当前实例的变量。继承 -
将类的特征传递给从其派生的其他类。实例 -
某个类的单个对象。 例如,对象obj属于Circle类,它是Circle类的实例。实例化 -
创建类的实例。方法 -
在类定义中定义的一种特殊类型的函数。对象 -
由其类定义的数据结构的唯一实例。对象包括数据成员(类变量和实例变量)和方法。运算符重载 -
将多个函数分配给特定的运算符。
1.创建类
class语句创建一个新的类定义。 类的名称紧跟在class关键字之后,在类的名称之后紧跟冒号,如下 -
class ClassName:
'Optional class documentation string'
class_suite- 该类有一个文档字符串,可以通过ClassName.doc访问。
- class_suite由定义类成员,数据属性和函数的所有组件语句组成。
示例
以下是一个简单的Python类的例子 -
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print ("Total Employee %d" % Employee.empCount)
def displayEmployee(self):
print ("Name : ", self.name, ", Salary: ", self.salary)- 变量empCount是一个类变量,其值在此类中的所有实例之间共享。 这可以从类或类之外的Employee.empCount访问。
- 第一个方法init ()是一种特殊的方法,当创建此类的新实例时,该方法称为Python构造函数或初始化方法。
声明其他类方法,如正常函数,但每个方法的第一个参数是self。 Python将self参数添加到列表中; 调用方法时不需要包含它。
2.创建实例对象
要创建类的实例,可以使用类名调用该类,并传递其init方法接受的任何参数。
## This would create first object of Employee class
emp1 = Employee("Maxsu", 2000)
## This would create second object of Employee class
emp2 = Employee("Kobe", 5000)3.访问属性
可以使用带有对象的点(.)运算符来访问对象的属性。 类变量将使用类名访问如下 -
emp1.displayEmployee()
emp2.displayEmployee()
print ("Total Employee %d" % Employee.empCount)现在把所有的概念放在一起 -
#!/usr/bin/python3
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print ("Total Employee %d" % Employee.empCount)
def displayEmployee(self):
print ("Name : ", self.name, ", Salary: ", self.salary)
#This would create first object of Employee class"
emp1 = Employee("Maxsu", 2000)
#This would create second object of Employee class"
emp2 = Employee("Kobe", 5000)
emp1.displayEmployee()
emp2.displayEmployee()
print ("Total Employee %d" % Employee.empCount)当执行上述代码时,会产生以下结果 -
Name : Maxsu ,Salary: 2000
Name : Kobe ,Salary: 5000
Total Employee 2可以随时添加,删除或修改类和对象的属性 -
emp1.salary = 7000 # Add an 'salary' attribute.
emp1.name = 'xyz' # Modify 'age' attribute.
del emp1.salary # Delete 'age' attribute.如果不是使用普通语句访问属性,可以使用以下函数 -
- getattr(obj,name [,default]) - 访问对象的属性。
- hasattr(obj,name) - 检查属性是否存在。
- setattr(obj,name,value) - 设置一个属性。如果属性不存在,那么它将被创建。
- delattr(obj,name) - 删除一个属性。
下面是一此使用示例 -
hasattr(emp1, 'salary') # Returns true if 'salary' attribute exists
getattr(emp1, 'salary') # Returns value of 'salary' attribute
setattr(emp1, 'salary', 7000) # Set attribute 'salary' at 7000
delattr(emp1, 'salary') # Delete attribute 'salary'3.内置类属性
每个Python类保持以下内置属性,并且可以像任何其他属性一样使用点运算符访问它们 -
- dict - 包含该类的命名空间的字典。
- doc - 类文档字符串或无,如果未定义。
- name - 类名。
- module - 定义类的模块名称。此属性在交互模式下的值为“main”。
- bases - 一个包含基类的空元组,按照它们在基类列表中出现的顺序。
对于上述类,尝试访问所有这些属性 -
#!/usr/bin/python3
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print ("Total Employee %d" % Employee.empCount)
def displayEmployee(self):
print ("Name : ", self.name, ", Salary: ", self.salary)
emp1 = Employee("Maxsu", 2000)
emp2 = Employee("Bryant", 5000)
print ("Employee.__doc__:", Employee.__doc__)
print ("Employee.__name__:", Employee.__name__)
print ("Employee.__module__:", Employee.__module__)
print ("Employee.__bases__:", Employee.__bases__)
print ("Employee.__dict__:", Employee.__dict__ )当执行上述代码时,会产生以下结果 -
Employee.__doc__: Common base class for all employees
Employee.__name__: Employee
Employee.__module__: __main__
Employee.__bases__: (<class 'object'>,)
Employee.__dict__: {
'displayCount': <function Employee.displayCount at 0x0160D2B8>,
'__module__': '__main__', '__doc__': 'Common base class for all employees',
'empCount': 2, '__init__':
<function Employee.__init__ at 0x0124F810>, 'displayEmployee':
<function Employee.displayEmployee at 0x0160D300>,
'__weakref__':
<attribute '__weakref__' of 'Employee' objects>, '__dict__':
<attribute '__dict__' of 'Employee' objects>
}4.销毁对象(垃圾收集)
Python自动删除不需要的对象(内置类型或类实例)以释放内存空间。 Python定期回收不再使用的内存块的过程称为垃圾收集。
Python的垃圾收集器在程序执行期间运行,当对象的引用计数达到零时触发。 对象的引用计数随着指向它的别名数量而变化。
当对象的引用计数被分配一个新名称或放置在容器(列表,元组或字典)中时,它的引用计数会增加。 当用del删除对象的引用计数时,引用计数减少,其引用被重新分配,或者其引用超出范围。 当对象的引用计数达到零时,Python会自动收集它。
a = 40 # Create object <40>
b = a # Increase ref. count of <40>
c = [b] # Increase ref. count of <40>
del a # Decrease ref. count of <40>
b = 100 # Decrease ref. count of <40>
c[0] = -1 # Decrease ref. count of <40>通常情况下,垃圾回收器会销毁孤立的实例并回收其空间。 但是,类可以实现调用析构函数的特殊方法del(),该方法在实例即将被销毁时被调用。 此方法可能用于清理实例使用的任何非内存资源。
示例
这个del()析构函数打印要被销毁的实例的类名 -
#!/usr/bin/python3
class Point:
def __init__( self, x=0, y=0):
self.x = x
self.y = y
def __del__(self):
class_name = self.__class__.__name__
print (class_name, "destroyed")
pt1 = Point()
pt2 = pt1
pt3 = pt1
print (id(pt1), id(pt2), id(pt3)); # prints the ids of the obejcts
del pt1
del pt2
del pt3当执行上述代码时,会产生以下结果 -
3083401324 3083401324 3083401324
Point destroyed注意 - 理想情况下,应该在单独的文件中定义类,然后使用import语句将其导入主程序文件。
在上面的例子中,假定Point类的定义包含在point.py中,并且其中没有其他可执行代码。
#!/usr/bin/python3
import point
p1 = point.Point()5.类继承
使用类继承不用从头开始构建代码,可以通过在新类名后面的括号中列出父类来从一个预先存在的类派生它来创建一个类。
子类继承其父类的属性,可以像子类中一样定义和使用它们。子类也可以从父类代替代数据成员和方法。
语法
派生类被声明为很像它们的父类; 然而,继承的基类的列表在类名之后给出 -
class SubClassName (ParentClass1[, ParentClass2, ...]):
'Optional class documentation string'
class_suite示例
#!/usr/bin/python3
class Parent: # define parent class
parentAttr = 100
def __init__(self):
print ("Calling parent constructor")
def parentMethod(self):
print ('Calling parent method')
def setAttr(self, attr):
Parent.parentAttr = attr
def getAttr(self):
print ("Parent attribute :", Parent.parentAttr)
class Child(Parent): # define child class
def __init__(self):
print ("Calling child constructor")
def childMethod(self):
print ('Calling child method')
c = Child() # instance of child
c.childMethod() # child calls its method
c.parentMethod() # calls parent's method
c.setAttr(200) # again call parent's method
c.getAttr() # again call parent's method当执行上述代码时,会产生以下结果 -
Calling child constructor
Calling child method
Calling parent method
Parent attribute : 200以类似的方式,可以从多个父类来构建一个新的类,如下所示:
class A: # define your class A
.....
class B: # define your calss B
.....
class C(A, B): # subclass of A and B
.....可以使用issubclass()或isinstance()函数来检查两个类和实例之间的关系。
- issubclass(sub,sup)布尔函数如果给定的子类sub确实是超类sup的子类返回True。
- isinstance(obj,Class)布尔函数如果obj是类Class的一个实例,或者是类的一个子类的实例则返回True。
重载方法
可以随时重载父类的方法。 重载父方法的一个原因是:您可能希望在子类中使用特殊或不同的方法功能。
示例
#!/usr/bin/python3
class Parent: # define parent class
def myMethod(self):
print ('Calling parent method')
class Child(Parent): # define child class
def myMethod(self):
print ('Calling child method')
c = Child() # instance of child
c.myMethod() # child calls overridden method当执行上述代码时,会产生以下结果 -
Calling child method基本重载方法
下表列出了可以在自己的类中覆盖的一些通用方法 -
| 编号 | 方法 | 描述 | 调用示例 |
|---|---|---|---|
| 1 | init ( self [,args…] ) | 构造函数(带任意可选参数) | obj = className(args) |
| 2 | del( self ) | 析构函数,删除一个对象 | del obj |
| 3 | repr( self ) | 可评估求值的字符串表示 | repr(obj) |
| 4 | str( self ) | 可打印的字符串表示 | str(obj) |
| 5 | cmp ( self, x ) | 对象比较 | cmp(obj, x) |
6.重载运算符
假设已经创建了一个Vector类来表示二维向量。当使用加号(+)运算符执行运算时,它们会发生什么? 很可能Python理解不了你想要做什么。
但是,可以在类中定义add方法来执行向量加法,然后将按照期望行为那样执行加法运算 -
示例
#!/usr/bin/python3
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print (v1 + v2)当执行上述代码时,会产生以下结果 -
Vector(7,8)7.数据隐藏
对象的属性在类定义之外可能或不可见。需要使用双下划线前缀命名属性,然后这些属性将不会直接对外部可见。
示例
#!/usr/bin/python3
class JustCounter:
__secretCount = 0
def count(self):
self.__secretCount += 1
print (self.__secretCount)
counter = JustCounter()
counter.count()
counter.count()
print (counter.__secretCount)当执行上述代码时,会产生以下结果 -
1
2
Traceback (most recent call last):
File "test.py", line 12, in <module>
print counter.__secretCount
AttributeError: JustCounter instance has no attribute '__secretCount'Python通过内部更改名称来包含类名称来保护这些成员。 可以访问object._className__attrName等属性。如果将最后一行替换为以下,那么它适用于 -
.........................
print (counter._JustCounter__secretCount)当执行上述代码时,会产生以下结果 -
1
2
2Python构造函数
构造函数是一种特殊类型的方法(函数),它在类的实例化对象时被调用。 构造函数通常用于初始化(赋值)给实例变量。 构造函数还验证有足够的资源来使对象执行任何启动任务。
创建一个构造函数
构造函数是以双下划线()开头的类函数。构造函数的名称是__init()。
创建对象时,如果需要,构造函数可以接受参数。当创建没有构造函数的类时,Python会自动创建一个不执行任何操作的默认构造函数。
每个类必须有一个构造函数,即使它只依赖于默认构造函数。
举一个例子:
创建一个名为ComplexNumber的类,它有两个函数init()函数来初始化变量,并且有一个getData()方法用来显示数字。
看这个例子:
#!/usr/bin/python3
#coding=utf-8
class ComplexNumber:
def __init__(self, r = 0, i = 0):
""""初始化方法"""
self.real = r
self.imag = i
def getData(self):
print("{0}+{1}j".format(self.real, self.imag))
if __name__ == '__main__':
c = ComplexNumber(5, 6)
c.getData()执行上面代码,得到以下结果 -
5+6j可以为对象创建一个新属性,并在定义值时进行读取。但是不能为已创建的对象创建属性。
看这个例子:
#!/usr/bin/python3
#coding=utf-8
class ComplexNumber:
def __init__(self, r = 0, i = 0):
""""初始化方法"""
self.real = r
self.imag = i
def getData(self):
print("{0}+{1}j".format(self.real, self.imag))
if __name__ == '__main__':
c = ComplexNumber(5, 6)
c.getData()
c2 = ComplexNumber(10, 20)
# 试着赋值给一个未定义的属性
c2.attr = 120
print("c2 = > ", c2.attr)
print("c.attr => ", c.attr)执行上面代码,得到以下结果 -
5+6j
c2 = > 120
Traceback (most recent call last):
File "D:\test.py", line 23, in <module>
print("c.attr => ", c.attr)
AttributeError: 'ComplexNumber' object has no attribute 'attr'Python继承
什么是继承?
继承用于指定一个类将从其父类获取其大部分或全部功能。 它是面向对象编程的一个特征。 这是一个非常强大的功能,方便用户对现有类进行几个或多个修改来创建一个新的类。新类称为子类或派生类,从其继承属性的主类称为基类或父类。
子类或派生类继承父类的功能,向其添加新功能。 它有助于代码的可重用性。
下图表示:


语法-1
class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-N>语法-2
class DerivedClassName(modulename.BaseClassName):
<statement-1>
.
.
.
<statement-N>参数说明
必须在包含派生类定义的范围中定义名称BaseClassName。还可以使用其他任意表达式代替基类名称。 当在另一个模块中定义基类时要指定模块的名称。
Python继承示例
我们来看一个简单的python继承示例,在这个示例中使用两个类:Animal和Dog。Animal是父类或基类,Dog是Animal的子类。
在这里,在Animal类中定义了eat()方法,Dog类中定义了bark()方法。 在这个例子中,我们创建Dog类的实例,并且仅通过子类的实例调用eat()和bark()方法。 由于父属性和行为自动继承到子对象,所以通过子实例也可以调用父类和子类的方法。
class Animal:
def eat(self):
print 'Eating...'
class Dog(Animal):
def bark(self):
print 'Barking...'
d=Dog()
d.eat()
d.bark()执行上面代码,得到以下结果 -
Eating...
Barking...Python多重继承
在本文中,您将了解Python中的多重继承以及如何在程序中使用它。还将了解多级继承和方法解析顺序。

与C++一样,一个类可以从Python中的多个基类派生出来。这被称为多重继承。
在多重继承中,所有基类的特征都被继承到派生类中。多重继承的语法类似于单继承。
Python多重继承示例
class Base1:
pass
class Base2:
pass
class MultiDerived(Base1, Base2):
pass这里,MultiDerived派生自Base1和Base2类。

MultiDerived类从Base1和Base2继承。
Python中的多层继承
另一方面,我们也可以继承一个派生类的形式。这被称为多级继承。 它可以在Python中有任何的深度(层级)。在多级继承中,基类和派生类的特性被继承到新的派生类中。
下面给出了具有相应可视化的示例。
class Base:
pass
class Derived1(Base):
pass
class Derived2(Derived1):
pass这里,Derived1派生自Base,Derived2派生自Derived1。

Python中的方法解析顺序
Python中的每个类都派生自类:object。它是Python中最基础的类型。
所以在技术上,所有其他类,无论是内置还是用户定义,都是派生类,所有对象都是对象类的实例。
# Output: True
print(issubclass(list,object))
# Output: True
print(isinstance(5.5,object))
# Output: True
print(isinstance("Hello",object))在多继承方案中,在当前类中首先搜索任何指定的属性。如果没有找到,搜索继续进入父类,深度优先,再到左右的方式,而不需要搜索相同的类两次。
所以在MultiDerived类的上面的例子中,搜索顺序是[MultiDerived,Base1,Base2,object]。 此顺序也称为MultiDerived类的线性化,用于查找此顺序的一组规则称为方法解析顺序(MRO)。
MRO必须防止本地优先排序,并提供单调性。它确保一个类总是出现在其父类之前,并且在多个父类的情况下,该顺序与基类的元组相同。
一个类的MRO可以被看作是mro属性或者mro()方法。前者返回一个元组,而后者返回一个列表。
>>> MultiDerived.__mro__
(<class '__main__.MultiDerived'>,
<class '__main__.Base1'>,
<class '__main__.Base2'>,
<class 'object'>)
>>> MultiDerived.mro()
[<class '__main__.MultiDerived'>,
<class '__main__.Base1'>,
<class '__main__.Base2'>,
<class 'object'>]这里有一个更复杂的多重继承示例及其可视化图型。
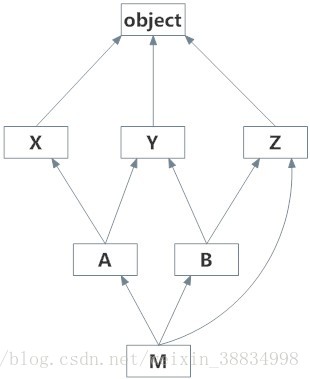
class X: pass
class Y: pass
class Z: pass
class A(X,Y): pass
class B(Y,Z): pass
class M(B,A,Z): pass
# Output:
# [<class '__main__.M'>, <class '__main__.B'>,
# <class '__main__.A'>, <class '__main__.X'>,
# <class '__main__.Y'>, <class '__main__.Z'>,
# <class 'object'>]
print(M.mro())参考这一点,进一步讨论MRO并了解实际算法如何计算。
Python操作符重载
可以根据所使用的操作数更改Python中运算符的含义。这种做法被称为运算符重载。
Python操作系统适用于内置类。 但同一运算符的行为在不同的类型有所不同。 例如,+运算符将对两个数字执行算术加法,合并两个列表并连接两个字符串。
Python中的这个功能,允许相同的操作符根据上下文的不同,其含义称为运算符重载。
那么当将它们与用户定义的类的对象一起使用时会发生什么? 考虑下面的类,它试图模拟二维坐标系中的一个点。
class Point:
def __init__(self, x = 0, y = 0):
self.x = x
self.y = y现在,运行代码,尝试在Python shell中添加两点。
>>> p1 = Point(2,3)
>>> p2 = Point(-1,2)
>>> p1 + p2
Traceback (most recent call last):
TypeError: unsupported operand type(s) for +: 'Point' and 'Point'Python中的特殊功能
以双下划线_ 开头的类函数在Python中称为特殊函数。 这是因为,它们是有特殊含义。 上面定义的 _ init__()函数是其中之一。 每次创建该类的新对象时都会调用它。 Python中有很多特殊功能。
使用特殊功能,可以使类与内置函数兼容。
>>> p1 = Point(2,3)
>>> print(p1)
<__main__.Point object at 0x00000000031F8CC0>但是如果打印不好或不够美观。可以在类中定义str()方法,可以控制它如何打印。 所以,把它添加到类中,如下代码 -
class Point:
def __init__(self, x = 0, y = 0):
self.x = x
self.y = y
def __str__(self):
return "({0},{1})".format(self.x,self.y)现在再试一次调用print()函数。
>>> p1 = Point(2,3)
>>> print(p1)
(2,3)当使用内置函数str()或format()时,调用同样的方法。
>>> str(p1)
'(2,3)'
>>> format(p1)
'(2,3)'所以,当执行str(p1)或format(p1),Python在内部执行p1._ str_()。
在Python中重载+运算符
要重载+号,需要在类中实现add()函数。可以在这个函数里面做任何喜欢的事情。 但是返回Point对象的坐标之和是最合理的。
class Point:
def __init__(self, x = 0, y = 0):
self.x = x
self.y = y
def __str__(self):
return "({0},{1})".format(self.x,self.y)
def __add__(self,other):
x = self.x + other.x
y = self.y + other.y
return Point(x,y)现在让我们再试一次运行上面的代码 -
>>> p1 = Point(2,3)
>>> p2 = Point(-1,2)
>>> print(p1 + p2)
(1,5)实际发生的是,当执行p1 + p2语句时,Python将调用p1._ add_(p2),之后是Point.add(p1,p2)。 同样,也可以重载其他运算符。需要实现的特殊功能列在下面。
Python中的运算符重载特殊函数 -
| 运算符 | 表达式 | 内置函数 |
|---|---|---|
| 加法 | p1 + p2 | p1._ add_(p2) |
| 减法 | p1 - p2 | p1._ sub_(p2) |
| 乘法 | p1 * p2 | p1.mul(p2) |
| 次幂 | p1 ** p2 | p1._ pow_(p2) |
| 除法 | p1 / p2 | p1._ truediv_(p2) |
| 地板除法 | p1 // p2 | p1._ floordiv_(p2) |
| 模 (modulo) | p1 % p2 | p1._ mod_(p2) |
| 按位左移 | p1 << p2 | p1._ lshift_(p2) |
| 按位右移 | p1 >> p2 | p1._ rshift_(p2) |
| 按位AND | p1 & p | p1._ and_(p2) |
| 按位OR | p1 or p2 | p1 ._ or_(p2) |
| 按位XOR | p1 ^ p2 | p1._ xor_(p2) |
| 按位NOT | `~p1 | p1.invert() ` |
在Python中重载比较运算符
Python不会限制操作符重载算术运算符。也可以重载比较运算符。
假设想在Point类中实现小于符号<比较运算。
比较这些来自原点的数值,并为此返回结果。 可以实现如下。
class Point:
def __init__(self, x = 0, y = 0):
self.x = x
self.y = y
def __str__(self):
return "({0},{1})".format(self.x,self.y)
def __lt__(self,other):
self_mag = (self.x ** 2) + (self.y ** 2)
other_mag = (other.x ** 2) + (other.y ** 2)
return self_mag < other_mag在Python shell中尝试这些示例运行。
>>> Point(1,1) < Point(-2,-3)
True
>>> Point(1,1) < Point(0.5,-0.2)
False
>>> Point(1,1) < Point(1,1)
False类似地,可以实现的特殊功能,以重载其他比较运算符,如下表所示。
| 运算符 | 表达式 | 内置函数 |
|---|---|---|
| 小于 | p1 < p2 | p1._ lt_(p2) |
| 小于或等于 | p1 <= p2 | p1._ le_(p2) |
| 等于 | p1 == p2 | p1._ eq_(p2) |
| 不等于 | p1 != p2 | p1._ ne_(p2) |
| 大于 | p1 > p2 | p1._ gt_(p2) |
| 大于或等于 | p1 >= p2 | p1._ ge_(p2) |
Python异常处理
Python提供了两个非常重要的功能来处理Python程序中的异常和错误,并在其中添加调试的函数功能 -
- 异常处理 - 在本教程中介绍。这是一个列表标准Python中提供的异常 - 标准异常。
- 断言 - 在Python 3教程中的断言中介绍。
标准异常
以下是Python中可用的标准异常列表 -
| 编号 | 异常名称 | 描述 |
|---|---|---|
| 1 | Exception | 所有异常的基类 |
| 2 | StopIteration | 当迭代器的next()方法没有指向任何对象时引发。 |
| 3 | SystemExit | 由sys.exit()函数引发。 |
| 4 | StandardError | 除StopIteration和SystemExit之外的所有内置异常的基类。 |
| 5 | ArithmeticError | 数据计算出现的所有错误的基类。 |
| 6 | OverflowError | 当计算超过数字类型的最大限制时引发。 |
| 7 | FloatingPointError | 当浮点计算失败时触发。 |
| 8 | ZeroDivisonError | 对于所有的数字类型,当对零进行除数或模数时产生。 |
| 9 | AssertionError | 在Assert语句失败的情况下引发。 |
| 10 | AttributeError | 在属性引用或分配失败的情况下引发。 |
| 11 | EOFError | 当没有来自raw_input()或input()函数的输入并且达到文件结尾时引发。 |
| 12 | ImportError | 导入语句失败时引发。 |
| 13 | KeyboardInterrupt | 当用户中断程序执行时,通常按Ctrl + c。 |
| 14 | LookupError | 所有查找错误的基类。 |
| 15 | IndexError | 当序列中没有找到索引时引发。 |
| 16 | KeyError | 当在字典中找不到指定的键时引发。 |
| 17 | NameError | 当在本地或全局命名空间中找不到标识符时引发。 |
| 18 | UnboundLocalError | 当尝试访问函数或方法中的局部变量但未分配值时引发。 |
| 19 | EnvironmentError | 在Python环境之外发生的所有异常的基类。 |
| 20 | IOError | 在尝试打开不存在的文件时,输入/输出操作失败时触发,例如print语句或open()函数。 |
| 21 | OSError | 引起操作系统相关的错误。 |
| 22 | SyntaxError | 当Python语法有错误时引发。 |
| 23 | IndentationError | 当缩进未正确指定时触发。 |
| 24 | SystemError | 当解释器发现内部问题时引发,但遇到此错误时,Python解释器不会退出。 |
| 25 | SystemExit | 当Python解释器通过使用sys.exit()函数退出时引发。 如果没有在代码中处理,导致解释器退出。 |
| 26 | TypeError | 在尝试对指定数据类型无效的操作或函数时引发。 |
| 27 | ValueError | 当数据类型的内置函数具有有效参数类型时引发,但参数具有指定的无效值。 |
| 28 | RuntimeError | 产生的错误不属于任何类别时引发。 |
| 29 | NotImplementedError | 当需要在继承类中实现的抽象方法实际上没有实现时引发。 |
Python中的断言
断言是一个健全检查,可以在完成对程序的测试后打开或关闭。
- 试想断言的最简单的方法就是将它与一个raise-if语句(或者更准确的说是一个加注if语句)相对应。测试表达式,如果结果为false,则会引发异常。
- 断言由版本1.5引入的assert语句来执行,它是Python的最新关键字。
- 程序员经常在函数开始时放置断言来检查有效的输入,并在函数调用后检查有效的输出。
assert语句
当它遇到一个assert语句时,Python会评估求值它的的表达式,是否为所希望的那样。 如果表达式为false,Python会引发AssertionError异常。
assert的语法是 -
assert Expression[, Arguments]如果断言失败,Python将使用ArgumentExpression作为AssertionError的参数。 使用try-except语句可以像任何其他异常一样捕获和处理AssertionError异常。 如果没有处理,它们将终止程序并产生回溯。
示例
这里将实现一个功能:将给定的温度从开尔文转换为华氏度。如果是负温度,该功能将退出 -
#!/usr/bin/python3
def KelvinToFahrenheit(Temperature):
assert (Temperature >= 0),"Colder than absolute zero!"
return ((Temperature-273)*1.8)+32
print (KelvinToFahrenheit(273))
print (int(KelvinToFahrenheit(505.78)))
print (KelvinToFahrenheit(-5))当执行上述代码时,会产生以下结果 -
32.0
451
Traceback (most recent call last):
File "test.py", line 9, in <module>
print KelvinToFahrenheit(-5)
File "test.py", line 4, in KelvinToFahrenheit
assert (Temperature >= 0),"Colder than absolute zero!"
AssertionError: Colder than absolute zero!什么是异常?
一个例外是在程序执行期间发生的一个事件,它破坏程序指令的正常流程。 一般来说,当Python脚本遇到无法应对的情况时,会引发异常。异常是一个表示错误的Python对象。
当Python脚本引发异常时,它必须立即处理异常,否则终止并退出。
处理异常
如果有一些可能引发异常的可疑代码,可以通过将可疑代码放在try:块中来保护您的程序。 在try:块之后,包括一个except:语句,然后是一个尽可能优雅地处理问题的代码块。
语法
下面是简单的语法try …. except … else块 -
try:
You do your operations here
......................
except ExceptionI:
If there is ExceptionI, then execute this block.
except ExceptionII:
If there is ExceptionII, then execute this block.
......................
else:
If there is no exception then execute this block.以下是上述语法的几个重点 -
- 一个try语句可以有多个except语句。 当try块包含可能引发不同类型的异常的语句时,这就很有用。
- 还可以提供一个通用的except子句,它处理任何异常。
- 在except子句之后,可以包含一个else子句。 如果try:block中的代码不引发异常,则else块中的代码将执行。
- else-block是一个不需要try:block保护的代码的地方。
示例
此示例打开一个文件,将内容写入文件,并且优雅地出现,因为完全没有问题 -
#!/usr/bin/python3
try:
fh = open("testfile", "w")
fh.write("This is my test file for exception handling!!")
except IOError:
print ("Error: can\'t find file or read data")
else:
print ("Written content in the file successfully")
fh.close()这产生以下结果 -
Written content in the file successfully示例
此示例尝试打开一个没有写入权限的文件,因此它引发了一个异常 -
#!/usr/bin/python3
try:
fh = open("testfile", "r")
fh.write("This is my test file for exception handling!!")
except IOError:
print ("Error: can\'t find file or read data")
else:
print ("Written content in the file successfully")这产生以下结果 -
Error: can't find file or read dataexcept子句没有指定异常
也可以使用except语句,但不定义异常,如下所示 -
try:
You do your operations here
......................
except:
If there is any exception, then execute this block.
......................
else:
If there is no exception then execute this block.这种try-except语句捕获所有发生的异常。使用这种try-except语句不被认为是一个很好的编程实践,因为它捕获所有异常,但不会让程序员能更好地识别发生的问题的根本原因。
except子句指定多个异常
还可以使用相同的except语句来处理多个异常,如下所示:
try:
You do your operations here
......................
except(Exception1[, Exception2[,...ExceptionN]]]):
If there is any exception from the given exception list,
then execute this block.
......................
else:
If there is no exception then execute this block.try-finally子句
可以使用finally:块和try:块。 finally:块是放置必须执行代码的地方,无论try块是否引发异常。 try-finally语句的语法是这样的 -
try:
You do your operations here;
......................
Due to any exception, this may be skipped.
finally:
This would always be executed.
......................注意 - 可以提供except子句或finally子句,但不能同时提供。不能使用else子句以及finally子句。
示例
#!/usr/bin/python3
try:
fh = open("testfile", "w")
fh.write("This is my test file for exception handling!!")
finally:
print ("Error: can\'t find file or read data")
fh.close()如果没有以写入形式打开文件的权限,则会产生以下结果 -
Error: can't find file or read data同样的例子可以写得更干净如下 -
#!/usr/bin/python3
try:
fh = open("testfile", "w")
try:
fh.write("This is my test file for exception handling!!")
finally:
print ("Going to close the file")
fh.close()
except IOError:
print ("Error: can\'t find file or read data")当try块中抛出异常时,执行将立即传递给finally块。 在finally块中的所有语句都被执行之后,异常被再次引发,如果存在于try-except语句的下一个更高的层中,则在except语句中处理异常。
异常参数
一个异常可以有一个参数,参数它是一个值,它提供有关该问题的其他信息。 参数的内容因异常而异。 可以通过在except子句中提供变量来捕获异常的参数,如下所示:
try:
You do your operations here
......................
except ExceptionType as Argument:
You can print value of Argument here...如果编写代码来处理单个异常,则可以在except语句中使用一个变量后跟异常的名称。 如果要捕获多个异常,可以使用一个变量后跟随异常的元组。
此变量接收大部分包含异常原因的异常值。 变量可以以元组的形式接收单个值或多个值。 该元组通常包含错误字符串,错误编号和错误位置。
示例
以下是一个例外 -
#!/usr/bin/python3
# Define a function here.
def temp_convert(var):
try:
return int(var)
except ValueError as Argument:
print ("The argument does not contain numbers\n", Argument)
# Call above function here.
temp_convert("xyz")这产生以下结果 -
The argument does not contain numbers
invalid literal for int() with base 10: 'xyz'抛出异常
可以通过使用raise语句以多种方式引发异常。raise语句的一般语法如下 -
语法
raise [Exception [, args [, traceback]]]这里,Exception是异常的类型(例如,NameError),args是异常参数的值。 参数是可选的; 如果没有提供,则异常参数为None。
最后一个参数traceback也是可选的(在实践中很少使用),如果存在,则是用于异常的追溯对象。
示例
异常可以是字符串,类或对象。 Python核心引发的大多数异常都是类,一个参数是类的一个实例。 定义新的例外是非常容易的,可以做到如下 -
def functionName( level ):
if level <1:
raise Exception(level)
# The code below to this would not be executed
# if we raise the exception
return level注意 - 为了捕获异常,“except”子句必须引用与类对象或简单字符串相同的异常。例如,为了捕获上述异常,必须写出except子句如下:
try:
Business Logic here...
except Exception as e:
Exception handling here using e.args...
else:
Rest of the code here...以下示例说明了使用引发异常 -
#!/usr/bin/python3
def functionName( level ):
if level <1:
raise Exception(level)
# The code below to this would not be executed
# if we raise the exception
return level
try:
l = functionName(-10)
print ("level = ",l)
except Exception as e:
print ("error in level argument",e.args[0])这将产生以下结果 -
error in level argument -10用户定义的异常
Python还允许通过从标准内置异常导出类来创建自己的异常。
这是一个与RuntimeError有关的示例。 在这里,从RuntimeError类创建一个子类。 当需要在捕获异常时显示更多具体信息时,这就很有用了。
在try块中,用户定义的异常被引发并被捕获在except块中。 变量e用于创建Networkerror类的实例。
class Networkerror(RuntimeError):
def __init__(self, arg):
self.args = arg所以当定义了上面的类以后,就可以使用以下命令抛出异常 -
try:
raise Networkerror("Bad hostname")
except Networkerror,e:
print e.argsPython正则表达式
正则表达式是一个特殊的字符序列,可以帮助您使用模式中保留的专门语法来匹配或查找其他字符串或字符串集。 正则表达式在UNIX世界中被广泛使用。
注:很多开发人员觉得正则表达式比较难以理解,主要原因是缺少使用或不愿意在这上面花时间。
re模块在Python中提供对Perl类正则表达式的完全支持。如果在编译或使用正则表达式时发生错误,则re模块会引发异常re.error。
在这篇文章中,将介绍两个重要的功能,用来处理正则表达式。 然而,首先是一件小事:有各种各样的字符,这些字符在正则表达式中使用时会有特殊的意义。 为了在处理正则表达式时避免混淆,我们将使用:r’expression’原始字符串。
匹配单个字符的基本模式
| 编号 | 表达式 | 描述 |
|---|---|---|
| 1 | a, X, 9, < | 普通字符完全匹配。 |
| 2 | . | 匹配任何单个字符,除了换行符’\n‘ |
| 3 | \w | 匹配“单词”字符:字母或数字或下划线[a-zA-Z0-9_]。 |
| 4 | \W | 匹配任何非字词。 |
| 5 | \b | 字词与非字词之间的界限 |
| 6 | \s | 匹配单个空格字符 - 空格,换行符,返回,制表符 |
| 7 | \S | 匹配任何非空格字符。 |
| 8 | \t, \n, \r | 制表符,换行符,退格符 |
| 9 | \d | 十进制数[0-9] |
| 10 | ^ | 匹配字符串的开头 |
| 11 | $ | 匹配字符串的末尾 |
| 12 | \ | 抑制字符的“特殊性”,也叫转义字符。 |
编译标志
编译标志可以修改正则表达式的某些方面。标志在re模块中有两个名称:一个很长的名称,如IGNORECASE,和一个简短的单字母形式,如I。
| 编号 | 标志 | 含义 |
|---|---|---|
| 1 | ASCII, A | 像\w,\b,\s和\d之间的几个转义只匹配ASCII字符与相应的属性。 |
| 2 | DOTALL, S | 匹配任何字符,包括换行符 |
| 3 | IGNORECASE, I | 不区分大小写匹配 |
| 4 | LOCALE, L | 做一个区域感知的匹配 |
| 5 | MULTILINE, M | 多行匹配,影响^和$ |
| 6 | VERBOSE, X (for ‘extended’) | 启用详细的RE,可以更干净,更容易理解 |
1.match函数
此函数尝试将RE模式与可选标志的字符串进行匹配。
下面是函数的语法 -
re.match(pattern, string, flags = 0)这里是参数的描述 -
- pattern - 这是要匹配的正则表达式。
- string - 这是字符串,它将被搜索用于匹配字符串开头的模式。 |
- flags - 可以使用按位OR(|)指定不同的标志。 这些是修饰符,如下表所列。
re.match函数在成功时返回匹配对象,失败时返回None。使用match(num)或groups()函数匹配对象来获取匹配的表达式。
| 编号 | 匹配对象 | 描述 |
|---|---|---|
| 1 | group(num = 0) | 此方法返回整个匹配(或特定子组num) |
| 2 | groups() | 此方法返回一个元组中的所有匹配子组(如果没有,则返回为None) |
示例
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")当执行上述代码时,会产生以下结果 -
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter2.search函数
此函数尝试将RE模式与可选标志的字符串进行匹配。
下面是这个函数的语法 -
re.search(pattern, string, flags = 0)这里是参数的描述 -
- pattern - 这是要匹配的正则表达式。
- string - 这是字符串,它将被搜索用于匹配字符串开头的模式。 |
- flags - 可以使用按位OR(|)指定不同的标志。 这些是修饰符,如下表所列。
re.search函数在成功时返回匹配对象,否则返回None。使用match对象的group(num)或groups()函数来获取匹配的表达式。
| 编号 | 匹配对象 | 描述 |
|---|---|---|
| 1 | group(num = 0) | 此方法返回整个匹配(或特定子组num) |
| 2 | groups() | 此方法返回一个元组中的所有匹配子组(如果没有,则返回为None) |
示例
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs";
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print ("searchObj.group() : ", searchObj.group())
print ("searchObj.group(1) : ", searchObj.group(1))
print ("searchObj.group(2) : ", searchObj.group(2))
else:
print ("Nothing found!!")当执行上述代码时,会产生以下结果 -
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter3.匹配与搜索
Python提供基于正则表达式的两种不同的原始操作:match检查仅匹配字符串的开头,而search检查字符串中任何位置的匹配(这是Perl默认情况下的匹配)。
示例
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
searchObj = re.search( r'dogs', line, re.M|re.I)
if searchObj:
print ("search --> searchObj.group() : ", searchObj.group())
else:
print ("Nothing found!!")当执行上述代码时,会产生以下结果 -
No match!!
search --> matchObj.group() : dogs4.搜索和替换
使用正则表达式re模块中的最重要的之一是sub。
模块
re.sub(pattern, repl, string, max=0)此方法使用repl替换所有出现在RE模式的字符串,替换所有出现,除非提供max。此方法返回修改的字符串。
示例
#!/usr/bin/python3
import re
phone = "2018-959-559 # This is Phone Number"
# Delete Python-style comments
num = re.sub(r'#.*$', "", phone)
print ("Phone Num : ", num)
# Remove anything other than digits
num = re.sub(r'\D', "", phone)
print ("Phone Num : ", num)当执行上述代码时,会产生以下结果 -
Phone Num : 2018-959-559
Phone Num : 20189595595.正则表达式修饰符:选项标志
正则表达式文字可能包含一个可选修饰符,用于控制匹配的各个方面。 修饰符被指定为可选标志。可以使用异或(|)提供多个修饰符,如前所示,可以由以下之一表示 -
| 编号 | 修辞符 | 描述 |
|---|---|---|
| 1 | re.I | 执行不区分大小写的匹配。 |
| 2 | re.L | 根据当前语言环境解释单词。这种解释影响字母组(\w和\W)以及字边界行为(\b和\B)。 |
| 3 | re.M | 使$匹配一行的结尾(而不仅仅是字符串的结尾),并使^匹配任何行的开始(而不仅仅是字符串的开头)。 |
| 4 | re.S | 使一个句点(.)匹配任何字符,包括换行符。 |
| 5 | re.U | 根据Unicode字符集解释字母。 此标志影响\w,\W,\b,\B的行为。 |
| 6 | re.X | 允许“cuter”正则表达式语法。 它忽略空格(除了一个集合[]内部,或者用反斜杠转义),并将未转义的#作为注释标记。 |
6.正则表达模式
除了控制字符(+ ? . * ^ $ ( ) [ ] { } | ),所有字符都与其自身匹配。 可以通过使用反斜杠将其转换为控制字符。
7.正则表达式示例
字符常量
| 编号 | 示例 | 说明 |
|---|---|---|
| 1 | python | 匹配“python”。 |
字符类
| 编号 | 示例 | 说明 |
|---|---|---|
| 1 | [Pp]ython | 匹配“Python”或“python” |
| 2 | rub[ye] | 匹配“ruby”或“rube” |
| 3 | [aeiou] | 匹配任何一个小写元音 |
| 4 | [0-9] | 匹配任何数字; 如[0123456789] |
| 5 | [a-z] | 匹配任何小写ASCII字母 |
| 6 | [A-Z] | 匹配任何大写的ASCII字母 |
| 7 | [a-zA-Z0-9] | 匹配上述任何一个 |
| 8 | [^aeiou] | 匹配除小写元音之外的任何东西 |
| 9 | [^0-9] | 匹配数字以外的任何东西 |
特殊字符类
| 编号 | 示例 | 说明 |
|---|---|---|
| 1 | . | 匹配除换行符以外的任何字符 |
| 2 | \d | 匹配数字:[0-9] |
| 3 | \D | 匹配非数字:[^0-9] |
| 4 | \s | 匹配空格字符:[\t\r\n\f] |
| 5 | \S | 匹配非空格:[^\t\r\n\f] |
| 6 | \w | 匹配单字字符: [A-Za-z0-9_] |
| 7 | \W | 匹配非单字字符: [^A-Za-z0-9_] |
重复匹配
| 编号 | 示例 | 说明 |
|---|---|---|
| 1 | ruby? | 匹配“rub”或“ruby”:y是可选的 |
| 2 | ruby* | 匹配“rub”加上0个以上的y |
| 3 | ruby+ | 匹配“rub”加上1个或更多的y |
| 4 | \d{3} | 完全匹配3位数 |
| 5 | \d{3,} | 匹配3位或更多位数字 |
| 6 | \d{3,5} | 匹配3,4或5位数 |
非贪婪重复
这匹配最小的重复次数 -
| 编号 | 示例 | 说明 |
|---|---|---|
| 1 | <.*> | 贪婪重复:匹配“ perl>” |
| 2 | <.*?> | 非贪婪重复:在“ perl”中匹配“” |
用圆括号分组
| 编号 | 示例 | 说明 |
|---|---|---|
| 1 | \D\d+ | 没有分组:+重复\d |
| 2 | (\D\d)+ | 分组:+重复\D\d对 |
| 3 | ([Pp]ython(,)?)+ | 匹配“Python”,“Python,python,python”等 |
反向引用|
这与以前匹配的组再次匹配 -
| 编号 | 示例 | 说明 |
|---|---|---|
| 1 | ([Pp])ython&\1ails | 匹配python和pails或Python和Pails |
| 2 | ([‘”])[^\1]*\1 | 单引号或双引号字符串。\1匹配第一个分组匹配。 \2匹配任何第二个分组匹配等 |
备择方案
- python|perl - 匹配“python”或“perl”
- rub(y|le) - 匹配 “ruby” 或 “ruble”
- Python(!+|\?) - “Python”后跟一个或多个! 还是一个?
锚点
这需要指定匹配位置。
| 编号 | 示例 | 说明 |
|---|---|---|
| 1 | ^Python | 在字符串或内部行的开头匹配“Python” |
| 2 | Python$ | 在字符串或内部行的结尾匹配“Python” |
| 3 | \APython | 在字符串的开头匹配“Python” |
| 4 | Python\Z | 在字符串的末尾匹配“Python” |
| 5 | \bPython\b | 在字词的边界匹配“Python” |
| 6 | \brub\B | \B是非字词边界:在“rube”和“ruby”中匹配“rub”,而不是单独匹配 |
| 7 | Python(?=!) | 匹配“Python”,如果跟着感叹号。 |
| 8 | Python(?!!) | 匹配“Python”,如果没有感叹号后面。 |
带括号的特殊语法
| 编号 | 示例 | 说明 |
|---|---|---|
| 1 | R(?#comment) | 匹配“R”。其余的都是注释 |
| 2 | R(?i)uby | 匹配“uby”时不区分大小写 |
| 3 | R(?i:uby) | 同上 |
| 4 | rub(?:y le)) | 仅组合而不创建\1反向引用 |
Python+MySQL数据库操作(PyMySQL)
Python的数据库接口标准是Python DB-API。大多数Python数据库接口遵循这个标准。
可以为应用程序选择正确的数据库。Python数据库API支持广泛的数据库服务器,如 -
- GadFly
- mSQL
- MySQL
- PostgreSQL
- Microsoft SQL Server 2000
- Informix
- Interbase
- Oracle
- Sybase
- SQLite
以下是可用的Python数据库接口 - Python数据库接口和API的列表。需要为要访问的每种数据库下载一个单独的DB API模块。 例如,如果需要访问Oracle数据库和MySQL数据库,则必须同时下载Oracle和MySQL数据库模块。
DB API为尽可能使用Python结构和语法处理数据库提供了最低标准。API包括以下内容:
- 导入API模块。
- 获取与数据库的连接。
- 发出SQL语句和存储过程。
- 关闭连接
Python具有内置的SQLite支持。 在本节中,我们将学习使用MySQL的相关概念和知识。 在早期Python版本一般都使用MySQLdb模块,但这个MySQL的流行接口与Python 3不兼容。因此,在教程中将使用PyMySQL模块。
1.什么是PyMySQL?
PyMySQL是从Python连接到MySQL数据库服务器的接口。 它实现了Python数据库API v2.0,并包含一个纯Python的MySQL客户端库。 PyMySQL的目标是成为MySQLdb的替代品。
PyMySQL参考文档:http://pymysql.readthedocs.io/
2.如何安装PyMySQL?
在使用PyMySQL之前,请确保您的机器上安装了PyMySQL。只需在Python脚本中输入以下内容即可执行它 -
#!/usr/bin/python3
import PyMySQL在 Windows 系统上,打开命令提示符 -
C:\Users\Administrator>python
Python 3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 18:41:36) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import PyMySQL
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'PyMySQL'
>>>如果产生如上结果,则表示PyMySQL模块尚未安装。
最后一个稳定版本可以在PyPI上使用,可以通过pip命令来安装-
:\Users\Administrator> pip install PyMySQL
Collecting PyMySQL
Downloading PyMySQL-0.7.11-py2.py3-none-any.whl (78kB)
51% |████████████████▋ |
40kB 109kB/s eta 0:0 64% |████████████████████▊
| 51kB 112kB/s eta 77% |█████████████████████████ | 61kB 135kB/s 90% |█████████████████████████████
| 71kB 152 100% |████████████████████████████████| 81kB 163kB/s
Installing collected packages: PyMySQL
Successfully installed PyMySQL-0.7.11
C:\Users\Administrator>或者(例如,如果pip不可用),可以从GitHub下载tarball,并按照以下方式安装:
$ # X.X is the desired PyMySQL version (e.g. 0.5 or 0.6).
$ curl -L http://github.com/PyMySQL/PyMySQL/tarball/pymysql-X.X | tar xz
$ cd PyMySQL*
$ python setup.py install
$ # The folder PyMySQL* can be safely removed now.注意 - 确保具有root权限来安装上述模块。
3.数据库连接
在连接到MySQL数据库之前,请确保以下几点:
- 已经创建了一个数据库:test。
- 已经在test中创建了一个表:employee。
- employee表格包含:fist_name,last_name,age,sex和income字段。
- MySQL用户“root”和密码“123456”可以访问:test。
- Python模块PyMySQL已正确安装在您的计算机上。
- 已经通过MySQL教程了解MySQL基础知识。
创建表employee的语句为:

CREATE TABLE `employee` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`first_name` char(20) NOT NULL,
`last_name` char(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` char(1) DEFAULT NULL,
`income` float DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;实例
以下是Python通过PyMySQL模块接口连接MySQL数据库“test”的示例 -
注意:在 Windows 系统上,import PyMySQL 和 import pymysql 有区别。
#!/usr/bin/python3
#coding=utf-8
import pymysql
# Open database connection
db = pymysql.connect("localhost","root","","test_emp" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# execute SQL query using execute() method.
cursor.execute("SELECT VERSION()")
# Fetch a single row using fetchone() method.
data = cursor.fetchone()
print ("Database version : %s " % data)
# disconnect from server
db.close()运行此脚本时,会产生以下结果 -
Database version : 5.6.40 如果使用数据源建立连接,则会返回连接对象并将其保存到db中以供进一步使用,否则将db设置为None。 接下来,db对象用于创建一个游标对象,用于执行SQL查询。 最后,在结果打印出来之前,它确保数据库连接关闭并释放资源。
4.创建数据库表
建立数据库连接后,可以使用创建的游标的execute方法将数据库表或记录创建到数据库表中。
示例
下面演示如何在数据库:test中创建一张数据库表:employee -
#!/usr/bin/python3
#coding=utf-8
import pymysql
# Open database connection
db = pymysql.connect("localhost","root","123456","test" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Drop table if it already exist using execute() method.
cursor.execute("DROP TABLE IF EXISTS employee")
# Create table as per requirement
sql = """CREATE TABLE `employee` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`first_name` char(20) NOT NULL,
`last_name` char(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` char(1) DEFAULT NULL,
`income` float DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;"""
cursor.execute(sql)
print("Created table Successfull.")
# disconnect from server
db.close()运行此脚本时,会产生以下结果 -
Created table Successfull.5.插入操作
当要将记录创建到数据库表中时,需要执行INSERT操作。
示例
以下示例执行SQL的INSERT语句以在EMPLOYEE表中创建一条(多条)记录 -
#!/usr/bin/python3
#coding=utf-8
import pymysql
# Open database connection
db = pymysql.connect("localhost","root","","test_emp" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to INSERT a record into the database.
sql = """INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Su', 20, 'M', 5000)"""
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
## 再次插入一条记录
# Prepare SQL query to INSERT a record into the database.
sql = """INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES ('Kobe', 'Bryant', 40, 'M', 8000)"""
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
print (sql)
print('Yes, Insert Successfull.')
# disconnect from server
db.close()Python
运行此脚本时,会产生以下结果 -
INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES ('Kobe', 'Bryant', 40, 'M', 8000)
Yes, Insert Successfull.上述插入示例可以写成如下动态创建SQL查询 -
#!/usr/bin/python3
#coding=utf-8
import pymysql
# Open database connection
db = pymysql.connect("localhost","root","","test_emp" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to INSERT a record into the database.
sql = "INSERT INTO EMPLOYEE(FIRST_NAME, \
LAST_NAME, AGE, SEX, INCOME) \
VALUES ('%s', '%s', '%d', '%c', '%d' )" % \
('Max', 'Su', 25, 'F', 2800)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()示例
以下代码段是另一种执行方式,可以直接传递参数 -
…………………………….
user_id = “test123”
password = “password”
con.execute(‘insert into Login values(“%s”, “%s”)’ % \
(user_id, password))
…………………………….
6.读取操作
任何数据库上的读操作表示要从数据库中读取获取一些有用的信息。
在建立数据库连接后,就可以对此数据库进行查询了。 可以使用fetchone()方法获取单条记录或fetchall()方法从数据库表中获取多个值。
fetchone() - 它获取查询结果集的下一行。 结果集是当使用游标对象来查询表时返回的对象。
fetchall() - 它获取结果集中的所有行。 如果已经从结果集中提取了一些行,则从结果集中检索剩余的行。
rowcount - 这是一个只读属性,并返回受execute()方法影响的行数。
示例
以下过程查询EMPLOYEE表中所有记录的工资超过1000员工记录信息 -
#!/usr/bin/python3
#coding=utf-8
import pymysql
# Open database connection
db = pymysql.connect("localhost","root","","test_emp" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# 按字典返回
# cursor = db.cursor(pymysql.cursors.DictCursor)
# Prepare SQL query to select a record from the table.
sql = "SELECT * FROM EMPLOYEE \
WHERE INCOME > %d" % (1000)
#print (sql)
try:
# Execute the SQL command
cursor.execute(sql)
# Fetch all the rows in a list of lists.
results = cursor.fetchall()
for row in results:
#print (row)
fname = row[1]
lname = row[2]
age = row[3]
sex = row[4]
income = row[5]
# Now print fetched result
print ("name = %s %s,age = %s,sex = %s,income = %s" % \
(fname, lname, age, sex, income ))
except:
import traceback
traceback.print_exc()
print ("Error: unable to fetch data")
# disconnect from server
db.close()name = Mac Su,age = 20,sex = M,income = 5000.0
name = Kobe Bryant,age = 40,sex = M,income = 8000.0
name = Max Su,age = 25,sex = F,income = 2800.07.更新操作
UPDATE语句可对任何数据库中的数据进行更新操作,它可用于更新数据库中已有的一个或多个记录。
以下程序将所有SEX字段的值为“M”的记录的年龄(age字段)更新为增加一年。
#!/usr/bin/python3
#coding=utf-8
import pymysql
# Open database connection
db = pymysql.connect("localhost","root","","test_emp" )
# prepare a cursor object using cursor() method
#cursor = db.cursor()
cursor = db.cursor(pymysql.cursors.DictCursor)
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to UPDATE required records
sql = "UPDATE EMPLOYEE SET AGE = AGE + 1 \
WHERE SEX = '%c'" % ('M')
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()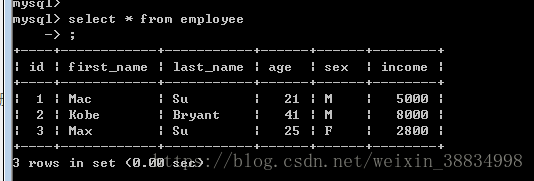
8.删除操作
当要从数据库中删除一些记录时,那么可以执行DELETE操作。 以下是删除EMPLOYEE中AGE超过40的所有记录的程序 -
#!/usr/bin/python3
#coding=utf-8
import pymysql
# Open database connection
db = pymysql.connect("localhost","root","","test_emp" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to DELETE required records
sql = "DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (40)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()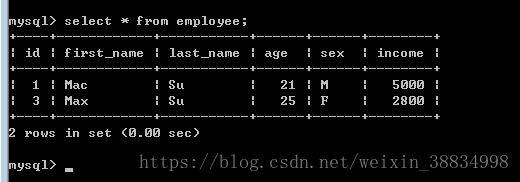
9.执行事务
事务是确保数据一致性的一种机制。事务具有以下四个属性 -
原子性 - 事务要么完成,要么完全没有发生。
一致性 - 事务必须以一致的状态开始,并使系统保持一致状态。
隔离性 - 事务的中间结果在当前事务外部不可见。
持久性 - 当提交了一个事务,即使系统出现故障,效果也是持久的。
Python DB API 2.0提供了两种提交或回滚事务的方法。
示例
已经知道如何执行事务。 这是一个类似的例子 -
# Prepare SQL query to DELETE required records
sql = "DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (20)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
9.1.COMMIT操作
提交是一种操作,它向数据库发出信号以完成更改,并且在此操作之后,不会更改任何更改。
下面是一个简单的例子演示如何调用commit()方法。
db.commit()9.2.回滚操作
如果您对一个或多个更改不满意,并且要完全还原这些更改,请使用rollback()方法。
下面是一个简单的例子演示如何调用rollback()方法。
db.rollback()10.断开数据库连接
要断开数据库连接,请使用close()方法。
db.close()如果用户使用close()方法关闭与数据库的连接,则任何未完成的事务都将被数据库回滚。 但是,您的应用程序不会依赖于数据级别的实现细节,而是明确地调用提交或回滚。
11.处理错误
错误有很多来源。一些示例是执行的SQL语句中的语法错误,连接失败或为已取消或已完成语句句柄调用fetch方法等等。
DB API定义了每个数据库模块中必须存在的许多错误。下表列出了这些异常和错误 -
| 编号 | 异常 | 描述 |
|---|---|---|
| 1 | Warning | 用于非致命问题,是StandardError的子类。 |
| 2 | Error | 错误的基类,是StandardError的子类。 |
| 3 | InterfaceError | 用于数据库模块中的错误,但不是数据库本身,是Error的子类。 |
| 4 | DatabaseError | 用于数据库中的错误,是Error的子类。 |
| 5 | DataError | DatabaseError的子类引用数据中的错误。 |
| 6 | OperationalError | DatabaseError的子类,涉及如丢失与数据库的连接等错误。 这些错误通常不在Python脚本程序的控制之内。 |
| 7 | IntegrityError | DatabaseError 子类错误,可能会损害关系完整性,例如唯一性约束和外键。 |
| 8 | InternalError | DatabaseError的子类,指的是数据库模块内部的错误,例如游标不再活动。 |
| 9 | ProgrammingError | DatabaseError的子类,它引用错误,如错误的表名和其他安全。 |
| 10 | NotSupportedError | DatabaseError的子类,用于尝试调用不支持的功能。 |
Python脚本应该处理这些错误,但在使用任何上述异常之前,请确保您的PyMySQL支持该异常。 可以通过阅读DB API 2.0规范获得更多关于它们的信息。
Python网络编程(Sockets)
Python提供了两个级别的访问网络服务。 在低级别,可以访问底层操作系统中的基本套接字支持,这允许您实现面向连接和无连接协议的客户端和服务器。
Python还具有提供对特定应用级网络协议(如FTP,HTTP等)的更高级别访问的库。
本章将了解和学习网络中最着名的概念 - 套接字编程。
1.什么是套接字?
套接字(Sockets)是双向通信信道的端点。 套接字可以在一个进程内,在同一机器上的进程之间,或者在不同主机的进程之间进行通信,主机可以是任何一台有连接互联网的机器。
套接字可以通过多种不同的通道类型实现:Unix域套接字,TCP,UDP等。 套接字库提供了处理公共传输的特定类,以及一个用于处理其余部分的通用接口。
套接字有自己的术语 -
- domain - 用作传输机制的协议族。这些值是常量,例如:AF_INET,PF_INET,PF_UNIX,PF_X25等。
- type - 两个端点之间的通信类型,通常用于面向连接的协议的SOCK_STREAM和用于无连接协议的SOCK_DGRAM。
- protocol - 通常为0,这可以用于标识域和类型中的协议的变体。
- hostname - 网络接口的标识符 -
- 一个字符串,可以是一个主机名,一个有四个点符号的IP地址,或一个冒号中的IPV6地址(可能是点)符号。
- 一个字符串“”,它指定一个INADDR_BROADCAST地址。
- 零长度字符串,指定INADDR_ANY,或
- 整数,以主机字节顺序解释为二进制地址。
- port - 每个服务器监听一个或多个端口的客户端的调用。端口可能是Fixnum端口号,包含端口号的字符串或服务名称。
2、socket模块
要创建套接字,必须使用套接字模块中的socket.socket()函数,该函数具有一般语法 -
s = socket.socket (socket_family, socket_type, protocol = 0)这里是上述参数的描述 -
- socket_family - 它的值可以是:AF_UNIX或AF_INET,如前所述。
- socket_type - 它的值可以是:SOCK_STREAM或SOCK_DGRAM。
- protocol - 这通常被省略,默认为0。
当创建了套接字对象这后,就可以使用所需的函数来创建客户端或服务器程序。 以下是所需函数的列表:
服务器套接字方法
| 编号 | 方法 | 描述 |
|---|---|---|
| 1 | s.bind() | 此方法将地址(主机名,端口号对)绑定到套接字。 |
| 2 | s.listen() | 此方法设置并启动TCP侦听器。 |
| 3 | s.accept() | 这被动地接受TCP客户端连接,等待直到连接到达(阻塞)。 |
客户端套接字方法
| 编号 | 方法 | 描述 |
|---|---|---|
| 1 | s.connect() | 此方法主动启动TCP服务器连接。 |
通用套接字方法
| 编号 | 方法 | 描述 |
|---|---|---|
| 1 | s.recv() | 此方法接收TCP消息。 |
| 2 | s.send() | 该方法发送TCP消息 |
| 3 | s.recvfrom() | 此方法接收UDP消息 |
| 4 | s.sendto() | 此方法发送UDP消息 |
| 5 | s.close() | 此方法关闭套接字 |
| 6 | socket.gethostname() | 返回主机名 |
3.一个简单的服务器
要编写互联网服务器,可使用socket模块中可用的socket()来创建套接字对象。 然后使用套接字对象调用其他函数来设置套接字服务器。
现在调用bind(hostname,port)函数来指定主机上服务的端口。
接下来,调用返回对象的accept()方法。 此方法在您指定的端口等待客户端连接,连接成功后返回一个连接(connection)对象,该对象表示与该客户端的连接。
#!/usr/bin/python3 # This is server.py file
import socket
# create a socket object
serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# get local machine name
host = socket.gethostname()
port = 8088
# bind to the port
serversocket.bind((host, port))
print("Server start at port: 8088")
# queue up to 5 requests
serversocket.listen(5)
while True:
# establish a connection
clientsocket,addr = serversocket.accept()
print("Got a connection from %s" % str(addr))
msg='Thank you for connecting'+ "\r\n"
clientsocket.send(msg.encode('ascii'))
clientsocket.close()================== RESTART: D:/code/python/socket_server.py ==================
Server start at port: 8088
4.一个简单的客户端
下面接着编写一个非常简单的客户端程序,打开与给定端口8088与上面的服务器程序主机的连接。 使用Python的socket模块功能创建套接字客户端非常简单。
socket.connect(hosname,port)函数打开hostname上的port的TCP连接。当打开了一个套接字,就可以像任何IO对象一样读取它。 完成后,请记住关闭它,就像关闭文件一样。
示例
以下代码是连接到给定主机和端口的非常简单的客户端,从套接字读取任何可用数据,然后退出 -
#!/usr/bin/python3 # This is client.py file
import socket
# create a socket object
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# get local machine name
host = socket.gethostname()
port = 8088
# connection to hostname on the port.
s.connect((host, port))
# Receive no more than 1024 bytes
msg = s.recv(1024)
s.close()
print (msg.decode('ascii'))现在在后台运行先运行:server.py,然后运行上面的client.py来查看结果,如果程序没有错误,那么应该得到类似以下以结果 -

5. Python互联网模块
Python网络/互联网编程中的一些重要模块的列表如下:
| 协议 | 通用功能 | 端口号 | 对应Python模块 |
|---|---|---|---|
| HTTP | 网页服务 | 80 | httplib, urllib, xmlrpclib |
| NNTP | Usenet新闻 | 119 | nntplib |
| FTP | 文件传输 | 20 | ftplib, urllib |
| SMTP | 发送邮件 | 25 | smtplib |
| POP3 | 获取电子邮件 | 110 | poplib |
| IMAP4 | 获取电子邮件 | 143 | imaplib |
| Telnet | 命令行 | 23 | telnetlib |
| Gopher | 文档传输 | 70 | gopherlib, urllib |
请检查上述所有库,以使用FTP,SMTP,POP和IMAP协议。
进一步阅读
这是Socket编程的一个快速开始。 这是一个广阔的话题。 建议通过以下链接查找更多详细信息 -
Unix套接字编程。
Python套接字库和模块。
Python发送邮件
简单邮件传输协议(SMTP)是一种协议,用于在邮件服务器之间发送电子邮件和路由电子邮件。
Python提供smtplib模块,该模块定义了一个SMTP客户端会话对象,可用于使用SMTP或ESMTP侦听器守护程序向任何互联网机器发送邮件。
这是一个简单的语法,用来创建一个SMTP对象,稍后将演示如何用它来发送电子邮件 -
import smtplib
smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )这里是上面语法的参数细节 -
- host - 这是运行SMTP服务器的主机。可以指定主机的IP地址或类似yiibai.com的域名。这是一个可选参数。
- port - 如果提供主机参数,则需要指定SMTP服务器正在侦听的端口。通常这个端口默认值是:25。
- local_hostname - 如果SMTP服务器在本地计算机上运行,那么可以只指定localhost选项。
SMTP对象有一个sendmail的实例方法,该方法通常用于执行邮件发送的工作。它需要三个参数 -
- sender - 具有发件人地址的字符串。
- receivers - 字符串列表,每个收件人一个。
- message - 作为格式如在各种RFC中指定的字符串。
1.使用Python发送纯文本电子邮件
示例
以下是使用Python脚本发送一封电子邮件的简单方法 -
#!/usr/bin/python3
import smtplib
sender = 'from@fromdomain.com'
receivers = ['to@todomain.com']
message = """From: From Person <from@fromdomain.com>
To: To Person <to@todomain.com>
Subject: SMTP e-mail test
This is a test e-mail message.
"""
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message)
print "Successfully sent email"
except SMTPException:
print "Error: unable to send email"在这里,已经发送了一封基本的电子邮件,使用三重引号,请注意正确格式化标题。一封电子邮件需要一个From,To和一个Subject标题,与电子邮件的正文与空白行分开。
要发送邮件,使用smtpObj连接到本地机器上的SMTP服务器。 然后使用sendmail方法以及消息,从地址和目标地址作为参数(即使来自和地址在电子邮件本身内,这些并不总是用于路由邮件)。
如果没有在本地计算机上运行SMTP服务器,则可以使用smtplib客户端与远程SMTP服务器进行通信。除非您使用网络邮件服务(如gmail或Yahoo! Mail),否则您的电子邮件提供商必须向您提供可以提供的邮件服务器详细信息。以腾讯QQ邮箱为例,具体如下:
mail = smtplib.SMTP('smtp.qq.com', 587) # 端口465或5872.使用Python发送HTML电子邮件
当使用Python发送邮件信息时,所有内容都被视为简单文本。 即使在短信中包含HTML标签,它也将显示为简单的文本,HTML标签将不会根据HTML语法进行格式化。 但是,Python提供了将HTML消息作为HTML消息发送的选项。
发送电子邮件时,可以指定一个Mime版本,内容类型和发送HTML电子邮件的字符集。
以下是将HTML内容作为电子邮件发送的示例 -
#!/usr/bin/python3
import smtplib
message = """From: From Person <from@fromdomain.com>
To: To Person <to@todomain.com>
MIME-Version: 1.0
Content-type: text/html
Subject: SMTP HTML e-mail test
This is an e-mail message to be sent in HTML format
<b>This is HTML message.</b>
<h1>This is headline.</h1>
"""
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message)
print "Successfully sent email"
except SMTPException:
print "Error: unable to send email"3.发送附件作为电子邮件
要发送具有混合内容的电子邮件,需要将Content-type标题设置为multipart / mixed。 然后,可以在边界内指定文本和附件部分。
一个边界以两个连字符开始,后跟一个唯一的编号,不能出现在电子邮件的消息部分。 表示电子邮件最终部分的最后一个边界也必须以两个连字符结尾。
所附的文件应该用包(“m”)功能编码,以便在传输之前具有基本的64编码。
4.发送示例
首先我们要知道用python代理登录qq邮箱发邮件,是需要更改自己qq邮箱设置的。在这里大家需要做两件事情:邮箱开启SMTP功能 、获得授权码。之后我们来看看如何更改模板代码,实现使用Python登录QQ邮箱发送QQ邮件。
注意:也可以使用其他服务商的 SMTP 访问(QQ、网易、Gmail等)。
使用QQ邮件发送邮件之前如何设置授权码,参考:
http://service.mail.qq.com/cgi-bin/help?subtype=1&&id=28&&no=1001256
4.1.发送一纯文本邮件到指定邮件
#! /usr/bin/env python
#coding=utf-8
from email.mime.text import MIMEText
from email.header import Header
from smtplib import SMTP_SSL
#qq邮箱smtp服务器
host_server = 'smtp.qq.com'
#sender_qq为发件人的qq号码
sender_qq = '769728683@qq.com'
#pwd为qq邮箱的授权码
pwd = '****kenbb***' ## xh**********bdc
#发件人的邮箱
sender_qq_mail = '769728683@qq.com'
#收件人邮箱
receiver = 'yiibai.com@gmail.com'
#邮件的正文内容
mail_content = '你好,这是使用python登录qq邮箱发邮件的测试'
#邮件标题
mail_title = 'Maxsu的邮件'
#ssl登录
smtp = SMTP_SSL(host_server)
#set_debuglevel()是用来调试的。参数值为1表示开启调试模式,参数值为0关闭调试模式
smtp.set_debuglevel(1)
smtp.ehlo(host_server)
smtp.login(sender_qq, pwd)
msg = MIMEText(mail_content, "plain", 'utf-8')
msg["Subject"] = Header(mail_title, 'utf-8')
msg["From"] = sender_qq_mail
msg["To"] = receiver
smtp.sendmail(sender_qq_mail, receiver, msg.as_string())
smtp.quit()执行上面代码后,登录接收邮件的邮件帐号,这里接收邮件的账号为:yiibai.com@gmail.com,登录 http://gmail.com 应该会看到有接收到邮件如下 -
注意:有时可能被认为是垃圾邮件,如果没有找到可从“垃圾邮件”查找一下。
4.2.给多个人发送邮件
#! /usr/bin/env python
#coding=utf-8
from email.mime.text import MIMEText
from email.header import Header
from smtplib import SMTP_SSL
#qq邮箱smtp服务器
host_server = 'smtp.qq.com'
#sender_qq为发件人的qq号码
sender_qq = '769728683@qq.com'
#pwd为qq邮箱的授权码
pwd = 'h**********bdc' ## h**********bdc
#发件人的邮箱
sender_qq_mail = '769728683@qq.com'
#收件人邮箱
receivers = ['yiibai.com@gmail.com','****su@gmail.com']
#邮件的正文内容
mail_content = '你好,这是使用python登录qq邮箱发邮件的测试'
#邮件标题
mail_title = 'Maxsu的邮件'
#ssl登录
smtp = SMTP_SSL(host_server)
#set_debuglevel()是用来调试的。参数值为1表示开启调试模式,参数值为0关闭调试模式
smtp.set_debuglevel(1)
smtp.ehlo(host_server)
smtp.login(sender_qq, pwd)
msg = MIMEText(mail_content, "plain", 'utf-8')
msg["Subject"] = Header(mail_title, 'utf-8')
msg["From"] = sender_qq_mail
msg["To"] = Header("接收者测试", 'utf-8') ## 接收者的别名
smtp.sendmail(sender_qq_mail, receivers, msg.as_string())
smtp.quit()执行上面代码后,登录接收邮件的邮件帐号,这里接收邮件的账号为:yiibai.com@gmail.com,登录 http://gmail.com 应该会看到有接收到邮件如下 -
4.3.使用Python发送HTML格式的邮件
Python发送HTML格式的邮件与发送纯文本消息的邮件不同之处就是将MIMEText中_subtype设置为html。代码如下:
#! /usr/bin/env python
#coding=utf-8
from email.mime.text import MIMEText
from email.header import Header
from smtplib import SMTP_SSL
#qq邮箱smtp服务器
host_server = 'smtp.qq.com'
#sender_qq为发件人的qq号码
sender_qq = '769728683@qq.com'
#pwd为qq邮箱的授权码
pwd = '***bmke********' ##
#发件人的邮箱
sender_qq_mail = '769728683@qq.com'
#收件人邮箱
receiver = 'yiibai.com@gmail.com'
#邮件的正文内容
mail_content = "你好,<p>这是使用python登录qq邮箱发送HTML格式邮件的测试:</p><p><a href='http://www.yiibai.com'>易百教程</a></p>"
#邮件标题
mail_title = 'Maxsu的邮件'
#ssl登录
smtp = SMTP_SSL(host_server)
#set_debuglevel()是用来调试的。参数值为1表示开启调试模式,参数值为0关闭调试模式
smtp.set_debuglevel(1)
smtp.ehlo(host_server)
smtp.login(sender_qq, pwd)
msg = MIMEText(mail_content, "html", 'utf-8')
msg["Subject"] = Header(mail_title, 'utf-8')
msg["From"] = sender_qq_mail
msg["To"] = Header("接收者测试", 'utf-8') ## 接收者的别名
smtp.sendmail(sender_qq_mail, receiver, msg.as_string())
smtp.quit()执行上面代码后,登录接收邮件的邮件帐号,这里接收邮件的账号为:yiibai.com@gmail.com,登录 http://gmail.com 应该会看到有接收到邮件如下 -
4.4.Python发送带附件的邮件
要发送带附件的邮件,首先要创建MIMEMultipart()实例,然后构造附件,如果有多个附件,可依次构造,最后使用smtplib.smtp发送。
实现代码如下所示 -
#! /usr/bin/env python
#coding=utf-8
import smtplib
from email.mime.text import MIMEText
from email.header import Header
from smtplib import SMTP_SSL
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import Header
#qq邮箱smtp服务器
host_server = 'smtp.qq.com'
#sender_qq为发件人的qq号码
sender_qq = '769728683@qq.com'
#pwd为qq邮箱的授权码
pwd = '*****mkenb****' ##
#发件人的邮箱
sender_qq_mail = '769728683@qq.com'
#收件人邮箱
receiver = 'yiibai.com@gmail.com'
#邮件的正文内容
mail_content = "你好,<p>这是使用python登录qq邮箱发送HTML格式邮件的测试:</p><p><a href='http://www.yiibai.com'>易百教程</a></p>"
#邮件标题
mail_title = 'Maxsu的邮件'
#邮件正文内容
msg = MIMEMultipart()
#msg = MIMEText(mail_content, "plain", 'utf-8')
msg["Subject"] = Header(mail_title, 'utf-8')
msg["From"] = sender_qq_mail
msg["To"] = Header("接收者测试", 'utf-8') ## 接收者的别名
#邮件正文内容
msg.attach(MIMEText(mail_content, 'html', 'utf-8'))
# 构造附件1,传送当前目录下的 test.txt 文件
att1 = MIMEText(open('attach.txt', 'rb').read(), 'base64', 'utf-8')
att1["Content-Type"] = 'application/octet-stream'
# 这里的filename可以任意写,写什么名字,邮件中显示什么名字
att1["Content-Disposition"] = 'attachment; filename="attach.txt"'
msg.attach(att1)
# 构造附件2,传送当前目录下的 runoob.txt 文件
att2 = MIMEText(open('yiibai.txt', 'rb').read(), 'base64', 'utf-8')
att2["Content-Type"] = 'application/octet-stream'
att2["Content-Disposition"] = 'attachment; filename="yiibai.txt"'
msg.attach(att2)
#ssl登录
smtp = SMTP_SSL(host_server)
#set_debuglevel()是用来调试的。参数值为1表示开启调试模式,参数值为0关闭调试模式
smtp.set_debuglevel(1)
smtp.ehlo(host_server)
smtp.login(sender_qq, pwd)
smtp.sendmail(sender_qq_mail, receiver, msg.as_string())
smtp.quit()执行上面代码后,登录接收邮件的邮件帐号,这里接收邮件的账号为:yiibai.com@gmail.com,登录 http://gmail.com 应该会看到有接收到邮件如下 -
4.5.在 HTML 文本中添加图片
邮件的HTML文本中一般邮件服务商添加外链是无效的,所以要发送带图片的邮件内容,可以参考下面的实例代码实现:
#! /usr/bin/env python
#coding=utf-8
import smtplib
from email.mime.text import MIMEText
from email.header import Header
from smtplib import SMTP_SSL
from email.mime.image import MIMEImage
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
#qq邮箱smtp服务器
host_server = 'smtp.qq.com'
#sender_qq为发件人的qq号码
sender_qq = '769728683@qq.com'
#pwd为qq邮箱的授权码
pwd = 'h******mk*****' #
#发件人的邮箱
sender_qq_mail = '769728683@qq.com'
#收件人邮箱
receiver = ['yiibai.com@gmail.com','h****u@qq.com']
#邮件的正文内容
mail_content = ""
#邮件标题
mail_title = 'Maxsu的邮件'
#邮件正文内容
#msg = MIMEMultipart()
msg = MIMEMultipart('related')
msg["Subject"] = Header(mail_title, 'utf-8')
msg["From"] = sender_qq_mail
msg["To"] = Header("接收者测试", 'utf-8') ## 接收者的别名
msgAlternative = MIMEMultipart('alternative')
msg.attach(msgAlternative)
#邮件正文内容
mail_body = """
<p>你好,Python 邮件发送测试...</p>
<p>这是使用python登录qq邮箱发送HTML格式和图片的测试邮件:</p>
<p><a href='http://www.yiibai.com'>易百教程</a></p>
<p>图片演示:</p>
<p><img src="cid:send_image"></p>
"""
#msg.attach(MIMEText(mail_body, 'html', 'utf-8'))
msgText = (MIMEText(mail_body, 'html', 'utf-8'))
msgAlternative.attach(msgText)
# 指定图片为当前目录
fp = open('my.png', 'rb')
msgImage = MIMEImage(fp.read())
fp.close()
# 定义图片 ID,在 HTML 文本中引用
msgImage.add_header('Content-ID', '<send_image>')
msg.attach(msgImage)
#ssl登录
smtp = SMTP_SSL(host_server)
#set_debuglevel()是用来调试的。参数值为1表示开启调试模式,参数值为0关闭调试模式
smtp.set_debuglevel(1)
smtp.ehlo(host_server)
smtp.login(sender_qq, pwd)
smtp.sendmail(sender_qq_mail, receiver, msg.as_string())
smtp.quit()执行上面代码后,登录接收邮件的邮件帐号,这里接收邮件的账号为:yiibai.com@gmail.com,登录 http://gmail.com 应该会看到有接收到邮件如下 -
Python多线程编程
同时运行多个线程类似于同时运行多个不同的程序,但具有以下好处 -
- 进程内的多个线程与主线程共享相同的数据空间,因此可以比单独的进程更容易地共享信息或彼此进行通信。
- 线程有时也被称为轻量级进程,它们不需要太多的内存开销; 它们比进程便宜。
线程有一个开始,执行顺序和终止。 它有一个指令指针,可以跟踪其上下文中当前运行的位置。
- 它可以被抢占(中断)。
- 当其他线程正在运行时,它可以临时保留(也称为睡眠) - 这称为让步。
有两种不同的线程 -
- 内核线程
- 用户线程
内核线程是操作系统的一部分,而用户空间线程未在内核中实现。
有两个模块用于支持在Python 3中使用线程 -
- _thread
- threading
thread模块已被“不推荐”了很长一段时间。 鼓励用户使用threading模块。 因此,在Python 3中,thread模块不再可用。 但是,thread模块已被重命名为“_thread”,用于Python 3中的向后兼容性。
1.启动新线程
要产生/启动一个线程,需要调用thread模块中的以下方法 -
_thread.start_new_thread ( function, args[, kwargs] )这种方法调用可以快速有效地在Linux和Windows中创建新的线程。
方法调用立即返回,子线程启动并使用传递的args列表调用函数。当函数返回时,线程终止。
在这里,args是一个元组的参数; 使用空的元组来调用函数表示不传递任何参数。 kwargs是关键字参数的可选字典。
示例
#!/usr/bin/python3
import _thread
import time
# Define a function for the thread
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# Create two threads as follows
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: unable to start thread")
while 1:
pass当执行上述代码时,会产生以下结果 -
Thread-1: Tue Jun 26 22:58:32 2018
Thread-2: Tue Jun 26 22:58:34 2018
Thread-1: Tue Jun 26 22:58:34 2018
Thread-1: Tue Jun 26 22:58:36 2018
Thread-2: Tue Jun 26 22:58:38 2018
Thread-1: Tue Jun 26 22:58:38 2018
Thread-1: Tue Jun 26 22:58:40 2018
Thread-2: Tue Jun 26 22:58:42 2018
Thread-2: Tue Jun 26 22:58:46 2018
Thread-2: Tue Jun 26 22:58:50 2018
程序进入无限循环,可通过按ctrl-c停止或退出。虽然它对于低级线程非常有效,但与较新的线程模块相比,thread模块非常有限。
2. threading模块
Python 2.4中包含的较新的线程模块为线程提供了比上面讨论的线程模块更强大的高级支持。
线程模块公开了线程模块的所有方法,并提供了一些其他方法 -
- threading.activeCount() - 返回活动的线程对象的数量。
- threading.currentThread() - 返回调用者线程控件中线程对象的数量。
- threading.enumerate() - 返回当前处于活动状态的所有线程对象的列表。
除了这些方法之外,threading模块还有实现线程的Thread类。 Thread类提供的方法如下:
- run() - run()方法是线程的入口点。
- start() - start()方法通过调用run()方法启动一个线程。
- join([time]) - join()等待线程终止。
- isAlive() - isAlive()方法检查线程是否仍在执行。
- getName() - getName()方法返回一个线程的名称。
- setName() - setName()方法设置线程的名称。
3.使用threading模块创建线程
要使用threading模块实现新线程,必须执行以下操作:
- 定义Thread类的新子类。
- 覆盖init (self [,args])方法添加其他参数。
- 然后,重写run(self [,args])方法来实现线程在启动时应该执行的操作。
当创建了新的Thread的子类之后,就可以创建一个实例,然后调用start()方法来调用run()方法来启动一个新的线程。
示例
#!/usr/bin/python3
import threading
import time
exitFlag = 0
class MyThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Starting " + self.name)
print_time(self.name, self.counter, 5)
print ("Exiting " + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# Create new threads
thread1 = MyThread(1, "Thread-1", 1)
thread2 = MyThread(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("Exiting Main Thread")当运行上述程序时,它会产生以下结果 -
Starting Thread-1Starting Thread-2
Thread-1: Tue Jun 26 23:02:37 2018
Thread-2: Tue Jun 26 23:02:38 2018Thread-1: Tue Jun 26 23:02:38 2018
Thread-1: Tue Jun 26 23:02:39 2018
Thread-2: Tue Jun 26 23:02:40 2018Thread-1: Tue Jun 26 23:02:40 2018
Thread-1: Tue Jun 26 23:02:41 2018
Exiting Thread-1
Thread-2: Tue Jun 26 23:02:42 2018
Thread-2: Tue Jun 26 23:02:44 2018
Thread-2: Tue Jun 26 23:02:46 2018
Exiting Thread-2
Exiting Main Thread
>>> 4.同步线程
Python提供的threading模块包括一个简单易用的锁定机制,允许同步线程。 通过调用lock()方法创建一个新的锁,该方法返回新的锁。
新锁对象的acquire(blocking)方法用于强制线程同步运行。可选的blocking参数能够控制线程是否要等待获取锁定。
如果blocking设置为0,则如果无法获取锁定,则线程将立即返回0值,如果锁定已获取,则线程返回1。 如果blocking设置为1,则线程将blocking并等待锁定被释放。
新的锁定对象的release()方法用于在不再需要锁定时释放锁。
示例
#!/usr/bin/python3
# save file : MyThread2.py
import threading
import time
class MyThread2 (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Starting " + self.name)
# Get lock to synchronize threads
threadLock.acquire()
print_time(self.name, self.counter, 3)
# Free lock to release next thread
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# Create new threads
thread1 = MyThread2(1, "Thread-1", 1)
thread2 = MyThread2(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
# Add threads to thread list
threads.append(thread1)
threads.append(thread2)
# Wait for all threads to complete
for t in threads:
t.join()
print ("Exiting Main Thread")Python
当执行上述代码时,会产生以下结果 -
Starting Thread-1Starting Thread-2
Thread-1: Tue Jun 26 23:08:26 2018
Thread-1: Tue Jun 26 23:08:27 2018
Thread-1: Tue Jun 26 23:08:28 2018
Thread-2: Tue Jun 26 23:08:30 2018
Thread-2: Tue Jun 26 23:08:32 2018
Thread-2: Tue Jun 26 23:08:34 2018
Exiting Main Thread
>>> 5.多线程优先级队列
queue模块允许创建一个新的队列对象,可以容纳特定数量的项目。 有以下方法来控制队列 -
- get() - get()从队列中删除并返回一个项目。
- put() - put()将项添加到队列中。
- qsize() - qsize()返回当前队列中的项目数。
- empty() - 如果队列为空,则empty()方法返回True; 否则返回False。
- full() - 如果队列已满,则full()方法返回True; 否则返回False。
示例
#!/usr/bin/python3
#coding=utf-8
import queue
import threading
import time
exitFlag = 0
class MyQueue (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print ("Starting " + self.name)
process_data(self.name, self.q)
print ("Exiting " + self.name)
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print ("%s processing %s" % (threadName, data))
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = queue.Queue(10)
threads = []
threadID = 1
# Create new threads
for tName in threadList:
thread = MyQueue(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# Fill the queue
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# Wait for queue to empty
while not workQueue.empty():
pass
# Notify threads it's time to exit
exitFlag = 1
# Wait for all threads to complete
for t in threads:
t.join()
print ("Exiting Main Thread")当执行上述代码时,会产生以下结果 -
Starting Thread-1
Starting Thread-2
Starting Thread-3
Thread-3 processing One
Thread-3 processing Two
Thread-3 processing Three
Thread-3 processing Four
Thread-3 processing Five
Exiting Thread-1
Exiting Thread-2
Exiting Thread-3
Exiting Main ThreadPython XML解析和处理
XML是一种便携式的开源语言,允许程序员开发可由其他应用程序读取的应用程序,而不管操作系统和/或开发语言是什么。
1.什么是XML?
可扩展标记语言(XML)是一种非常像HTML或SGML的标记语言。 这是由万维网联盟推荐的,可以作为开放标准。
XML对于存储小到中等数量的数据非常有用,而不需要使用SQL。
2.XML解析器体系结构和API
Python标准库提供了一组极少使用但有用的接口来处理XML。两个最基本和最广泛使用在XML数据的API是SAX和DOM接口。
- 简单XML API(SAX) - 在这里,注册感兴趣的事件回调,然后让解析器继续执行文档。
当文档较大或存在内存限制时,此功能非常有用,它会从文件读取文件时解析文件,并且整个文件不会存储在内存中。 - 文档对象模型(DOM)API -
这是一个万维网联盟的推荐,它将整个文件读入存储器并以分层(基于树)的形式存储,以表示XML文档的所有功能。
当处理大文件时,SAX显然无法与DOM一样快地处理信息。 另一方面,使用DOM专门可以真正地占用资源,特别是如果要加许多文件使用的时候。
SAX是只读的,而DOM允许更改XML文件。由于这两种不同的API相辅相成,在大型项目中一般根据需要使用它们。
对于我们所有的XML代码示例,使用一个简单的XML文件:movies.xml作为输入 -
<collection shelf = "New Arrivals">
<movie title = "Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2013</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title = "Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title = "Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title = "Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
</collection>3.使用SAX API解析XML
SAX是事件驱动的XML解析的标准接口。 使用SAX解析XML通常需要通过子类化xml.sax.ContentHandler来创建自己的ContentHandler。
ContentHandler处理XML样式/风格的特定标签和属性。 ContentHandler对象提供了处理各种解析事件的方法。它拥有的解析器在解析XML文件时调用ContentHandler方法。
在XML文件的开头和结尾分别调用:startDocument和endDocument方法。 characters(text)方法通过参数text传递XML文件的字符数据。
ContentHandler在每个元素的开头和结尾被调用。如果解析器不在命名空间模式下,则调用startElement(tag,attributes)和endElement(tag)方法; 否则,调用相应的方法startElementNS和endElementNS方法。 这里,tag是元素标签,属性是Attributes对象。
以下是继续前面了解的其他重要方法 -
make_parser()方法
以下方法创建一个新的解析器对象并返回它。创建的解析器对象将是系统查找的第一个解析器类型。
xml.sax.make_parser( [parser_list] )以下是参数的详细信息 -
- parser_list - 可选参数,由使用哪个解析器的列表组成,必须全部实现make_parser方法。
parse()方法
以下方法创建一个SAX解析器并使用它来解析文档。
xml.sax.parse( xmlfile, contenthandler[, errorhandler])以下是参数的详细信息 -
- xmlfile - 这是要读取的XML文件的名称。
- contenthandler - 这必须是ContentHandler对象。
- errorhandler - 如果指定,errorhandler必须是SAX ErrorHandler
parseString方法
还有一种方法来创建SAX解析器并解析指定的XML字符串。
xml.sax.parseString(xmlstring, contenthandler[, errorhandler])以下是参数的详细信息 -
- xmlstring - 这是要读取的XML字符串的名称。
- contenthandler - 这必须是ContentHandler对象。
- errorhandler - 如果指定,errorhandler必须是SAX ErrorHandler对象。
示例
#!/usr/bin/python3
import xml.sax
class MovieHandler( xml.sax.ContentHandler ):
def __init__(self):
self.CurrentData = ""
self.type = ""
self.format = ""
self.year = ""
self.rating = ""
self.stars = ""
self.description = ""
# Call when an element starts
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "movie":
print ("*****Movie*****")
title = attributes["title"]
print ("Title:", title)
# Call when an elements ends
def endElement(self, tag):
if self.CurrentData == "type":
print ("Type:", self.type)
elif self.CurrentData == "format":
print ("Format:", self.format)
elif self.CurrentData == "year":
print ("Year:", self.year)
elif self.CurrentData == "rating":
print ("Rating:", self.rating)
elif self.CurrentData == "stars":
print ("Stars:", self.stars)
elif self.CurrentData == "description":
print ("Description:", self.description)
self.CurrentData = ""
# Call when a character is read
def characters(self, content):
if self.CurrentData == "type":
self.type = content
elif self.CurrentData == "format":
self.format = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "rating":
self.rating = content
elif self.CurrentData == "stars":
self.stars = content
elif self.CurrentData == "description":
self.description = content
if ( __name__ == "__main__"):
# create an XMLReader
parser = xml.sax.make_parser()
# turn off namepsaces
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# override the default ContextHandler
Handler = MovieHandler()
parser.setContentHandler( Handler )
parser.parse("movies.xml")这将产生以下结果 -
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Year: 2003
Rating: PG
Stars: 10
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Year: 1989
Rating: R
Stars: 8
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Stars: 10
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Stars: 2
Description: Viewable boredom有关SAX API文档的完整详细信息,请参阅标准Python SAX API。
使用DOM API解析XML
文档对象模型(“DOM”)是来自万维网联盟(W3C)的跨语言API,用于访问和修改XML文档。
DOM对于随机访问应用非常有用。SAX只允许您一次查看文档的一部分。如果想要查看一个SAX元素,则无法访问另一个。
以下是快速加载XML文档并使用xml.dom模块创建minidom对象的最简单方法。 minidom对象提供了一个简单的解析器方法,可以从XML文件快速创建一个DOM树。
示例调用minidom对象的parse(file [,parser])函数来解析由文件指定为DOM树对象的XML文件。
示例
#!/usr/bin/python3
from xml.dom.minidom import parse
import xml.dom.minidom
# Open XML document using minidom parser
DOMTree = xml.dom.minidom.parse("movies.xml")
collection = DOMTree.documentElement
if collection.hasAttribute("shelf"):
print ("Root element : %s" % collection.getAttribute("shelf"))
# Get all the movies in the collection
movies = collection.getElementsByTagName("movie")
# Print detail of each movie.
for movie in movies:
print ("*****Movie*****")
if movie.hasAttribute("title"):
print ("Title: %s" % movie.getAttribute("title"))
type = movie.getElementsByTagName('type')[0]
print ("Type: %s" % type.childNodes[0].data)
format = movie.getElementsByTagName('format')[0]
print ("Format: %s" % format.childNodes[0].data)
rating = movie.getElementsByTagName('rating')[0]
print ("Rating: %s" % rating.childNodes[0].data)
description = movie.getElementsByTagName('description')[0]
print ("Description: %s" % description.childNodes[0].data)这将产生以下结果 -
Root element : New Arrivals
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Rating: PG
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Rating: R
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Description: Viewable boredom有关DOM API文档的完整详细信息,请参阅标准Python DOM API。
Python文件对象方法
使用open()函数创建一个文件对象,这里是可以在这个对象上调用的函数的列表 -
| 编号 | 方法名称 | 描述 |
|---|---|---|
| 1 | file.close() | 关闭文件,无法读取或写入关闭的文件。 |
| 2 | file.flush() | 清空内部缓冲区,类似于stdio的fflush。 |
| 3 | file.fileno() | 返回底层实现使用的整数文件描述符,以从操作系统请求I/O操作。 |
| 4 | file.isatty() | 如果文件连接到tty(-like)设备,则返回True,否则返回False。 |
| 5 | next(file) | 每次调用时返回文件的下一行。 |
| 6 | file.read([size]) | 从文件中读取最多为size个字节(如果在获取size字节之前读取命中EOF,则读取更少字节的数据)。 |
| 7 | file.readline([size]) | 从文件中读取一行,字符串中保留一个尾随的换行字符。 |
| 8 | file.readlines([sizehint]) | 使用readline()读取并返回一个包含行的列表直到EOF。 如果可选的sizehint参数存在,而不是读取到EOF,则读取总共大约为sizehint字节的字符串(可能在舍入到内部缓冲区大小之后)的整行。 |
| 9 | file.seek(offset[, whence]) | 设置文件的当前位置 |
| 10 | file.tell() | 返回文件的当前位置 |
| 11 | file.truncate([size]) | 截断文件大小。如果可选的size参数存在,则该文件将被截断为size(最多)大小。 |
| 12 | file.write(str) | 将一个字符串写入文件,无返回值。 |
| 13 | file.writelines(sequence) | 将一串字符串写入文件。 该序列可以是生成字符串的任何可迭代对象,通常是字符串列表。 |
Python os模块方法
os模块提供了大量有用的方法来处理文件和目录。本章节中的代码实例是在 Ubuntu Linux系统上运行来演示。
大多数有用的方法都列在这里 -
| 编号 | 方法 | 描述/说明 |
|---|---|---|
| 1 | os.access(path, mode) | 使用真正的uid/gid来测试访问指定的路径。 |
| 2 | os.chdir(path) | 将当前工作目录更改为指定路径。 |
| 3 | os.chflags(path, flags) | 将指定的路径的标志设置为数字标志。 |
| 4 | os.chmod(path, mode) | 将路径模式更改为数字模式。 |
| 5 | os.chown(path, uid, gid) | 将指定的路径的所有者和组ID更改为数字uid和gid。 |
| 6 | os.chroot(path) | 将当前进程的根目录更改为指定的路径。 |
| 7 | os.close(fd) | 关闭文件描述符fd。 |
| 8 | os.closerange(fd_low, fd_high) | 将所有从fd_low(包括)到fd_high(不包括)的文件描述符关闭,并忽略错误。 |
| 9 | os.dup(fd) | 返回文件描述符fd的副本。 |
| 10 | os.dup2(fd, fd2) | 重复从fd到fd2的文件描述符,如果需要,首先关闭fd2。 |
| 11 | os.fchdir(fd) | 将当前工作目录更改为由文件描述符fd表示的目录。 |
| 12 | os.fchmod(fd, mode) | 将fd给出的文件的模式mode更改为数字模式。 |
| 13 | os.fchown(fd, uid, gid) 将由fd提供的文件的所有者和组ID更改为数字uid和gid。 | |
| 14 | os.fdatasync(fd) | 强制将文件描述符fd写入磁盘。 |
| 15 | os.fdopen(fd[, mode[, bufsize]]) | 返回连接到文件描述符fd的打开的文件对象。 |
| 16 | os.fpathconf(fd, name) | 返回与打开文件相关的系统配置信息。 name指定要检索的配置值。 |
| 17 | os.fstat(fd) | 返回文件描述符fd的状态,如stat()。 |
| 18 | os.fstatvfs(fd) | 返回有关包含与文件描述符fd相关联的文件的文件系统的信息,如statvfs()。 |
| 19 | os.fsync(fd) | 强制将文件写入与文件描述符fd相关联的磁盘。 |
| 20 | os.ftruncate(fd, length) | 截断与文件描述符fd相对应的文件,使其大小最大为字节。 |
| 21 | os.getcwd() | 返回一个表示当前工作目录的字符串。 |
| 22 | os.getcwdu() | 返回表示当前工作目录的Unicode对象。 |
| 23 | os.isatty(fd) | 如果文件描述符fd打开并连接到tty(-like)设备,则返回True,否则返回False。 |
| 24 | os.lchflags(path, flags) | 将路径(path)的标志设置为数字标志,如chflags(),但不要跟随符号链接。 |
| 25 | os.lchmod(path, mode) | 将路径模式更改为数字模式。 |
| 26 | os.lchown(path, uid, gid) | 将路径的所有者和组ID更改为数字uid和gid。此功能不会遵循符号链接。 |
| 27 | os.link(src, dst) | 创建一个指向src名为dst的硬链接。 |
| 28 | os.listdir(path) | 返回一个列表,其中包含由path指定的目录中的条目的名称。 |
| 29 | os.lseek(fd, pos, how) | 将文件描述符fd的当前位置设置为位置pos,由how指定如何修改。 |
| 30 | os.lstat(path) | 类似于stat(),但不遵循符号链接。 |
| 31 | os.major(device) | 从原始设备号中提取设备主体号码。 |
| 32 | os.makedev(major, minor) | 从主要和次要设备编号构成原始设备编号。 |
| 33 | os.makedirs(path[, mode]) | 递归目录创建函数。 |
| 34 | os.minor(device) | 从原始设备号中提取设备次要号码。 |
| 35 | os.mkdir(path[, mode]) | 以数字模式mode创建名为path的目录。 |
| 36 | os.mkfifo(path[, mode]) | 以数字模式模式创建名为path的FIFO(命名管道)。 默认模式为0666(八进制)。 |
| 37 | os.mknod(filename[, mode = 0600, device]) 创建名为filename的文件系统节点(文件,设备专用文件或命名管道)。 | |
| 38 | os.open(file, flags[, mode]) | 打开文件文件,并根据标志和可能的模式根据模式设置各种标志。 |
| 39 | os.openpty() | 打开一个新的伪终端对。分别为pty和tty返回一对文件描述符(主,从)。 |
| 40 | os.pathconf(path, name) | 返回与命名文件相关的系统配置信息。 |
| 41 | os.pipe() | 创建一个管道。分别返回一对可用于阅读和写入的文件描述符(r,w)。 |
| 42 | os.popen(command[, mode[, bufsize]]) | 打开或从命令打开管道。 |
| 43 | os.read(fd, n) | 从文件描述符fd读取最多n个字节。 返回一个包含读取字节的字符串。 如果fd引用的文件的末尾已经到达,则返回一个空字符串。 |
| 44 | os.readlink(path) | 返回一个表示符号链接所指向的路径的字符串。 |
| 45 | os.remove(path) | 删除文件路径。 |
| 46 | os.removedirs(path) | 递归删除目录。 |
| 47 | os.rename(src, dst) | 将文件或目录src重命名为dst。 |
| 48 | os.renames(old, new) | 递归目录或文件重命名功能。 |
| 49 | os.rmdir(path) | 删除目录路径 |
| 50 | os.stat(path) | 在给定的路径上执行stat系统调用。 |
| 51 | os.stat_float_times([newvalue]) | 确定stat_result是否将时间戳表示为浮点对象。 |
| 52 | os.statvfs(path) | 在给定路径上执行statvfs系统调用。 |
| 53 | os.symlink(src, dst) | 创建一个指向src的符号链接,命名为dst。 |
| 54 | os.tcgetpgrp(fd) | 返回与fd(由open()返回的打开的文件描述符)给出的终端关联的进程组。 |
| 55 | os.tcsetpgrp(fd, pg) | 将与fd(open()返回的打开的文件描述符)给定的终端相关联的进程组pg。 |
| 56 | os.tempnam([dir[, prefix]]) | 返回创建临时文件的唯一路径名。 |
| 57 | os.tmpfile() | 返回以更新模式打开的新文件对象(w+b)。 |
| 58 | os.tmpnam() | 返回创建临时文件的唯一路径名。 |
| 59 | os.ttyname(fd) | 返回指定与文件描述符fd相关联的终端设备的字符串。 如果fd与终端设备没有关联,则会出现异常。 |
| 60 | os.unlink(path) | 删除文件路径。 |
| 61 | os.utime(path, times) | 设置由path指定的文件的访问和修改时间。 |
| 62 | os.walk(top[, topdown = True[, onerror = None[, followlinks = False]]]) | 通过自上而下或自下而上地遍历树来生成目录树中的文件名。 |
| 63 | os.write(fd, str) | 将字符串str写入文件描述符fd。 返回实际写入的字节数。 |
Python迭代器
迭代器是可以迭代的对象。 在本教程中,您将了解迭代器的工作原理,以及如何使用iter和next方法构建自己的迭代器。
迭代器在Python中无处不在。 它们优雅地实现在循环,推导,生成器等中,但隐藏在明显的视觉中。
Python中的迭代器只是一个可以迭代的对象。一个将一次返回数据的对象或一个元素。
从技术上讲,Python迭代器对象必须实现两个特殊的方法iter()和next(),统称为迭代器协议。
如果我们从中获取一个迭代器,那么一个对象被称为iterable。 大多数Python中的内置容器是列表,元组,字符串等都是可迭代的。
iter()函数(这又调用iter()方法)返回一个迭代器。
通过Python中的迭代器迭代
使用next()函数来手动遍历迭代器的所有项目。当到达结束,没有更多的数据要返回时,它将会引发StopIteration。 以下是一个例子。
# define a list
my_list = [4, 7, 0, 3]
# get an iterator using iter()
my_iter = iter(my_list)
## iterate through it using next()
#prints 4
print(next(my_iter))
#prints 7
print(next(my_iter))
## next(obj) is same as obj.__next__()
#prints 0
print(my_iter.__next__())
#prints 3
print(my_iter.__next__())
## This will raise error, no items left
next(my_iter)更优雅的自动迭代方式是使用for循环。 使用for循环可以迭代任何可以返回迭代器的对象,例如列表,字符串,文件等。
>>> for element in my_list:
... print(element)
...
4
7
0
3循环如何实际工作?
在上面的例子中看到的,for循环能够自动通过列表迭代。
事实上,for循环可以迭代任何可迭代对象。我们来仔细看一下在Python中是如何实现for循环的。
for element in iterable:
# do something with element实际上它是以类似下面的方式来实现的 -
# create an iterator object from that iterable
iter_obj = iter(iterable)
# infinite loop
while True:
try:
# get the next item
element = next(iter_obj)
# do something with element
except StopIteration:
# if StopIteration is raised, break from loop
break所以在for的内部,for循环通过在可迭代的对象上调用iter()来创建一个迭代器对象iter_obj。
有意思的是,这个for循环实际上是一个无限循环~..~。
在循环中,它调用next()来获取下一个元素,并使用该值执行for循环的主体。 在所有对象耗尽后,引发StopIteration异常,内部被捕获从而结束循环。请注意,任何其他类型的异常都将正常通过。
在Python中构建自己的Iterator
构建迭代器在Python中很容易。只需要实现iter()和next()方法。
iter()方法返回迭代器对象本身。如果需要,可以执行一些初始化。
next()方法必须返回序列中的下一个项目(数据对象)。 在到达结束后,并在随后的调用中它必须引发StopIteration异常。
在这里,我们展示一个例子,在每次迭代中给出下一个2的几次方。 次幂指数从零开始到用户设定的数字。
class PowTwo:
"""Class to implement an iterator
of powers of two"""
def __init__(self, max = 0):
self.max = max
def __iter__(self):
self.n = 0
return self
def __next__(self):
if self.n <= self.max:
result = 2 ** self.n
self.n += 1
return result
else:
raise StopIteration现在可以创建一个迭代器,并通过它迭代如下 -
>>> a = PowTwo(4)
>>> i = iter(a)
>>> next(i)
1
>>> next(i)
2
>>> next(i)
4
>>> next(i)
8
>>> next(i)
16
>>> next(i)
Traceback (most recent call last):
StopIteration也可以使用for循环迭代那些迭代器类。
>>> for i in PowTwo(5):
... print(i)
...
1
2
4
8
16
32Python无限迭代器
迭代器对象中的项目不必都是可耗尽的,可以是无限迭代器(永远不会结束)。 处理这样的迭代器时一定要小心。
下面是用来演示无限迭代器的一个简单的例子。
内置的函数iter()可以用两个参数来调用,其中第一个参数必须是可调用对象(函数),而第二个参数是标头。迭代器调用此函数,直到返回的值等于指定值。
>>> int()
0
>>> inf = iter(int,1)
>>> next(inf)
0
>>> next(inf)
0可以看到,int()函数总是返回0,所以将它作为iter(int,1)传递将返回一个调用int()的迭代器,直到返回值等于1。这从来没有发生,所以这样就得到一个无限迭代器。
我们也可以建立自己的无限迭代器。 以下迭代器理论上将返回所有奇数。
class InfIter:
"""Infinite iterator to return all
odd numbers"""
def __iter__(self):
self.num = 1
return self
def __next__(self):
num = self.num
self.num += 2
return num示例运行如下 -
>>> a = iter(InfIter())
>>> next(a)
1
>>> next(a)
3
>>> next(a)
5
>>> next(a)
7当迭代这些类型的无限迭代器时,请注意指定终止条件。
使用迭代器的优点是它们可以节省资源。 如上所示,我们可以获得所有奇数,而不将整个系统存储在内存中。理论上,可以在有限的内存中计算有无限的项目。
Python生成器
在本文中,将学习如何使用Python生成器来创建迭代,了解它与迭代器和常规函数有什么区别,以及为什么要使用它。
在Python中构建迭代器有很多开销; 必须使用iter()和next()方法实现一个类,跟踪内部状态,当没有值被返回时引发StopIteration异常。
Python生成器是创建迭代器的简单方法。上面提到的所有开销都由Python中的生成器自动处理。
简单来说,生成器是返回一个可以迭代的对象(迭代器)的函数(一次一个值)。
如何在Python中创建生成器?
在Python中创建生成器是相当简单的。 它使用yield语句而不是return语句来定义,与正常函数一样简单。
如果函数包含至少一个yield语句(它可能包含其他yield或return语句),那么它将成为一个生成器函数。 yield和return都将从函数返回一些值。
不同的是,return语句完全终止函数,但yield语句会暂停函数保存其所有状态,并在以后的连续调用中继续执行(有点像线程挂起的意思)。
生成器函数与正常函数的差异
下面列出的是生成器函数与正常函数的区别 -
- 生成器函数包含一个或多个yield语句。
- 当被调用时,它返回一个对象(迭代器),但不会立即开始执行。
- iter()和next()之类的方法将自动实现。所以可以使用next()迭代项目。
- 一旦函数退让(yields),该函数将被暂停,并将该控制权交给调用者。
- 局部变量及其状态在连续调用之间被记住。
- 最后,当函数终止时,StopIteration会在进一步的调用时自动引发。
下面的例子用来说明上述所有要点。 我们有一个名为my_gen()的生成器函数和几个yield语句。
#!/usr/bin/python3
#coding=utf-8
def my_gen():
n = 1
print('This is printed first, n= ', n)
# Generator function contains yield statements
yield n
n += 1
print('This is printed second, n= ', n)
yield n
n += 1
print('This is printed at last, n= ', n)
yield n下面给出了交互式运行结果。 在Python shell中运行它们以查看输出 -
>>> # It returns an object but does not start execution immediately.
>>> a = my_gen()
>>> # We can iterate through the items using next().
>>> next(a)
This is printed first, n = 1
1
>>> # Once the function yields, the function is paused and the control is transferred to the caller.
>>> # Local variables and theirs states are remembered between successive calls.
>>> next(a)
This is printed second, n = 2
2
>>> next(a)
This is printed at last, n = 3
3
>>> # Finally, when the function terminates, StopIteration is raised automatically on further calls.
>>> next(a)
Traceback (most recent call last):
...
StopIteration
>>> next(a)
Traceback (most recent call last):
...
StopIteration在上面的例子中需要注意的是,在每个调用之间函数会保持住变量n的值。
与正常函数不同,当函数产生时,局部变量不会被销毁。 此外,生成器对象只能重复一次。
要重新启动该过程,需要使用类似于a = my_gen()的方法创建另一个生成器对象。
注意:最后要注意的是,可以直接使用带有for循环的生成器。
这是因为,for循环需要一个迭代器,并使用next()函数进行迭代。 当StopIteration被引发时,它会自动结束。 请查看这里了解一个for循环是如何在Python中实际实现的。
# A simple generator function
def my_gen():
n = 1
print('This is printed first')
# Generator function contains yield statements
yield n
n += 1
print('This is printed second')
yield n
n += 1
print('This is printed at last')
yield n
# Using for loop
for item in my_gen():
print(item)当运行程序时,将输出结果为:
This is printed first
1
This is printed second
2
This is printed at last
3具有循环的Python生成器
上面的例子没有什么用,我们研究它只是为了了解在后台发生了什么。通常,生成器功能用具有适当终止条件的循环实现。
我们举一个反转字符串的生成器的例子 -
length = len(my_str)
for i in range(length - 1,-1,-1):
yield my_str[i]
# For loop to reverse the string
# Output:
# o
# l
# l
# e
# h
for char in rev_str("hello"):
print(char)def rev_str(my_str):在这个例子中,使用range()函数使用for循环以相反的顺序获取索引。事实证明,这个生成函数不仅可以使用字符串,还可以使用其他类型的列表,元组等迭代。
Python生成器表达式
使用生成器表达式,可以轻松创建简单的生成器。 它使构建生成器变得容易。
与lambda函数一样创建一个匿名函数,生成器表达式创建一个匿名生成函数。生成器表达式的语法与Python中的列表解析类似。 但方圆[]替换为圆括号()。
列表推导和生成器表达式之间的主要区别是:列表推导产生整个列表,生成器表达式一次生成一个项目。
它们是处理方式是懒惰的,只有在被要求时才能生产项目。 因此,生成器表达式的存储器效率高于等效列表的值。
# Initialize the list
my_list = [1, 3, 6, 10]
# square each term using list comprehension
# Output: [1, 9, 36, 100]
[x**2 for x in my_list]
# same thing can be done using generator expression
# Output: <generator object <genexpr> at 0x0000000002EBDAF8>
(x**2 for x in my_list)我们可以看到,生成器表达式没有立即生成所需的结果。 相反,它返回一个发生器对象,并根据需要生成项目。
# Intialize the list
my_list = [1, 3, 6, 10]
a = (x**2 for x in my_list)
# Output: 1
print(next(a))
# Output: 9
print(next(a))
# Output: 36
print(next(a))
# Output: 100
print(next(a))
# Output: StopIteration
next(a)生成器表达式可以在函数内部使用。当以这种方式使用时,圆括号可以丢弃。
>>> sum(x**2 for x in my_list)
146
>>> max(x**2 for x in my_list)
100为什么在Python中使用生成器?
有几个原因使得生成器成为有吸引力。
- 容易实现
与其迭代器类相比,发生器可以以清晰简洁的方式实现。 以下是使用迭代器类来实现2的幂次序的例子。
class PowTwo:
def __init__(self, max = 0):
self.max = max
def __iter__(self):
self.n = 0
return self
def __next__(self):
if self.n > self.max:
raise StopIteration
result = 2 ** self.n
self.n += 1
return result上面代码有点长,可以使用一个生成器函数实现同样的功能。
def PowTwoGen(max = 0):
n = 0
while n < max:
yield 2 ** n
n += 1因为,生成器自动跟踪的细节,它更简洁,更干净。
2.内存高效
返回序列的正常函数将在返回结果之前会在内存中的创建整个序列。如果序列中的项目数量非常大,这可是要消耗内存的。
序列的生成器实现是内存友好的,并且是推荐使用的,因为它一次仅产生一个项目。
3. 表未无限流
生成器是表示无限数据流的绝佳媒介。 无限流不能存储在内存中,由于生成器一次只能生成一个项目,因此可以表示无限数据流。
以下示例可以生成所有偶数(至少在理论上)。
def all_even():
n = 0
while True:
yield n
n += 24.管道生成器
生成器可用于管理一系列操作,下面使用一个例子说明。
假设我们有一个快餐连锁店的日志文件。 日志文件有一列(第4列),用于跟踪每小时销售的比萨饼数量,我们想算出在5年内销售的总萨饼数量。
假设一切都是字符串,不可用的数字标记为“N / A”。 这样做的生成器实现可以如下。
with open('sells.log') as file:
pizza_col = (line[3] for line in file)
per_hour = (int(x) for x in pizza_col if x != 'N/A')
print("Total pizzas sold = ",sum(per_hour))Python闭包
嵌套函数中的非局部变量
在进入闭包之前,我们必须先了解一个嵌套函数和非局部变量。
在函数中定义另一个函数称为嵌套函数。嵌套函数可以访问包围范围内的变量。
在Python中,这些非局部变量只能在默认情况下读取,我们必须将它们显式地声明为非局部变量(使用nonlocal关键字)才能进行修改。
以下是访问非局部变量的嵌套函数的示例。
def print_msg(msg):
# This is the outer enclosing function
def printer():
# This is the nested function
print(msg)
printer()
# We execute the function
# Output: Hello
print_msg("Hello")可以看到嵌套函数printer()能够访问封闭函数的非局部变量msg。
定义闭包函数
在上面的例子中,如果函数print_msg()的最后一行返回printer()函数而不是调用它,会发生什么? 如该函数定义如下 -
def print_msg(msg):
# This is the outer enclosing function
def printer():
# This is the nested function
print(msg)
return printer # this got changed
# Now let's try calling this function.
# Output: Hello
another = print_msg("Hello")
another()这样是不寻常的。
print_msg()函数使用字符串“Hello”进行调用,返回的函数被绑定到另一个名称。 在调用another()时,尽管我们已经完成了print_msg()函数的执行,但仍然记住了这个消息。
一些数据(“Hello”)附加到代码中的这种技术在Python中称为闭包。
即使变量超出范围或函数本身从当前命名空间中删除,也会记住封闭范围内的值。
尝试在Python shell中运行以下内容以查看输出。
>>> del print_msg
>>> another()
Hello
>>> print_msg("Hello")
Traceback (most recent call last):
...
NameError: name 'print_msg' is not defined什么时候闭包?
从上面的例子可以看出,当嵌套函数引用其封闭范围内的值时,在Python中有使用了一个闭包。
在Python中创建闭包必须满足的标准将在以下几点 -
- 必须有一个嵌套函数(函数内部的函数)。
- 嵌套函数必须引用封闭函数中定义的值。
- 闭包函数必须返回嵌套函数。
何时使用闭包?
那么闭包是什么好的?
闭包可以避免使用全局值并提供某种形式的数据隐藏。它还可以提供面向对象的解决问题的解决方案。
当在类中几乎没有方法(大多数情况下是一种方法)时,闭包可以提供一个替代的和更优雅的解决方案。 但是当属性和方法的数量变大时,更好地实现一个类。
这是一个简单的例子,其中闭包可能比定义类和创建对象更为优先。
def make_multiplier_of(n):
def multiplier(x):
return x * n
return multiplier
# Multiplier of 3
times3 = make_multiplier_of(3)
# Multiplier of 5
times5 = make_multiplier_of(5)
# Output: 27
print(times3(9))
# Output: 15
print(times5(3))
# Output: 30
print(times5(times3(2)))Python中的装饰器也可以广泛使用闭包。值得注意的是,可以找到封闭函数中包含的值。
所有函数对象都有一个closure属性,如果它是一个闭包函数,它返回一个单元格对象的元组。 参考上面的例子,我们知道times3和times5是闭包函数。
>>> make_multiplier_of.__closure__
>>> times3.__closure__
(<cell at 0x0000000002D155B8: int object at 0x000000001E39B6E0>,)单元格(cell)对象具有存储闭合值的属性:cell_contents。
>>> times3.__closure__[0].cell_contents
3
>>> times5.__closure__[0].cell_contents
5Python修饰器
装饰器接收一个功能,添加一些功能并返回。 在本文中,您将学习如何创建装饰器,以及为什么要使用装饰器。
Python有一个有趣的功能,称为装饰器,以便为现有代码添加功能。
这也称为元编程,作为程序的一部分,尝试在编译时修改程序的另一部分。
学习装修器之前需要了解什么?
为了了解装饰器,我们首先在Python中了解一些基本的东西。
Python中的一切(是的,甚至是类)都是对象。 我们定义的名称只是绑定到这些对象的标识符。 函数也不例外,它们也是对象(带有属性)。 各种不同的名称可以绑定到同一个功能对象。
看看下面一个示例 -
def first(msg):
print(msg)
first("Hello")
second = first
second("Hello")当运行代码时,first和second函数都提供相同的输出。 这里名称first和second引用相同的函数对象。
函数可以作为参数传递给另一个函数。
如果您在Python中使用了map,filter和reduce等功能,那么您就了解了。
将其他函数作为参数的函数也称为高阶函数。下面是这样子的一个函数的例子。
def inc(x):
return x + 1
def dec(x):
return x - 1
def operate(func, x):
result = func(x)
return result我们调用函数如下 -
>>> operate(inc,3)
4
>>> operate(dec,3)
2此外,一个函数可以返回另一个函数。
def is_called():
def is_returned():
print("Hello")
return is_returned
new = is_called()
#Outputs "Hello"
new()这里,is_returned()是一个定义的嵌套函数,在每次调用is_called()时返回。
回到装饰器
实际上,实现特殊方法call()的任何对象都被称为可调用。 因此,在最基本的意义上,装饰器是可调用的,并且可以返回可调用。
基本上,装饰器接收一个函数,添加一些函数并返回。
def make_pretty(func):
def inner():
print("I got decorated")
func()
return inner
def ordinary():
print("I am ordinary")当在shell中运行以下代码时,如下 -
>>> ordinary()
I am ordinary
>>> # let's decorate this ordinary function
>>> pretty = make_pretty(ordinary)
>>> pretty()
I got decorated
I am ordinary在上面的例子中,make_pretty()是一个装饰器。 在分配步骤。
pretty = make_pretty(ordinary)函数ordinary()得到了装饰,返回函数的名字:pretty。
可以看到装饰函数为原始函数添加了一些新功能。这类似于包装礼物。 装饰器作为包装纸。 装饰物品的性质(里面的实际礼物)不会改变。 但现在看起来很漂亮(因为装饰了)。
一般来说,我们装饰一个函数并重新分配它,
ordinary = make_pretty(ordinary).这是一个常见的结构,Python有一个简化的语法。
可以使用@符号和装饰器函数的名称,并将其放在要装饰的函数的定义之上。 例如,
@make_pretty
def ordinary():
print("I am ordinary")上面代码相当于 -
def ordinary():
print("I am ordinary")
ordinary = make_pretty(ordinary)用参数装饰函数
上面的装饰器很简单,只适用于没有任何参数的函数。 如果有函数要接受如下的参数怎么办?
def divide(a, b):
return a/b该函数有两个参数a和b。 我们知道,如果将b的值设置为0并传递那么是会出错的。
>>> divide(2,5)
0.4
>>> divide(2,0)
Traceback (most recent call last):
...
ZeroDivisionError: division by zero现在使用一个装饰器来检查这个错误。
def smart_divide(func):
def inner(a,b):
print("I am going to divide",a,"and",b)
if b == 0:
print("Whoops! cannot divide")
return
return func(a,b)
return inner
@smart_divide
def divide(a,b):
return a/b如果发生错误,这个新的实现将返回None。
>>> divide(2,5)
I am going to divide 2 and 5
0.4
>>> divide(2,0)
I am going to divide 2 and 0
Whoops! cannot divide以这种方式就可以装饰函数的参数了。
应该会注意到,装饰器中嵌套的inner()函数的参数与其装饰的函数的参数是一样的。 考虑到这一点,现在可以让一般装饰器使用任何数量的参数。
在Python中,这个由function(* args,** kwargs)完成。 这样,args将是位置参数的元组,kwargs将是关键字参数的字典。这样的装饰器的例子将是。
def works_for_all(func):
def inner(*args, **kwargs):
print("I can decorate any function")
return func(*args, **kwargs)
return inner在Python中链接装饰器
多个装饰器可以在Python中链接。
这就是说,一个函数可以用不同(或相同)装饰器多次装饰。只需将装饰器放置在所需函数之上。
def star(func):
def inner(*args, **kwargs):
print("*" * 30)
func(*args, **kwargs)
print("*" * 30)
return inner
def percent(func):
def inner(*args, **kwargs):
print("%" * 30)
func(*args, **kwargs)
print("%" * 30)
return inner
@star
@percent
def printer(msg):
print(msg)
printer("Hello")Python
执行上面代码,将输出结果如下 -
******************************
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Hello
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
******************************以上语法,
@star
@percent
def printer(msg):
print(msg)相当于以下 -
def printer(msg):
print(msg)
printer = star(percent(printer))链装饰器的顺序是重要的。 所以如果把顺序颠倒了执行结果就不一样了,如下 -
@percent
@star
def printer(msg):
print(msg)执行上面代码,将输出结果如下 -
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
******************************
Hello
******************************
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
















 2845
2845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









